Downloaded 103 times






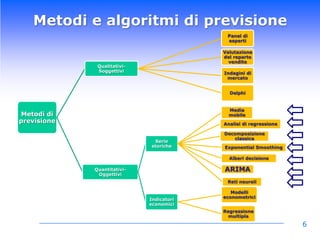



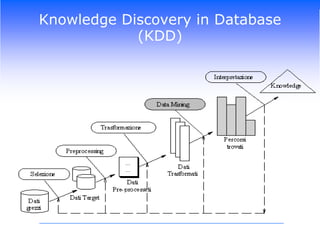


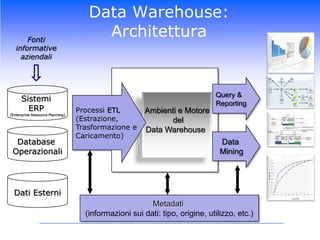
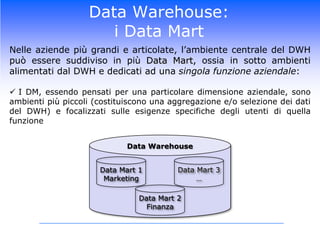

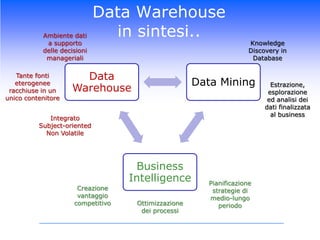


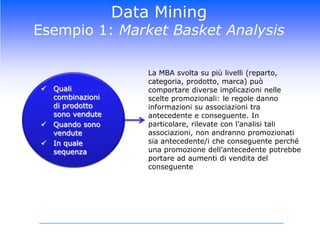
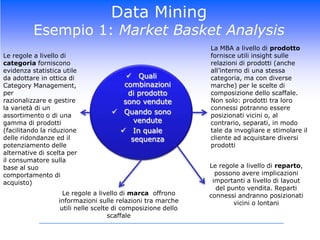



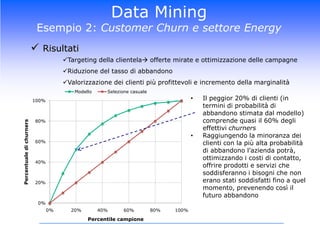

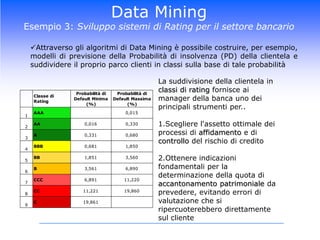

Il corso di Data Mining di Luca Molteni si focalizza sulle tecniche statistiche per risolvere problemi aziendali attraverso due moduli principali: previsioni delle vendite e Customer Relationship Management. Gli studenti apprenderanno diverse metodologie, inclusi algoritmi di classificazione e modelli predittivi, con un uso pratico di software come SPSS e Excel. Il documentario esplora anche l'importanza di avere un data warehouse per assicurare l'affidabilità dei dati utilizzati nelle analisi.











































































