Downloaded 83 times






![[email_address]](https://image.slidesharecdn.com/bigsheets-100512073719-phpapp02/85/Big-Tools-for-Big-Data-8-320.jpg)







![Thank you! [email_address] http://uk.linkedin.com/in/lewiscrawford 3x30 Nehalem-based node grids, with 2x4 cores, 16GB RAM, 8x1TB storage using ZFS in a JBOD configuration. Hadoop and Pig for discovering People You May Know and other fun facts.](https://image.slidesharecdn.com/bigsheets-100512073719-phpapp02/85/Big-Tools-for-Big-Data-28-320.jpg)

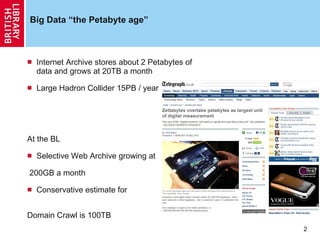
This document discusses big data tools and management at large scales. It introduces Hadoop, an open-source software framework for distributed storage and processing of large datasets using MapReduce. Hadoop allows parallel processing of data across thousands of nodes and has been adopted by large companies like Yahoo!, Facebook, and Baidu to manage petabytes of data and perform tasks like sorting terabytes of data in hours.















































