















![Search Results - Striking the balance
24
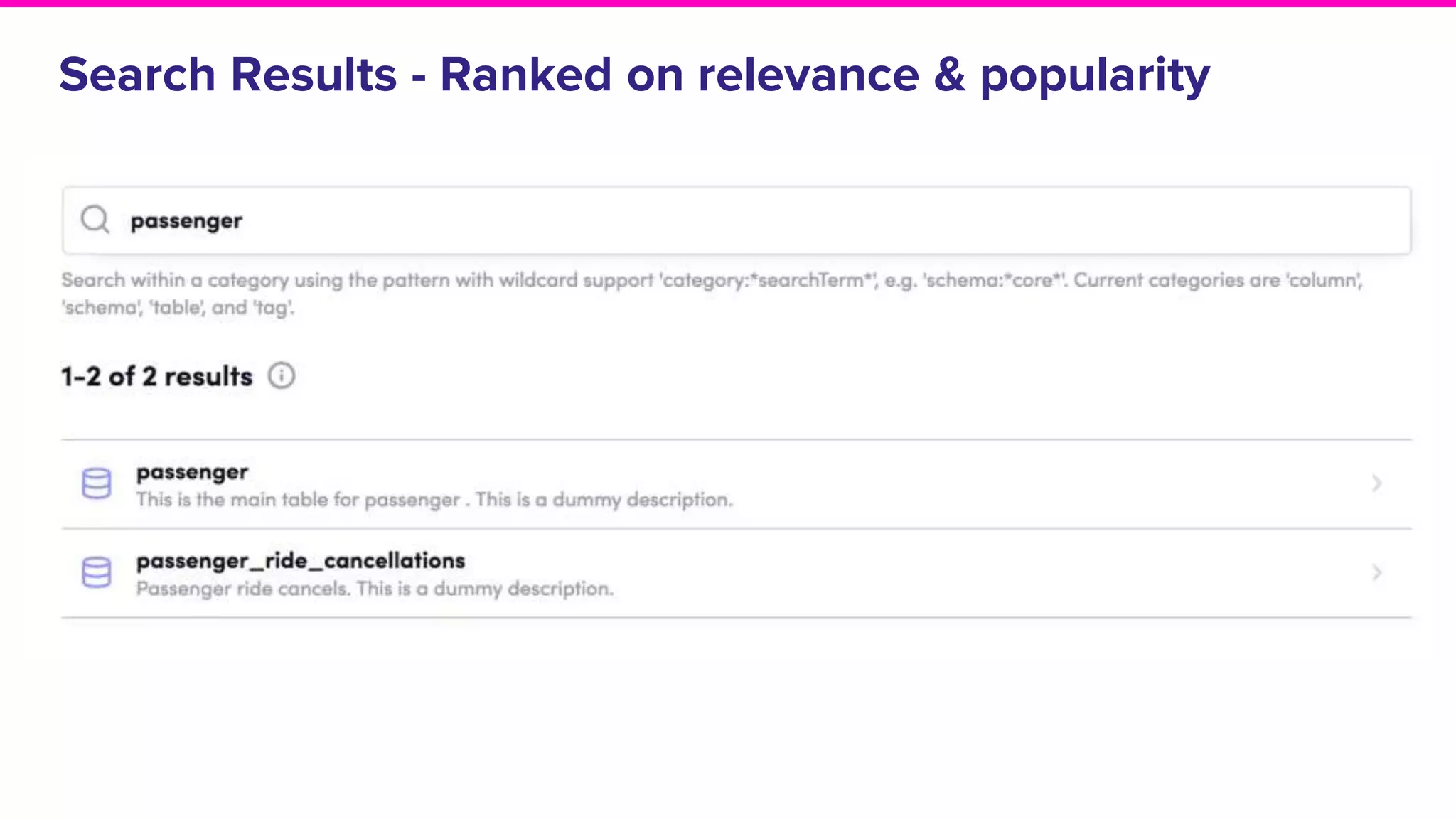
Relevance Popularity
● Names, Descriptions, Tags, [owners, frequent
users]
● Different weights for different metadata, e.g.
resource name
● Querying activity
● Dashboarding
● Lower weight for automated querying
● Higher weight for adhoc querying](https://image.slidesharecdn.com/m2pgmkobsxmrsybuqarq-signature-f8eb3c0e1d98e09e6db907f71272f67fed9c97c3f37066db620ea2a678be8c91-poli-191003210303/75/How-Lyft-Drives-Data-Discovery-24-2048.jpg)
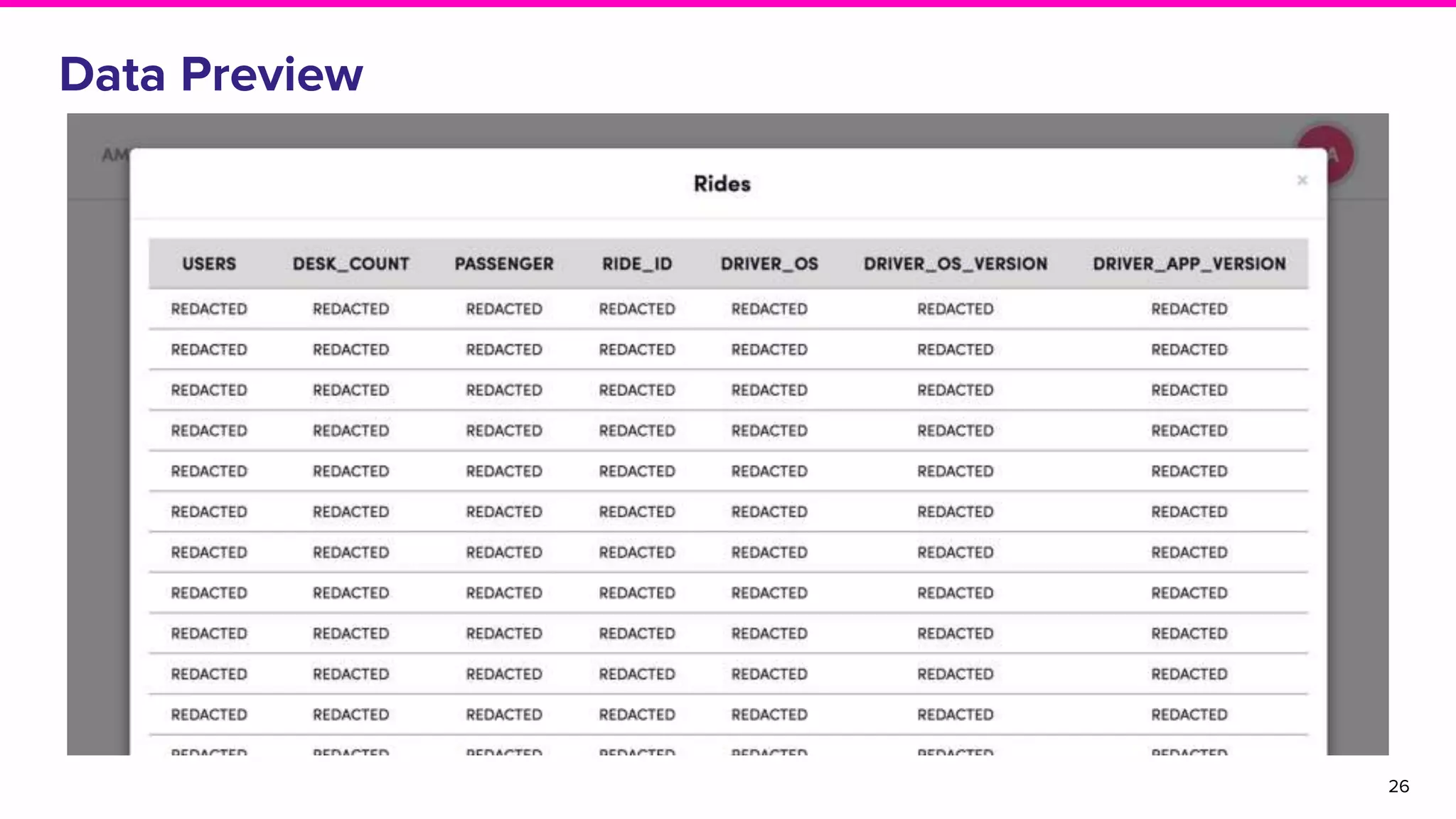



















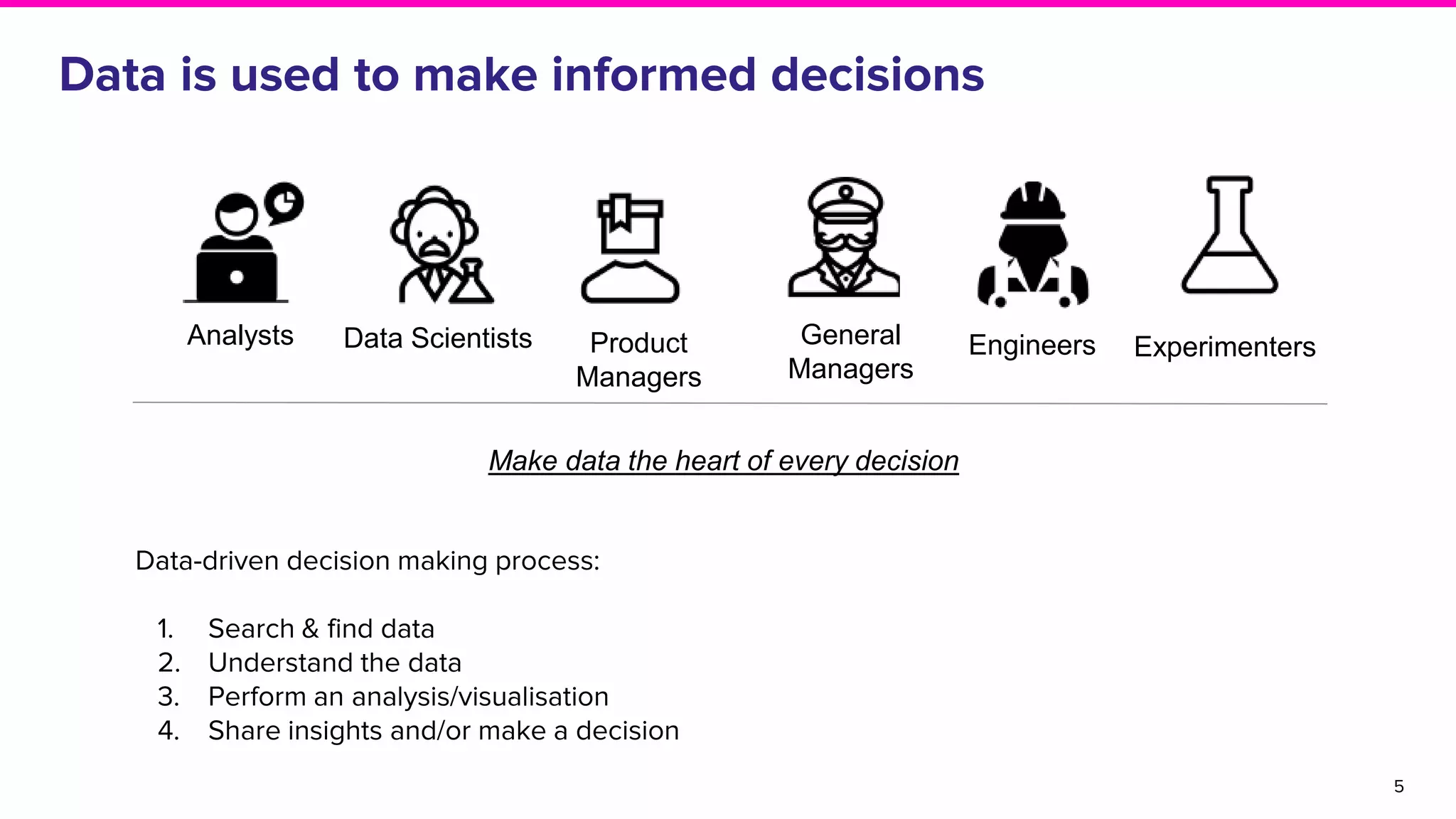
This document provides an overview of Amundsen, an open source data discovery and metadata platform developed by Lyft. It begins with an introduction to the challenges of data discovery and outlines Amundsen's architecture, which uses a graph database and search engine to provide metadata about data resources. The document discusses how Amundsen impacts users at Lyft by reducing time spent searching for data and discusses the project's community and future roadmap.
