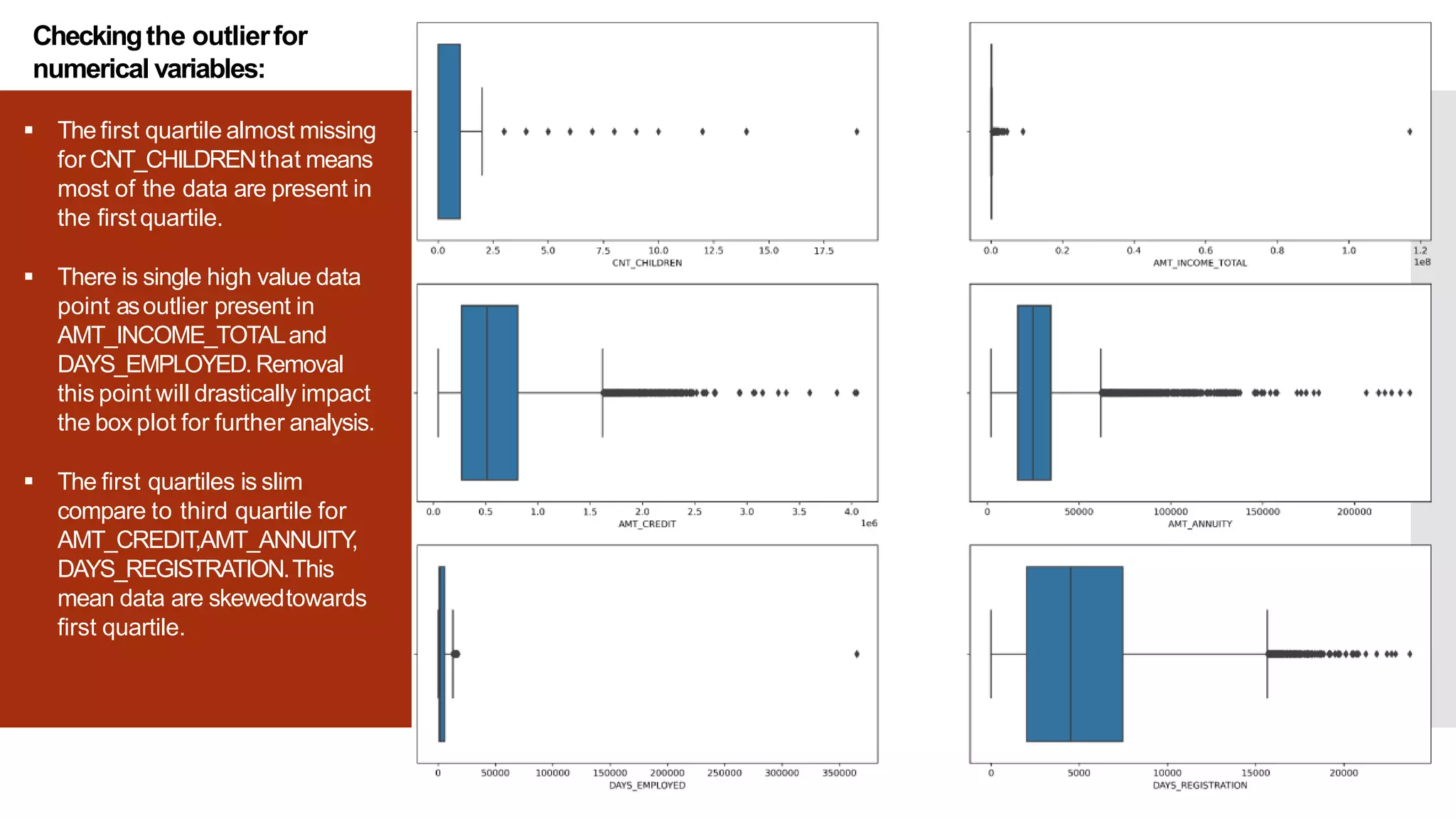
The document outlines a case study on applying Exploratory Data Analysis (EDA) in the context of risk analytics within banking, particularly focusing on customer lending. It emphasizes the identification and handling of missing data, outliers, and data imbalance, along with various analyses to understand factors influencing loan repayment difficulties. Recommendations include targeting specific customer segments and housing types for successful loan approvals, while advising caution on loans for certain purposes and categories.