Downloaded 318 times





























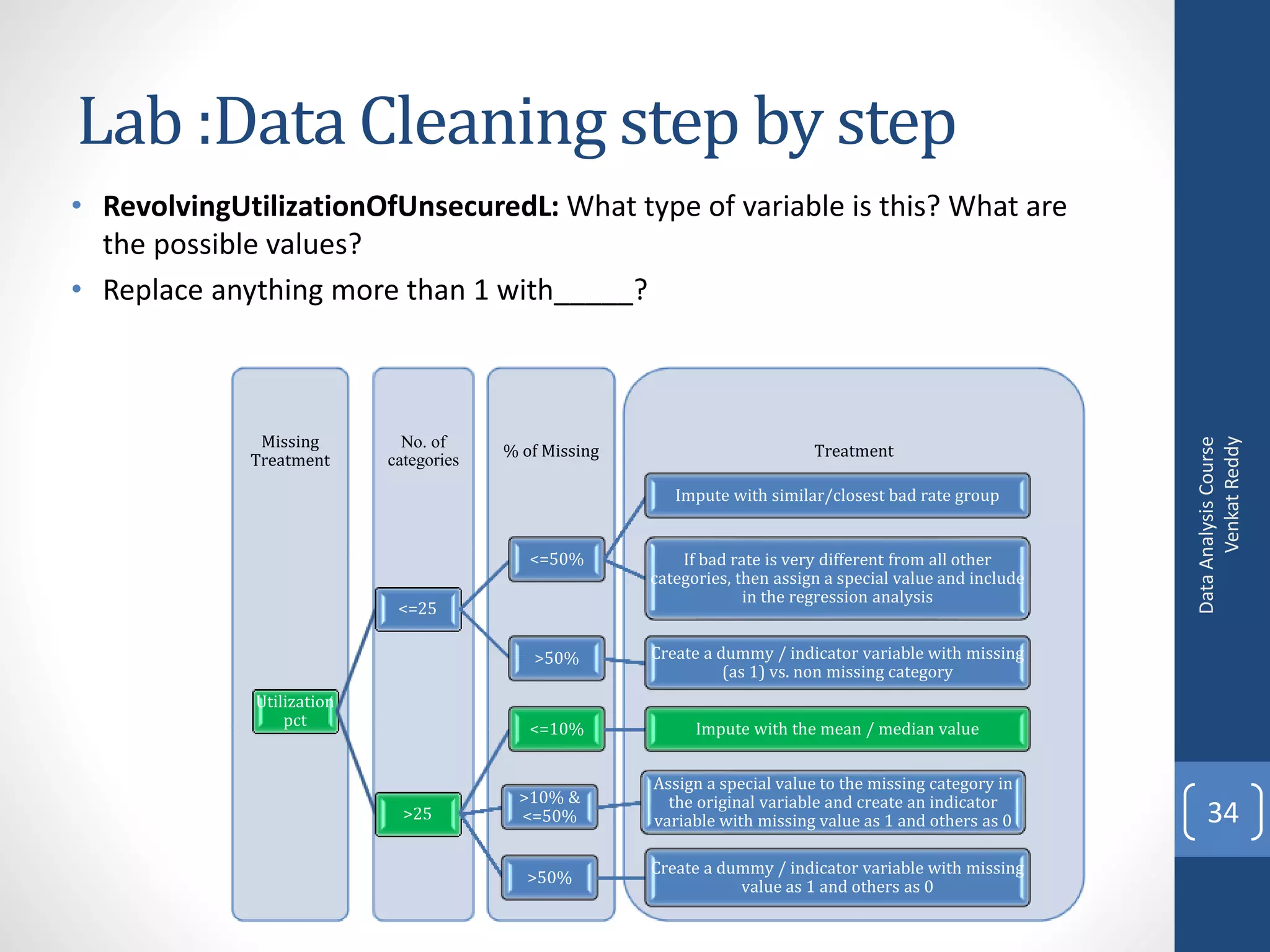
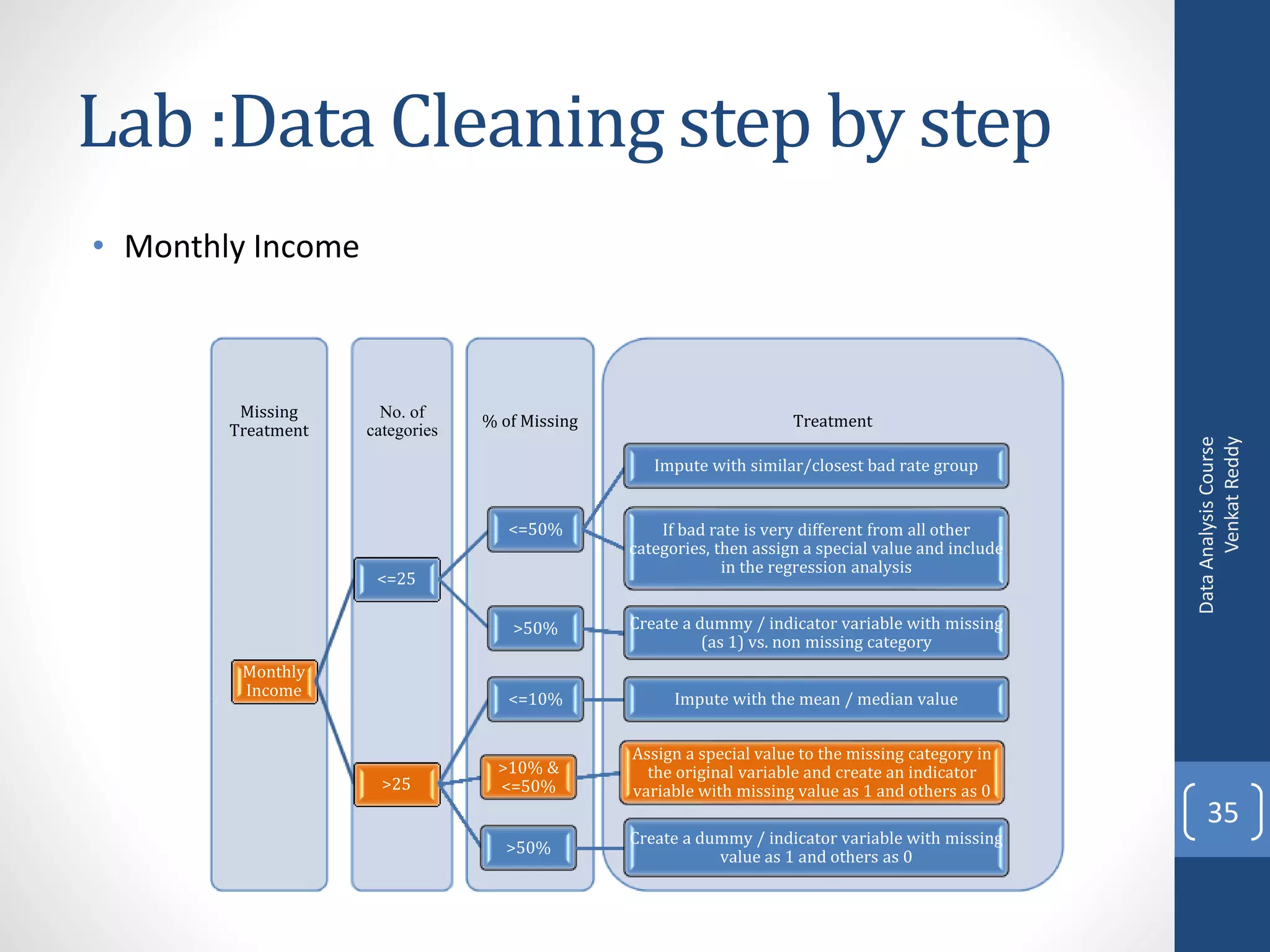

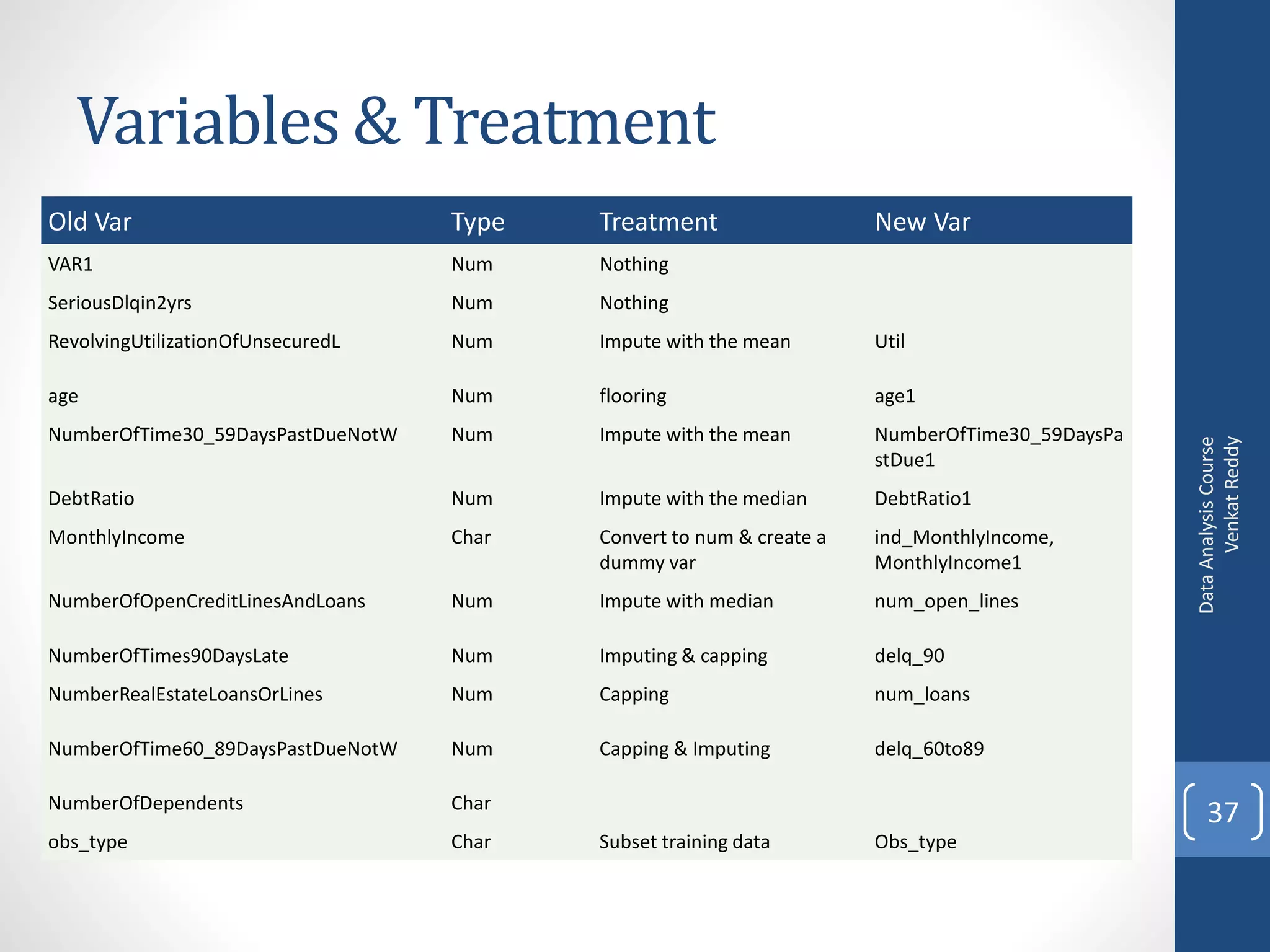


Here are some common approaches for handling missing values during data exploration and preparation: - Delete rows with missing values: Remove records that have any missing values. This reduces data size but can introduce bias if the deleted rows are systematically different. - Impute with mean/median: Replace missing values with the mean or median of the available values for that variable. Simple but can distort distributions. - Impute with mode: For categorical variables, replace missing with the most frequent category. - Impute with k-nearest neighbors: Replace missing with the mean of k closest neighbors based on other variable values. Accounts for relationships but more complex. - Create indicator/dummy variable: Add a binary variable to indicate if the























































