Introduction of Phil Mizrahi and the challenges in data discovery, with an agenda overview.
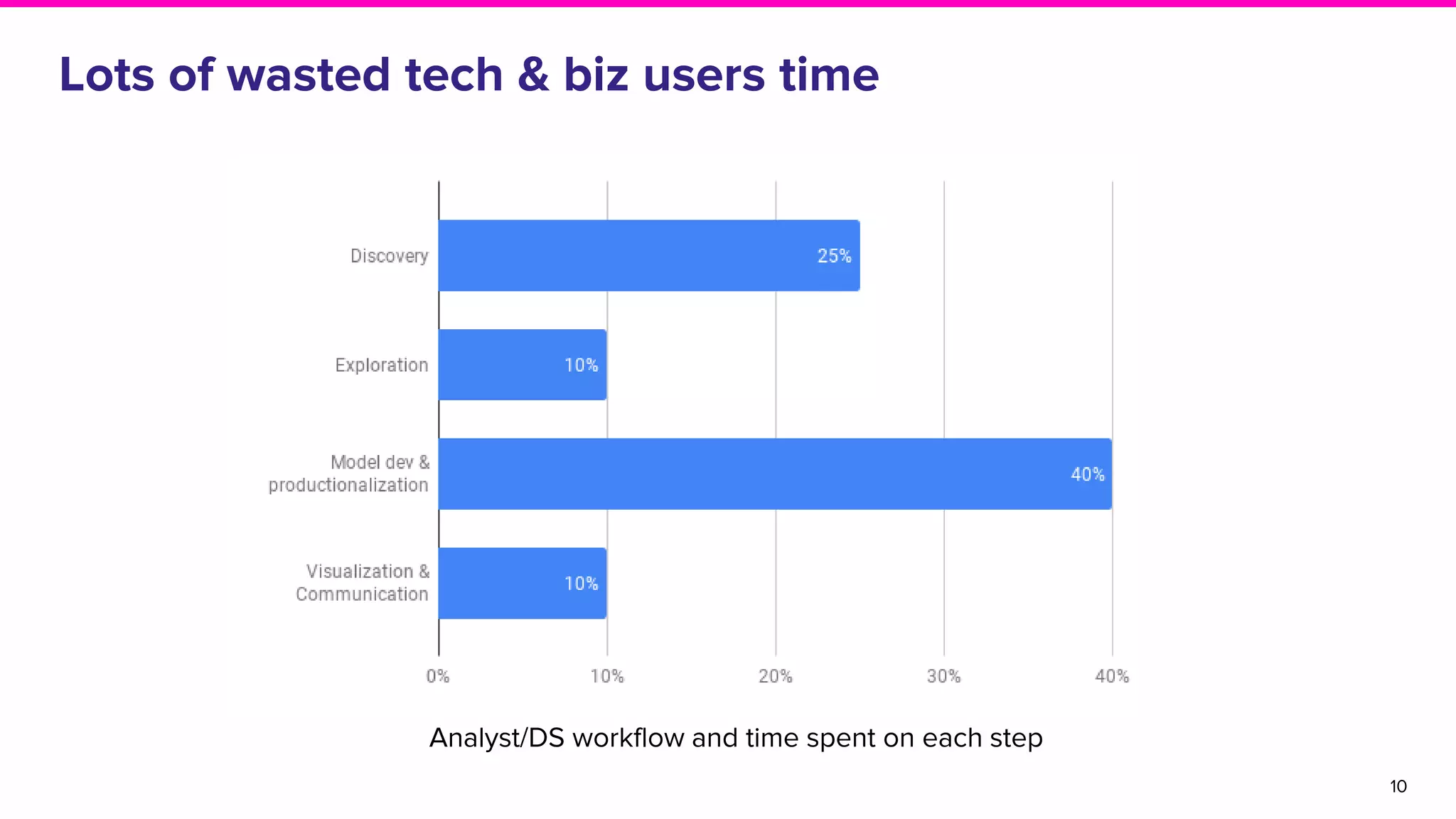
Details on challenges in data discovery including decision-making processes, data availability, and productivity issues.
