Download as PDF, PPTX


















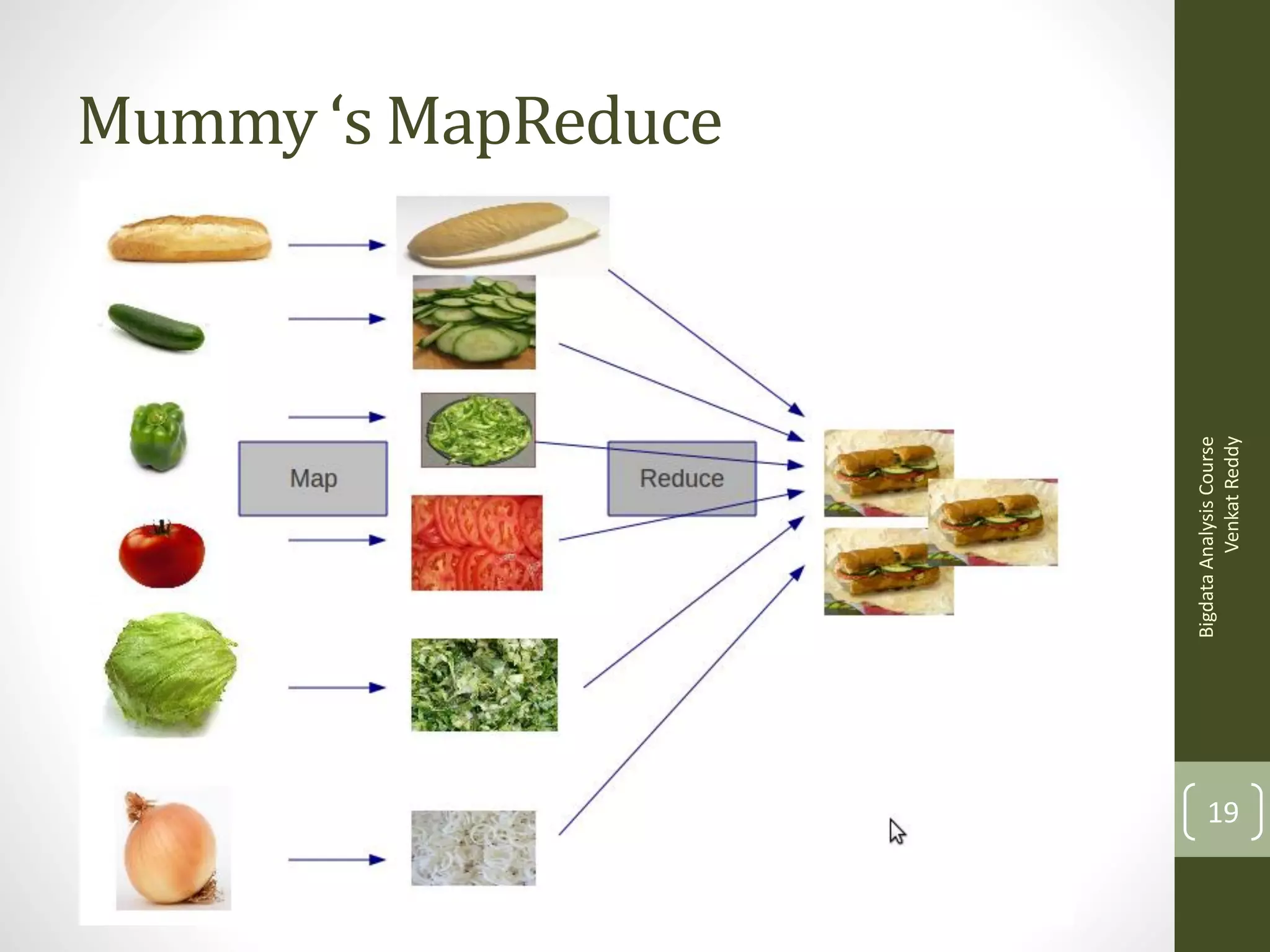







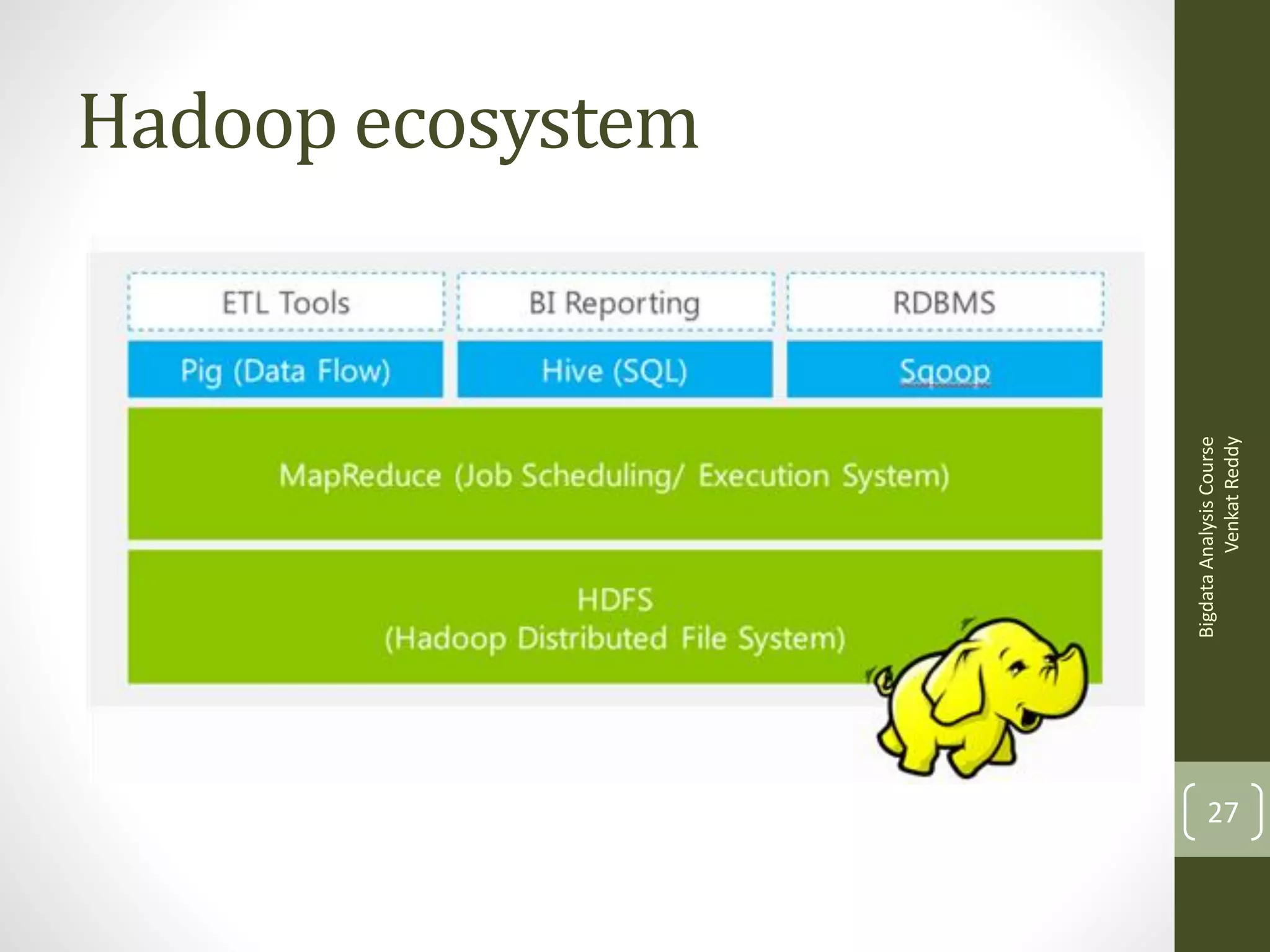
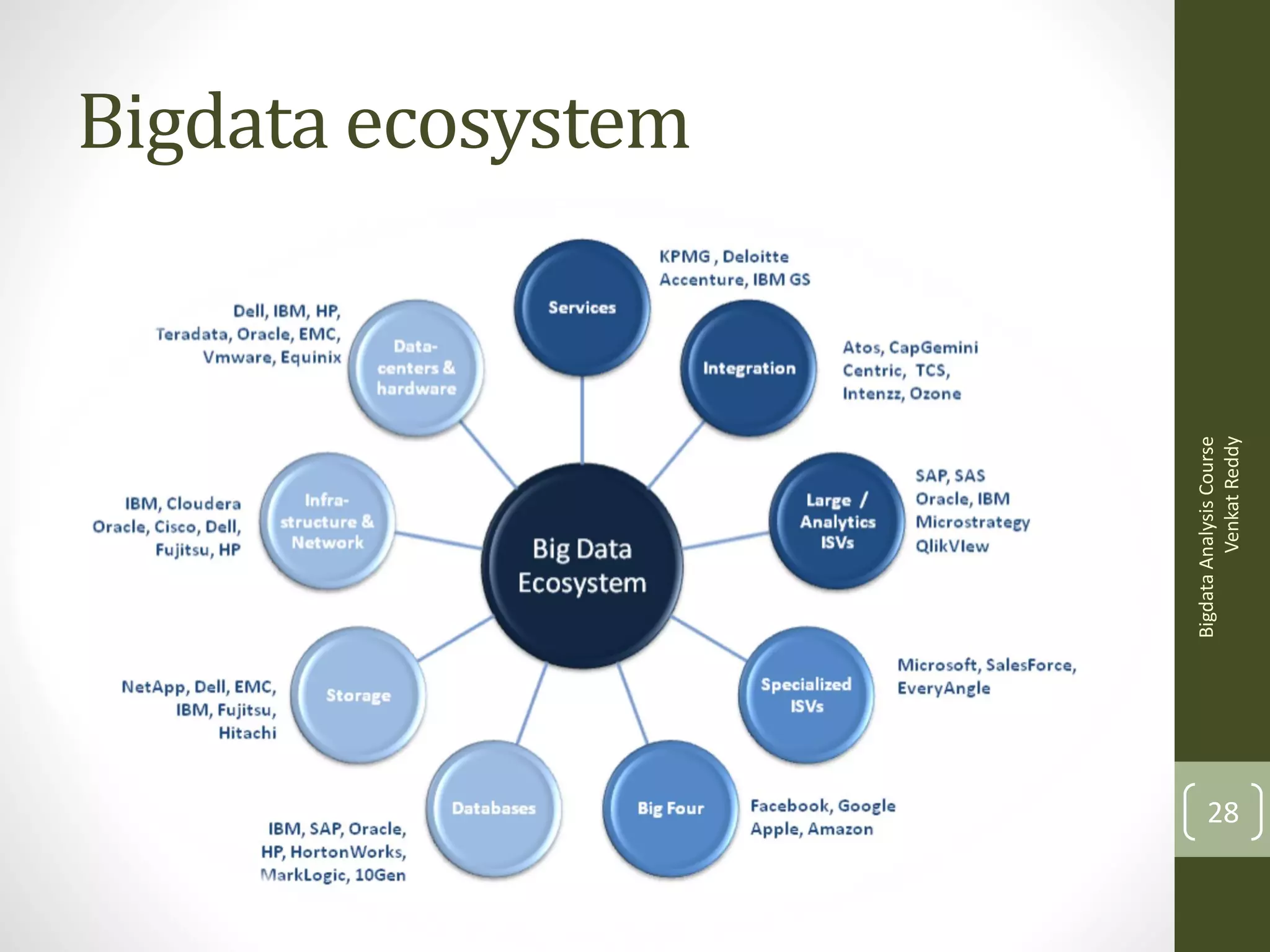

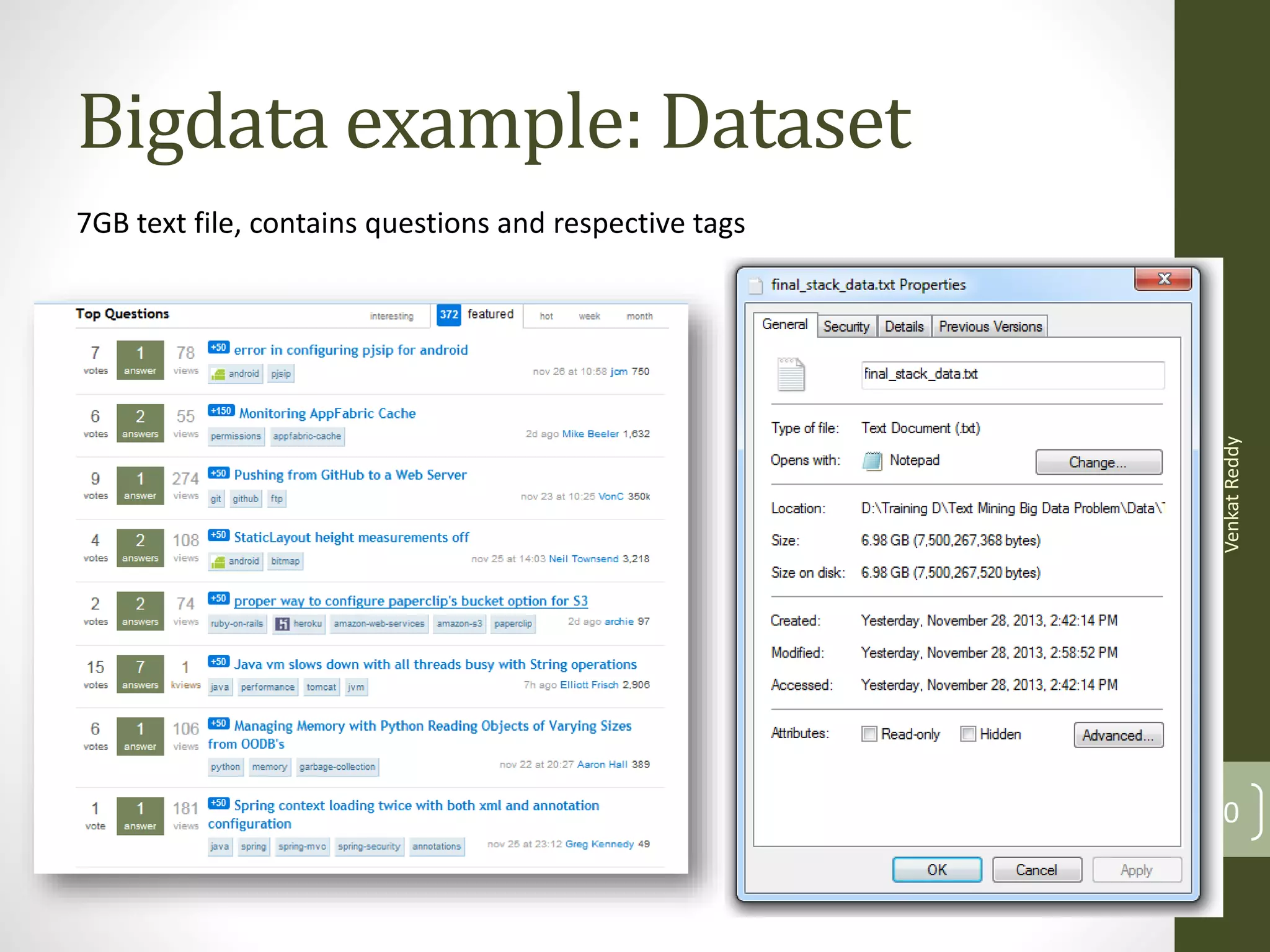









The document provides an introduction to the concepts of big data and how it can be analyzed. It discusses how traditional tools cannot handle large data files exceeding gigabytes in size. It then introduces the concepts of distributed computing using MapReduce and the Hadoop framework. Hadoop makes it possible to easily store and process very large datasets across a cluster of commodity servers. It also discusses programming interfaces like Hive and Pig that simplify writing MapReduce programs without needing to use Java.























































































