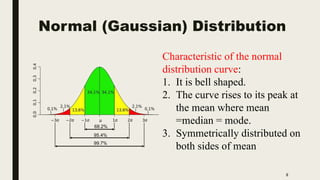
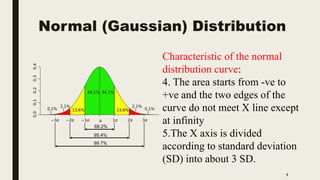
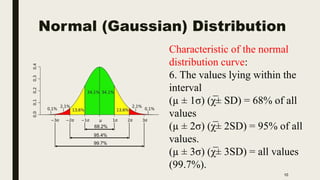
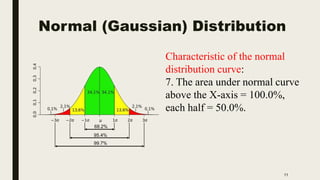
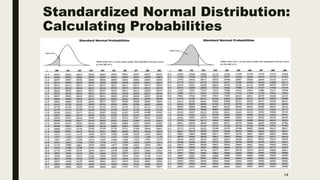
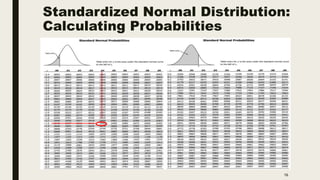
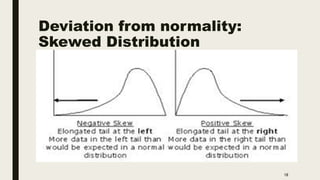
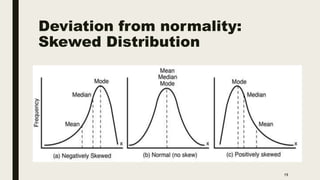
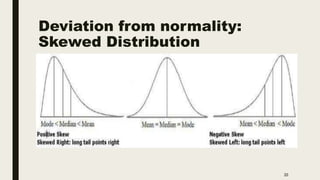
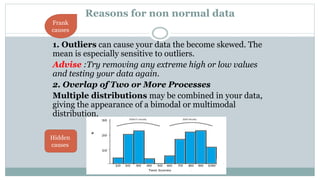
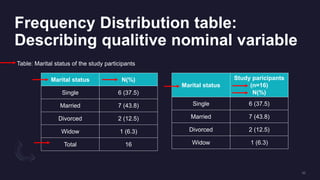
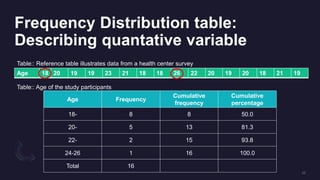
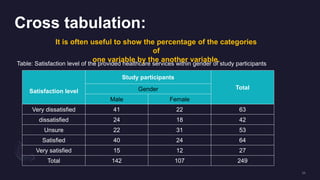
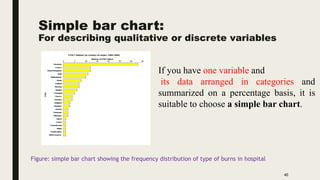
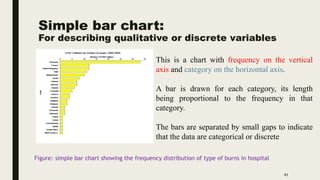
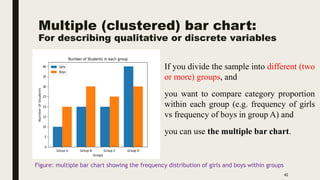
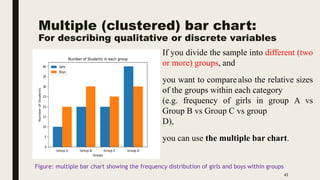
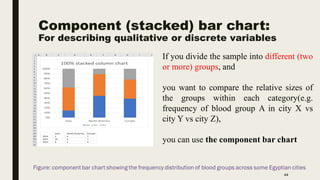
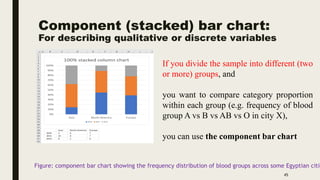
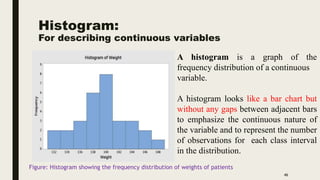
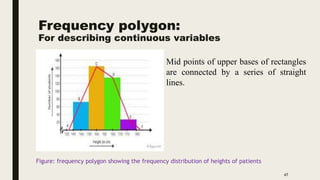
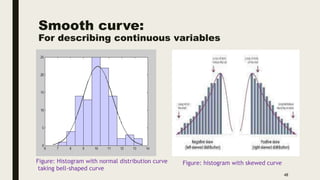
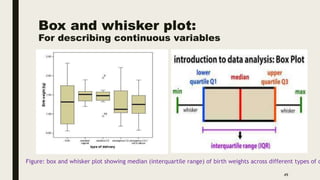
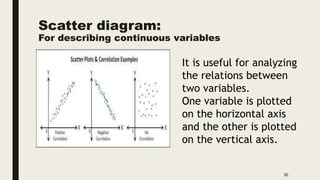
The document discusses data distribution and presentation. It covers topics like the normal distribution curve, calculating probabilities using the standardized normal distribution table, and presenting data through tables and graphs. Specifically, it provides details on creating frequency distribution tables for qualitative and quantitative variables. It also discusses cross tabulation and different types of graphs like pie charts, simple bar charts, and multiple bar charts for presenting categorical data.