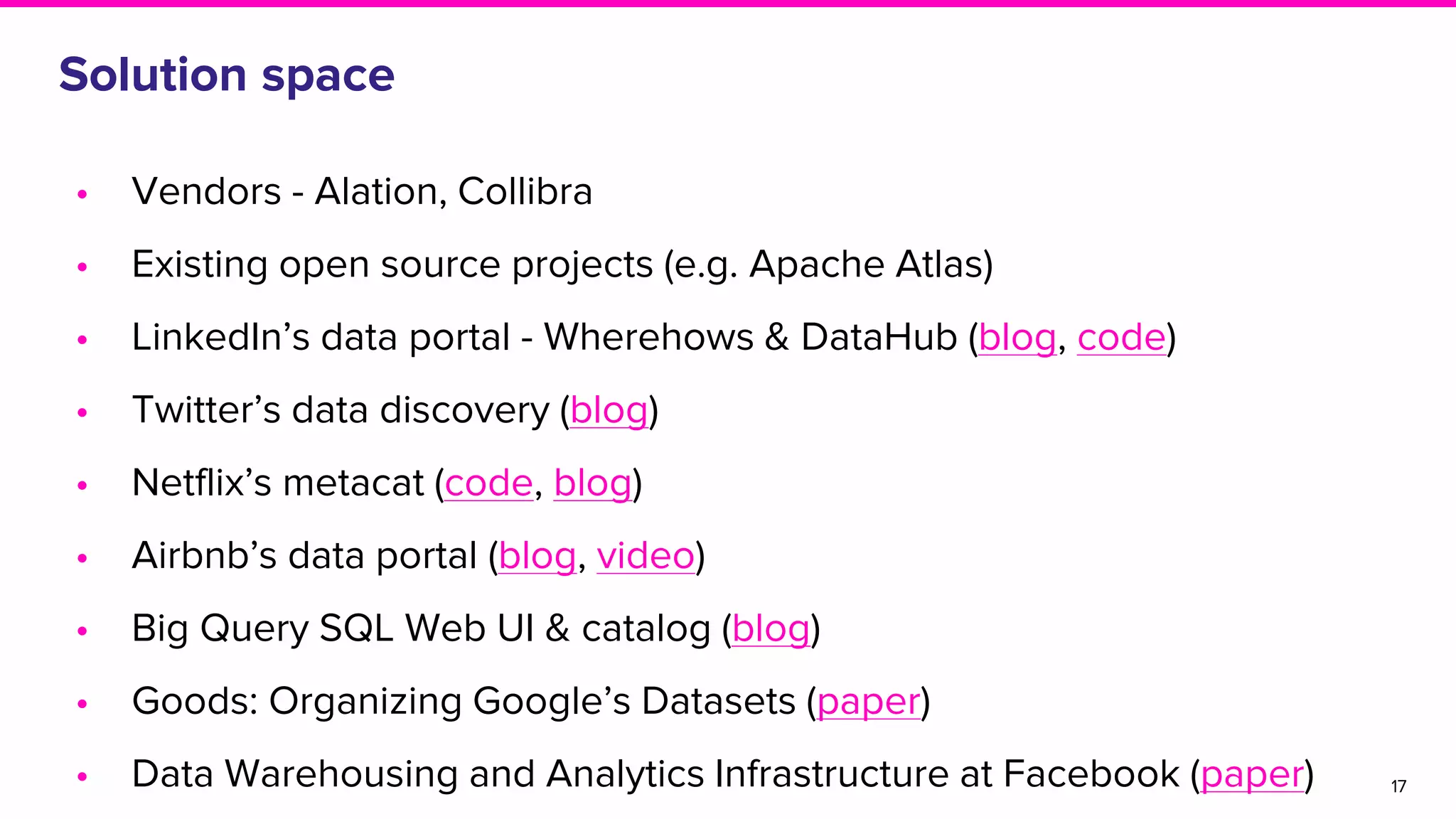
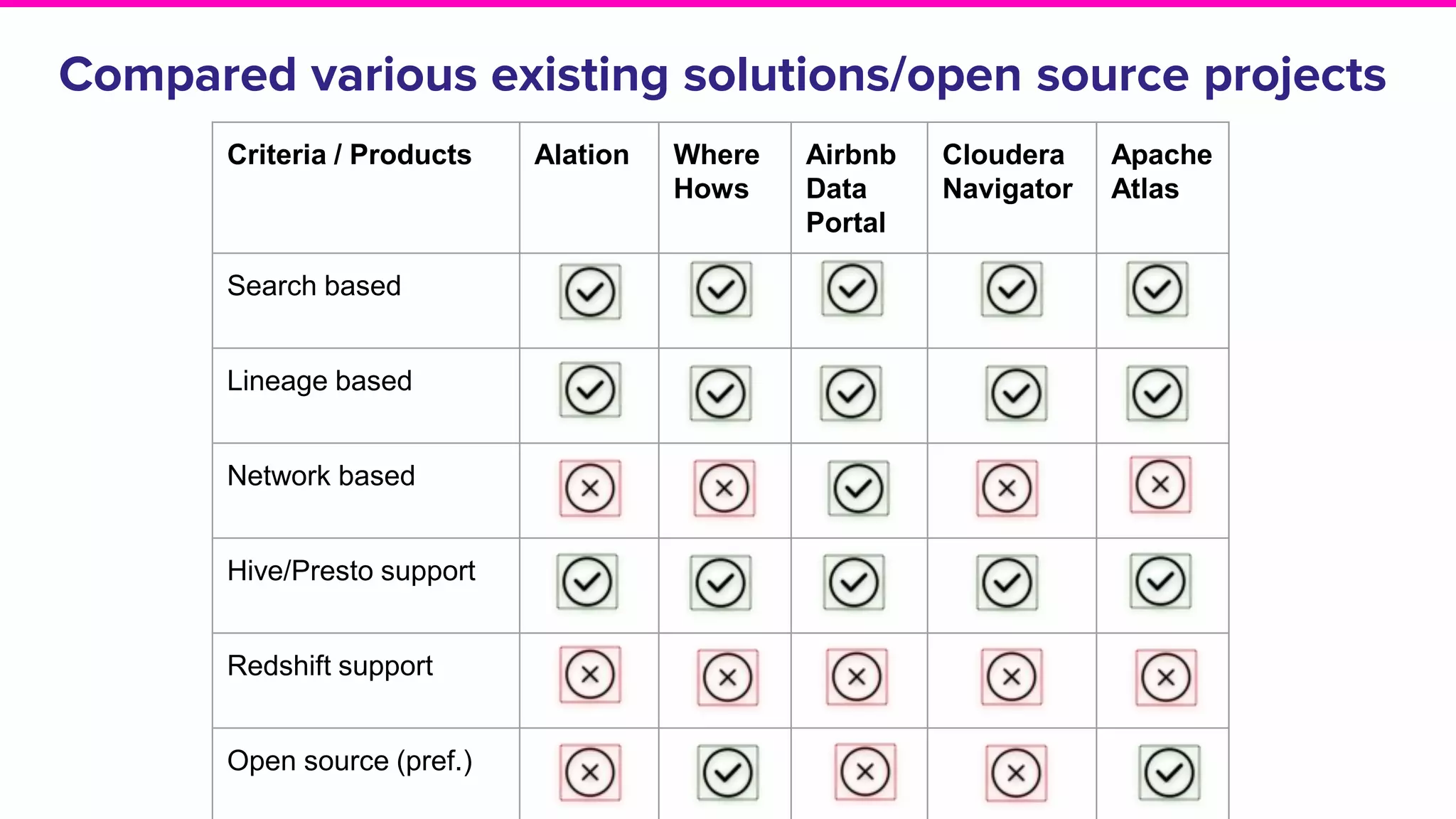
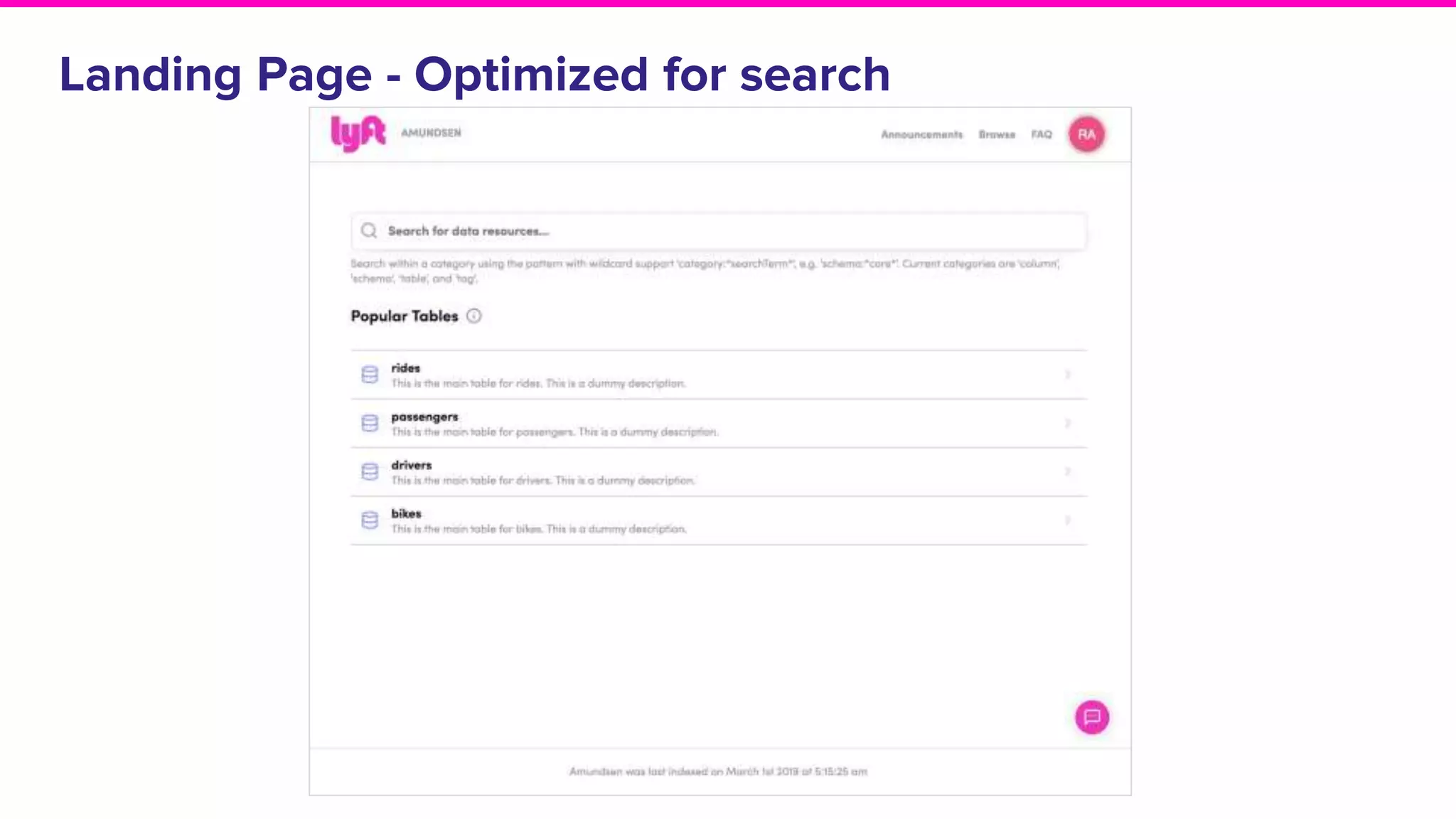
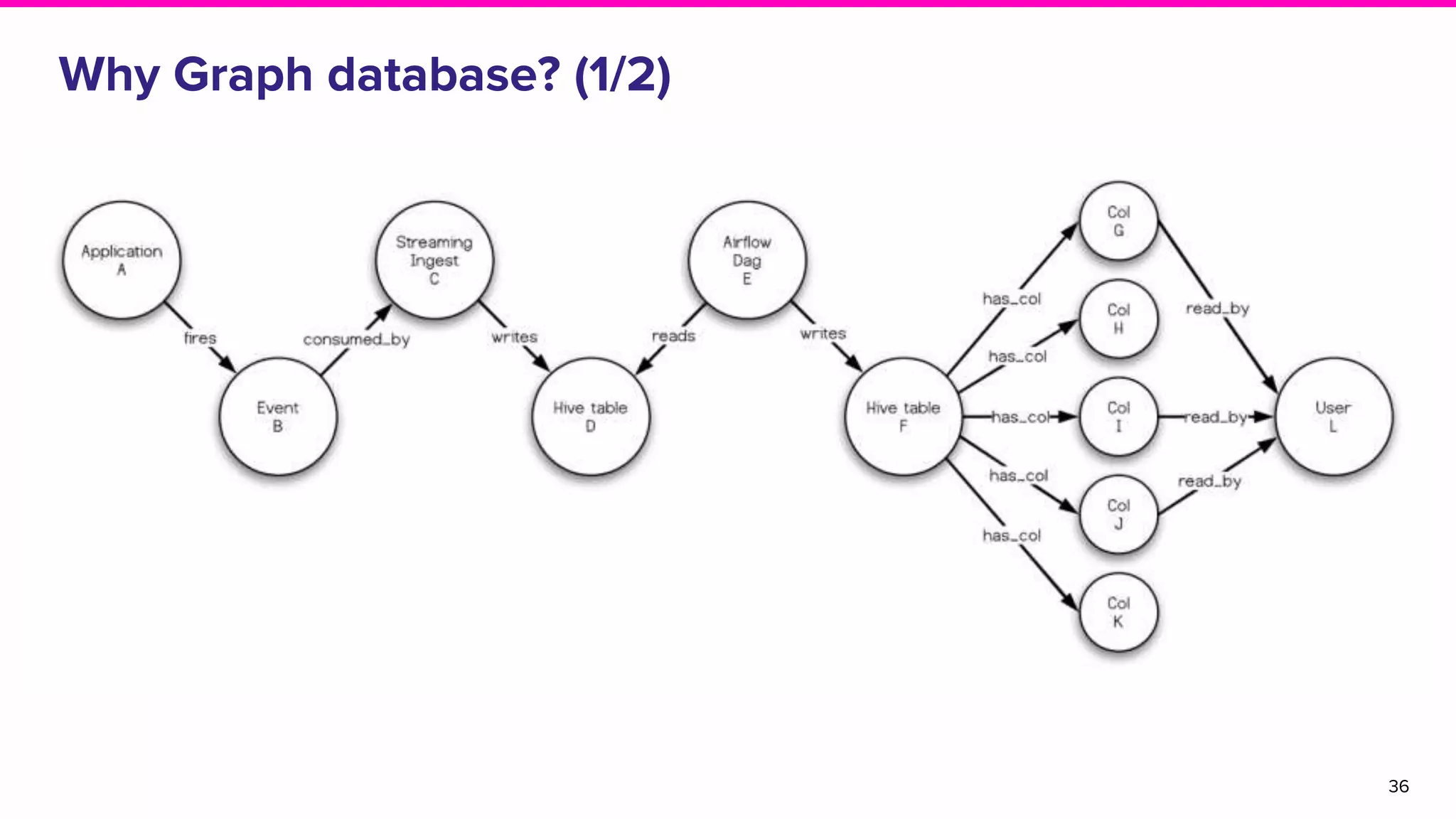
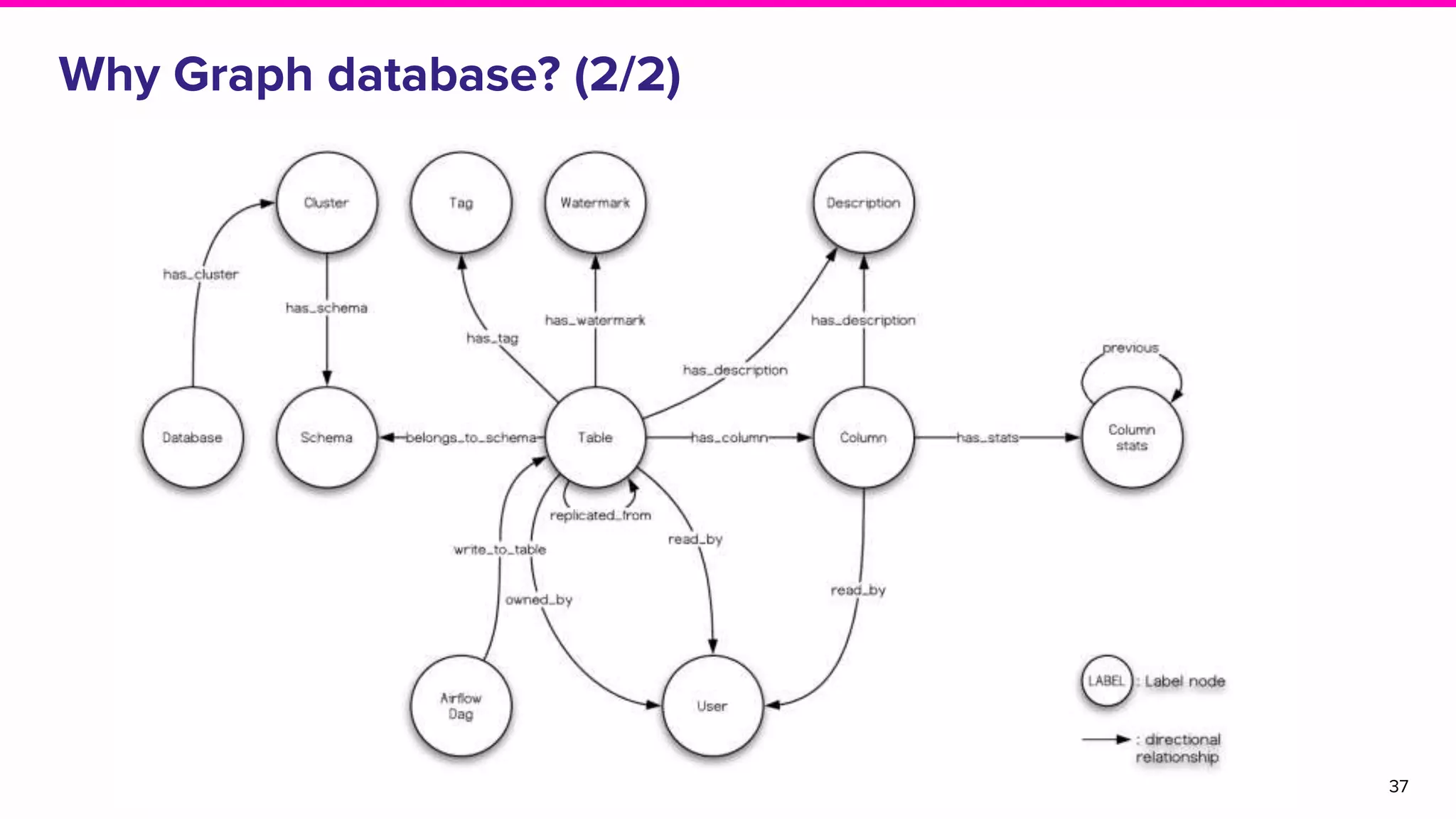
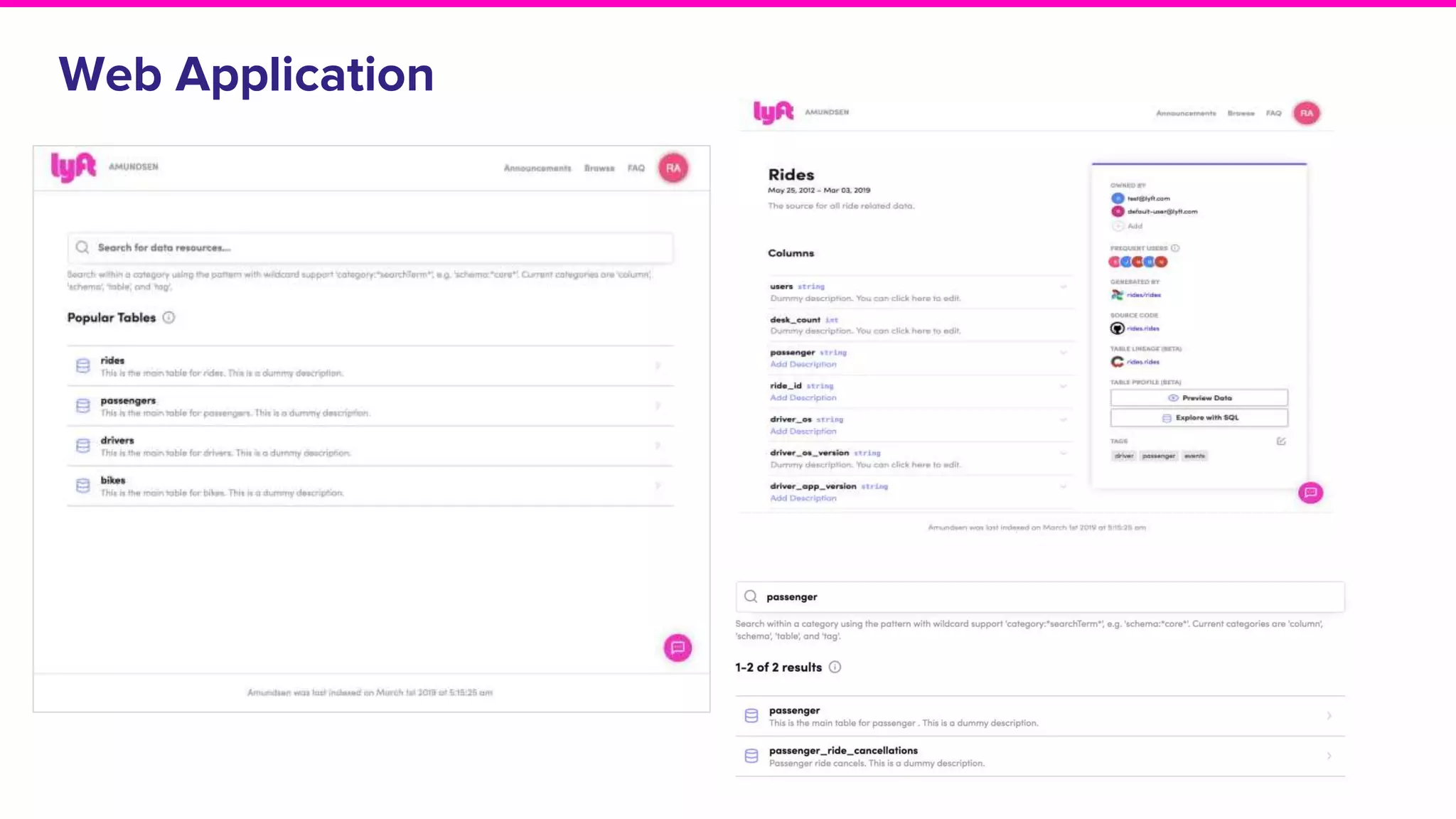
Exploration of solutions for data discovery including metadata, search methods, lineage, and network-based strategies.Overview of Amundsen, its naming origin, and its user-friendly features for efficient data discovery.
