Downloaded 1,001 times




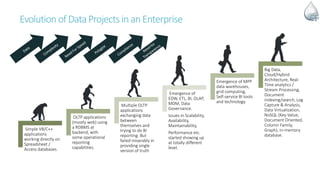
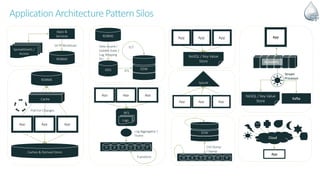
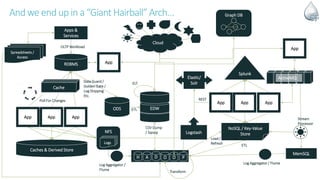





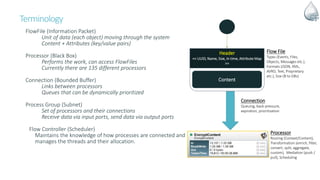




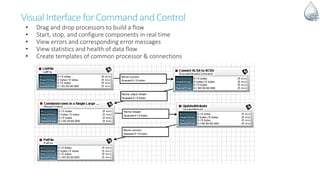



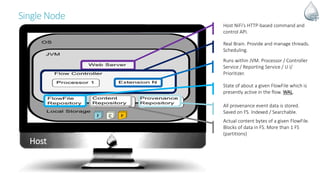

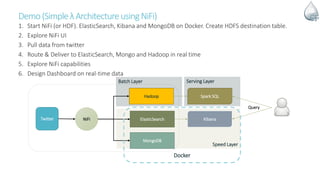
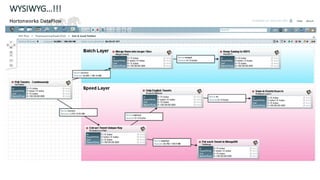






The document discusses Apache NiFi, a powerful data flow management tool designed for real-time data integration and processing challenges faced by enterprises. It highlights its core features, including guaranteed data delivery, a visual command interface, and extensibility, while also covering its architecture, historical development, and use cases in various scenarios. The text emphasizes the importance of NiFi in simplifying complex data workflows and ensuring reliable data handling across distributed systems.













































