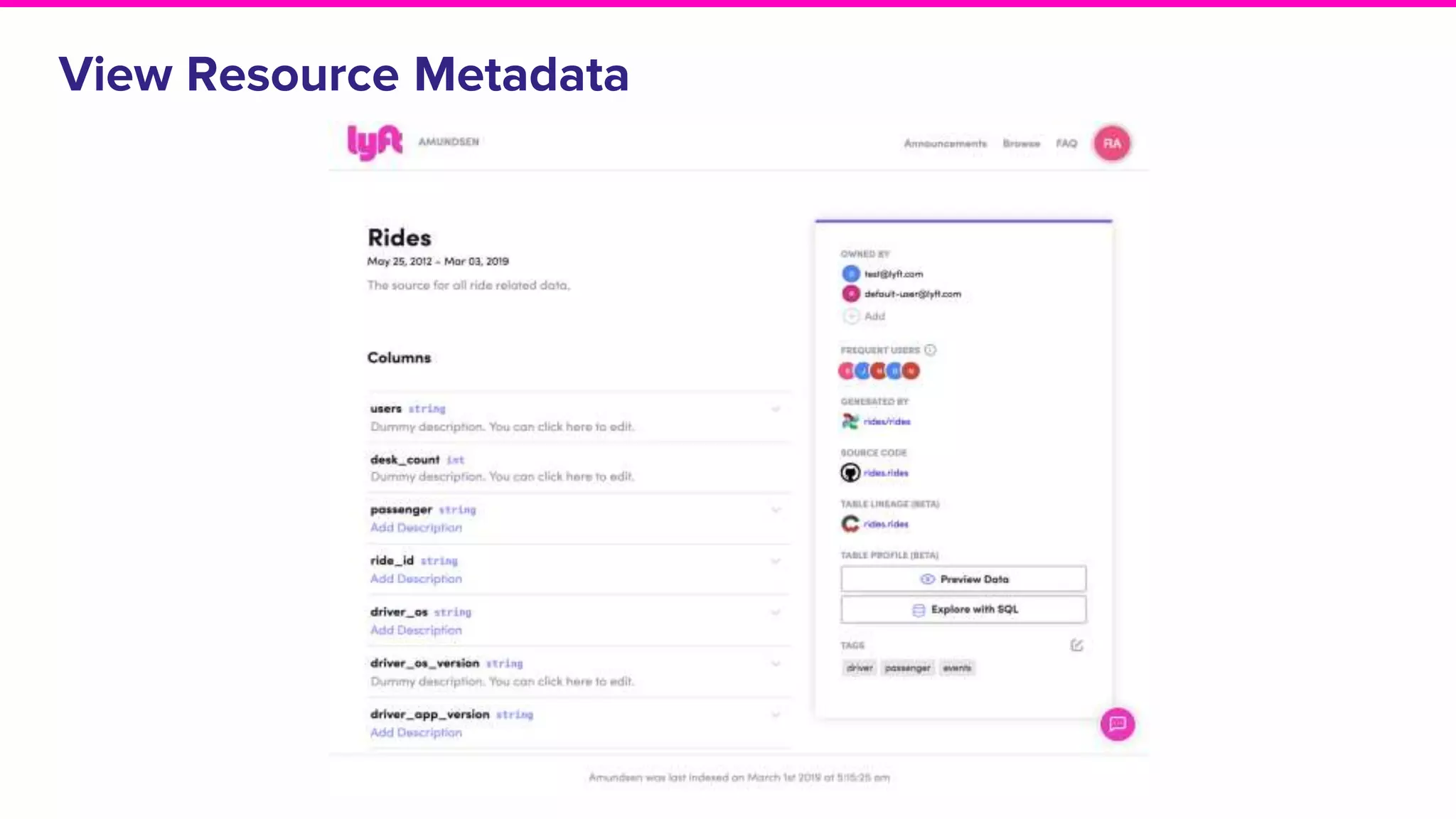
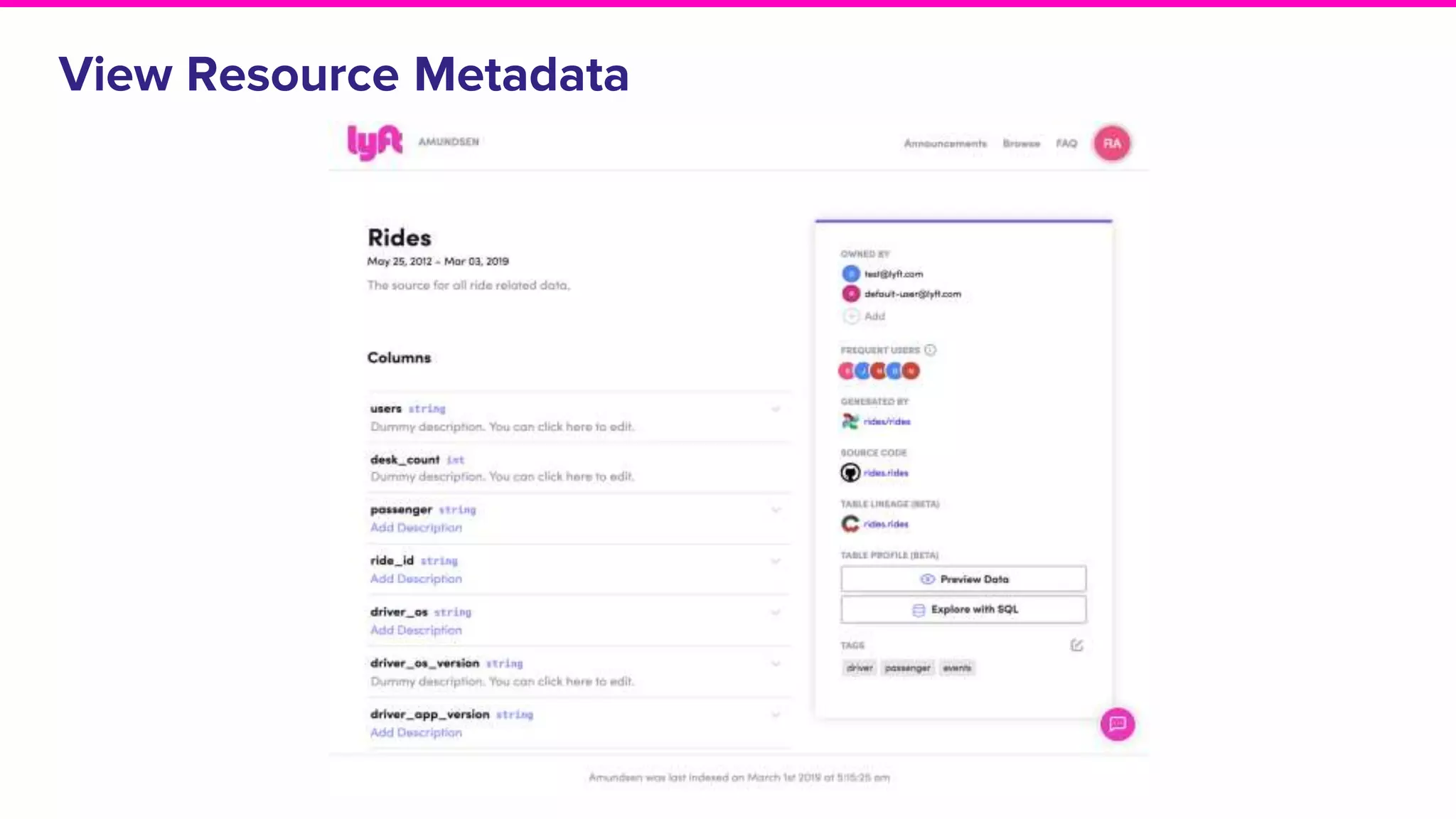
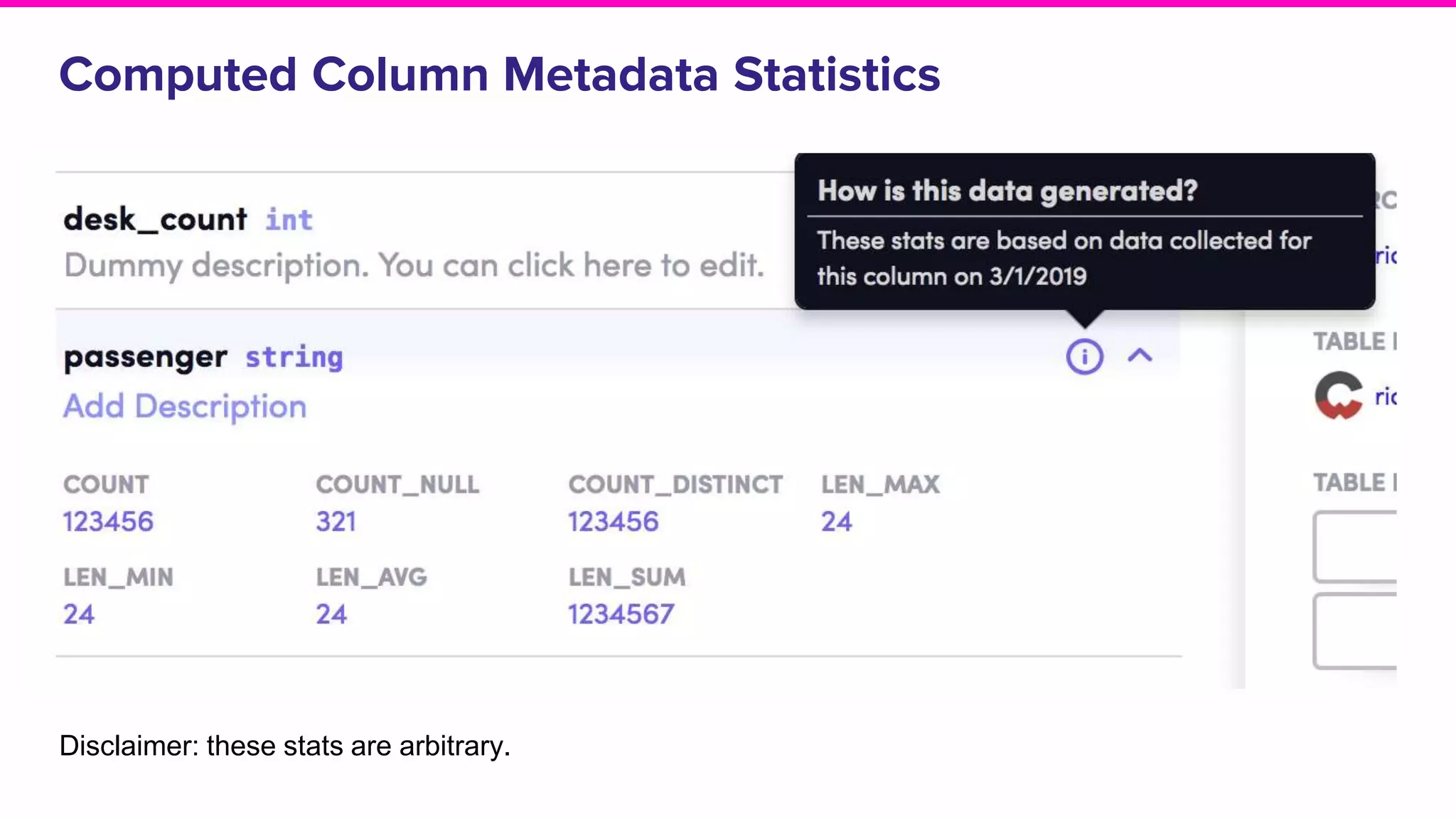
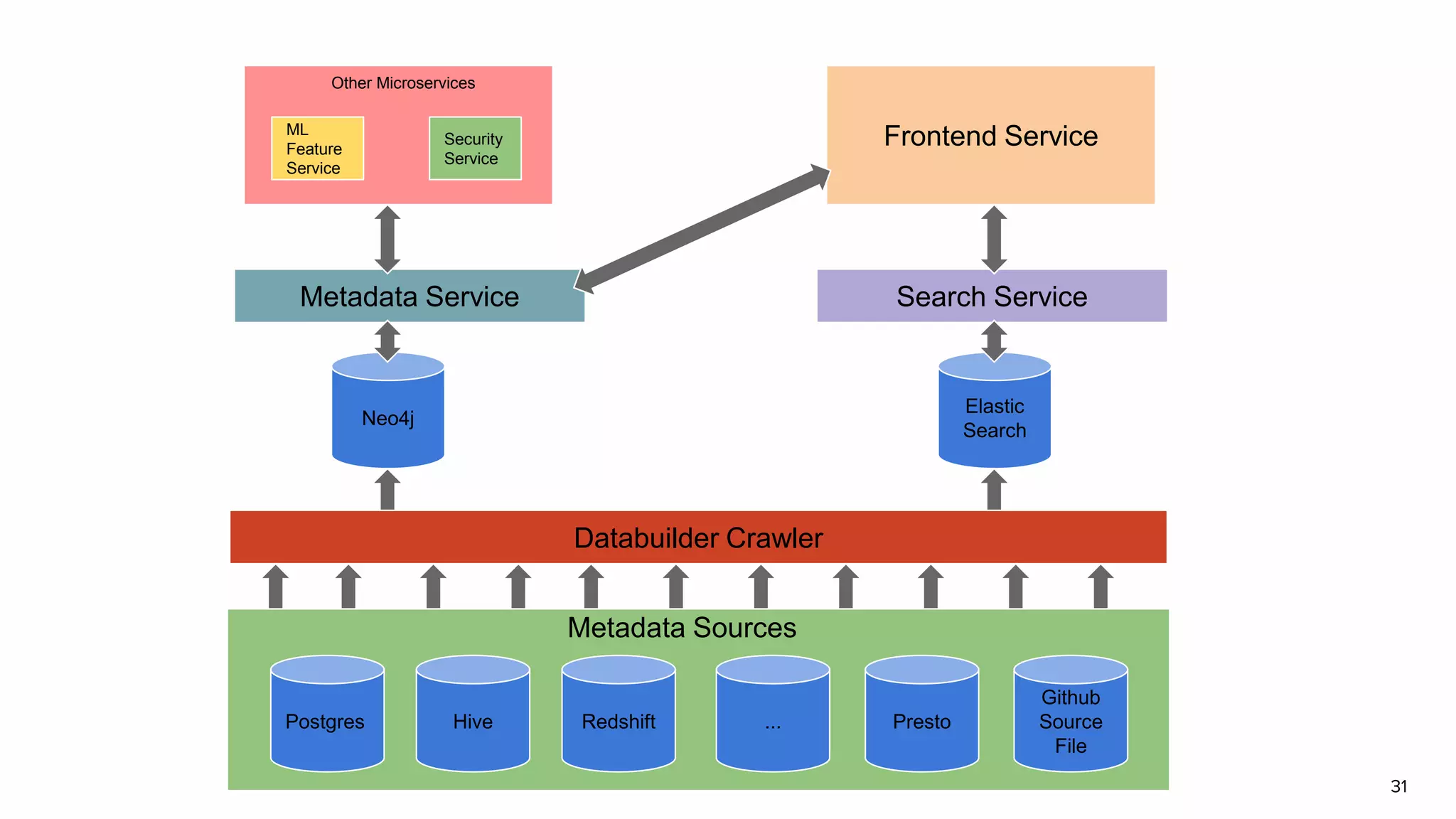
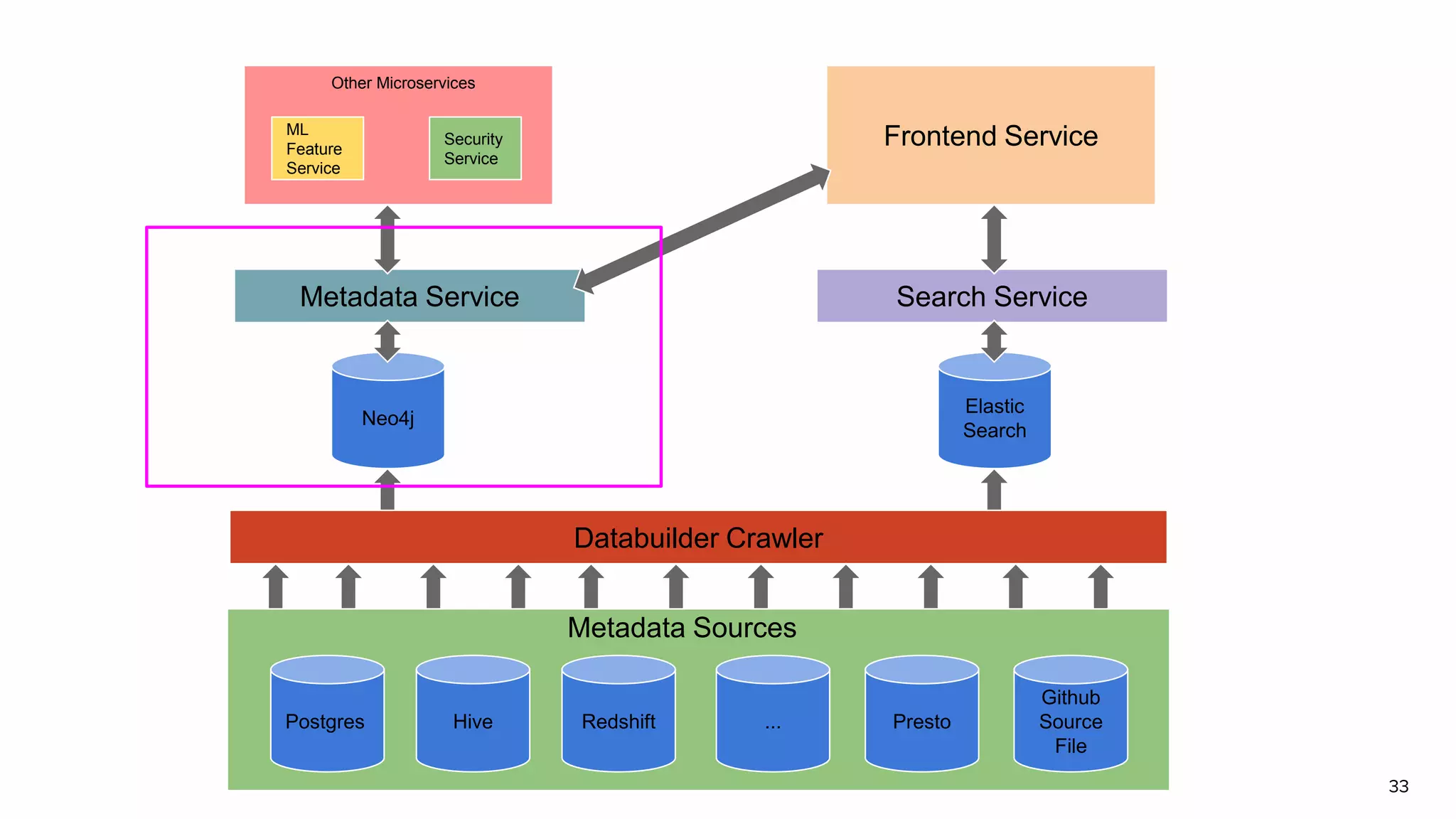
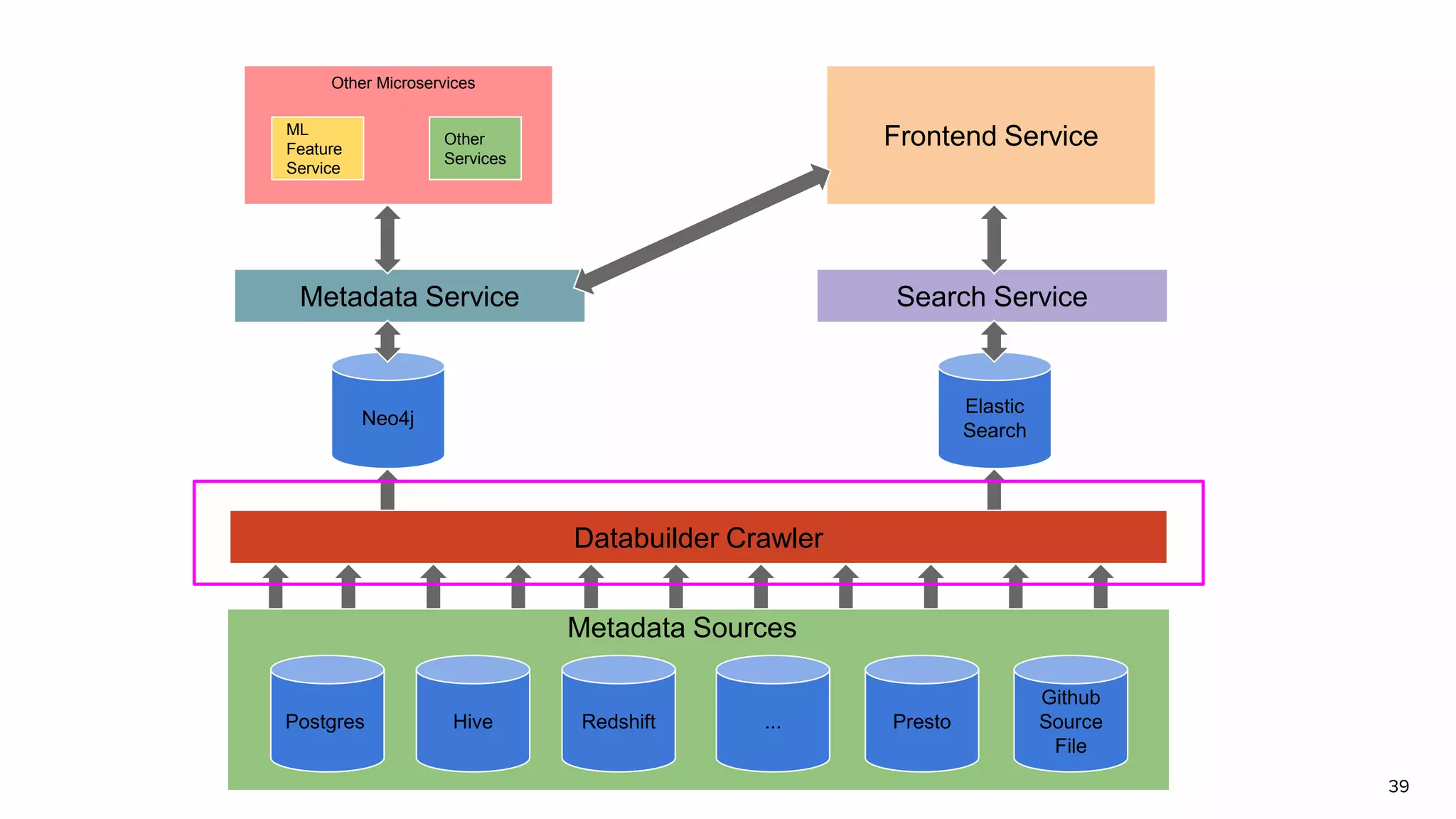
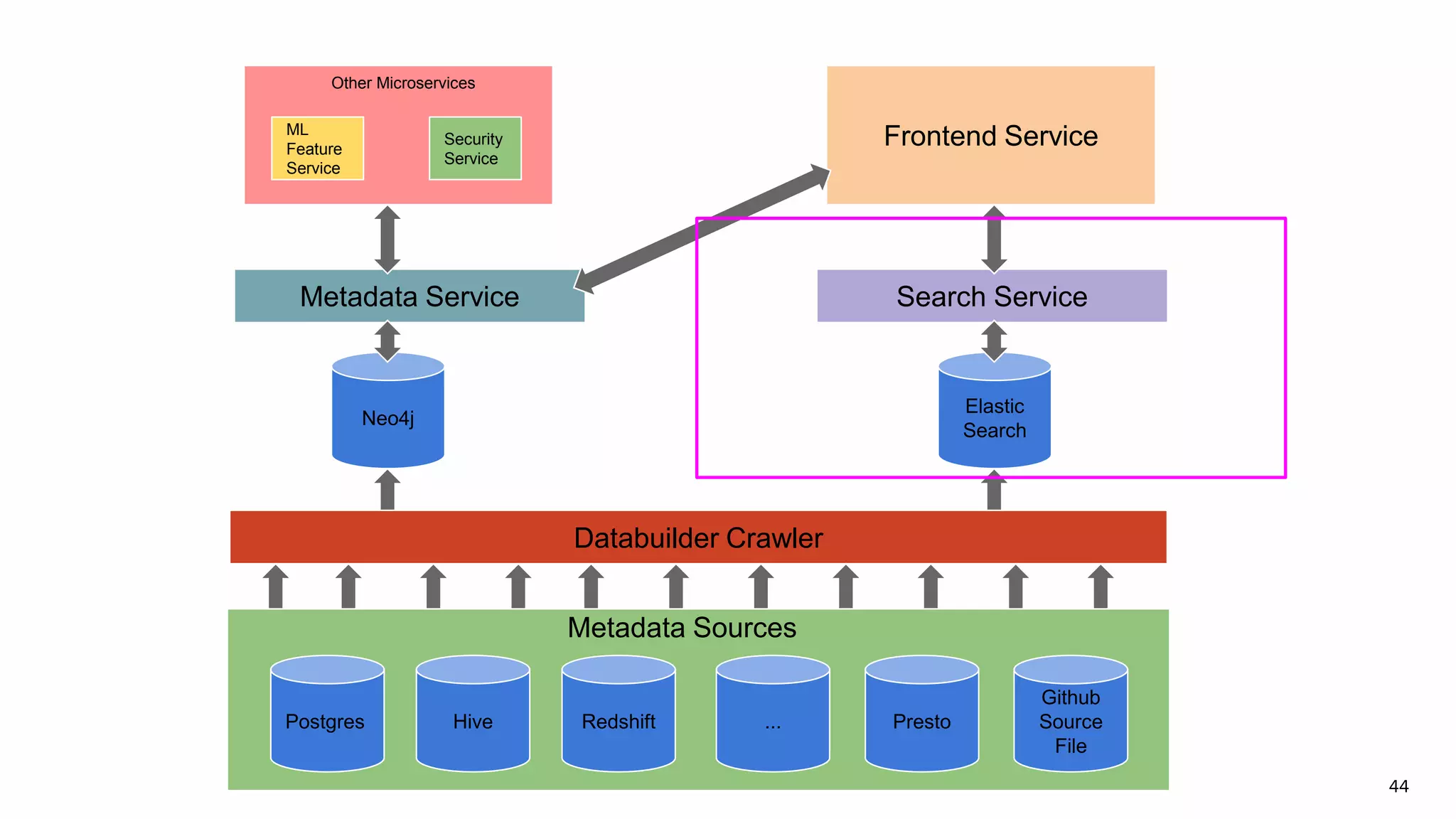
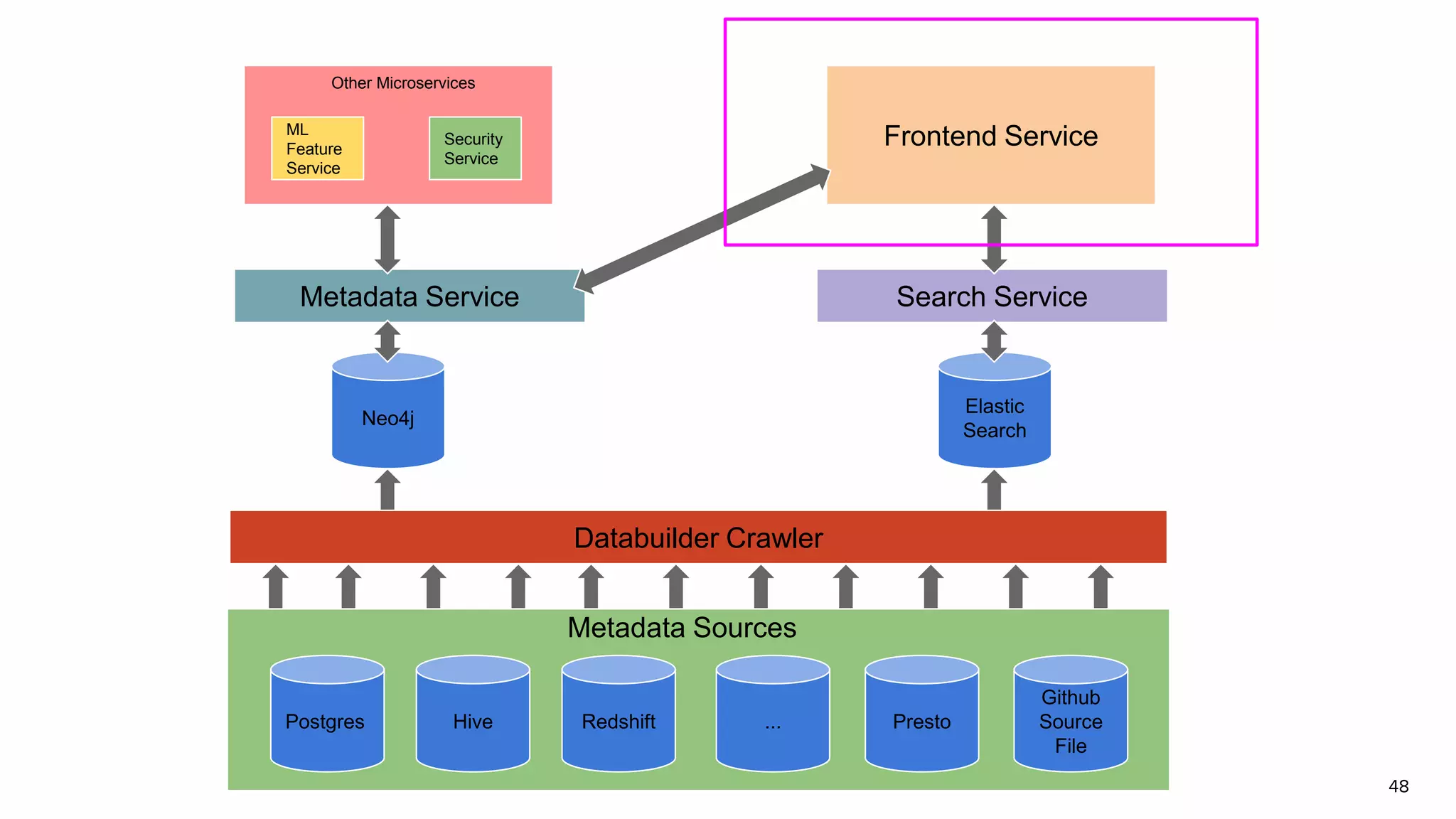
Discussion on search result relevance, popularity balance, and user interface for resource metadata.Detailed architecture of Amundsen focusing on components like the Metadata Service and Challenges in standardizing metadata.
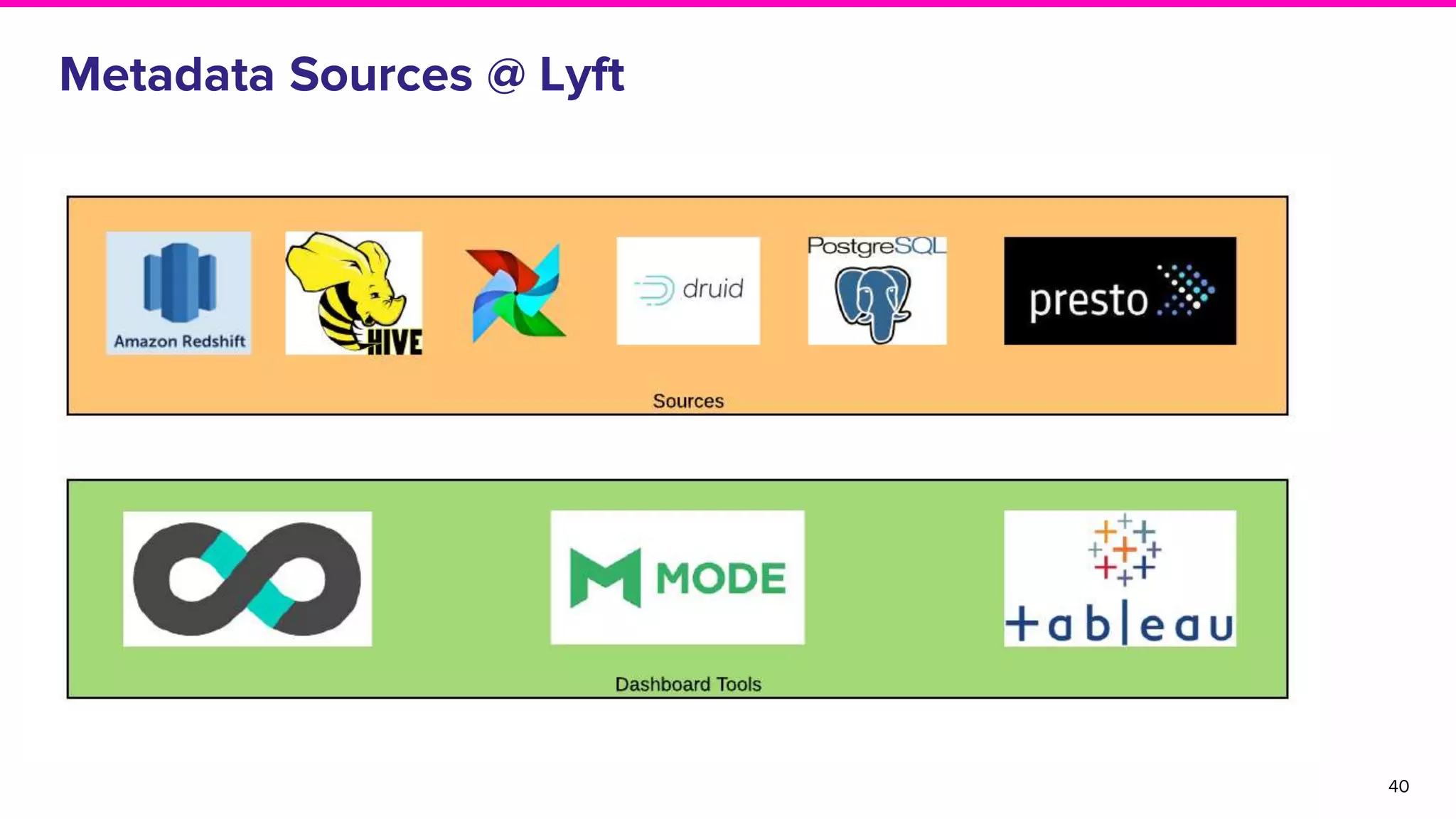
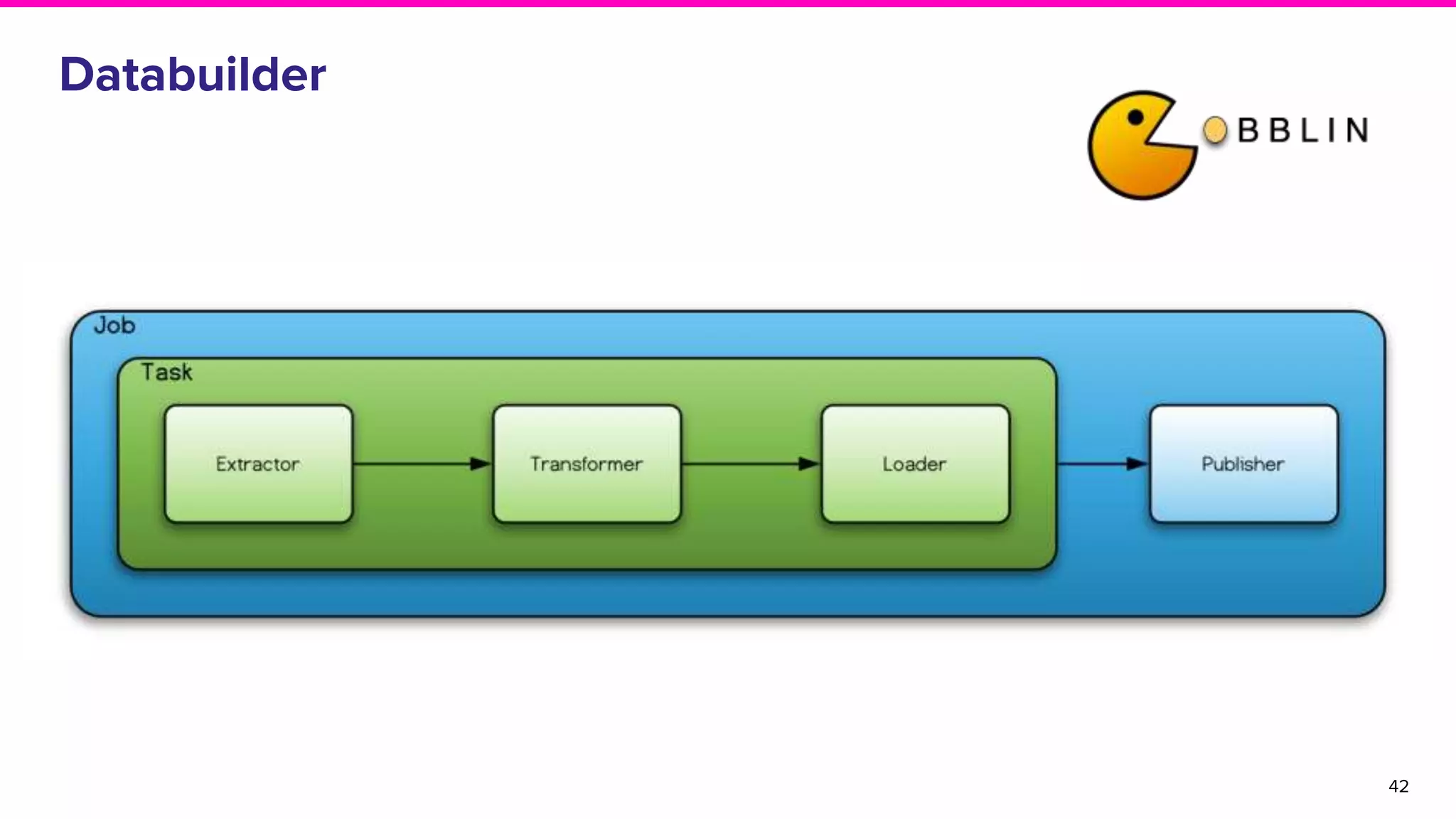
Functions of Databuilder, Search Service, and Frontend Service within Amundsen architecture.
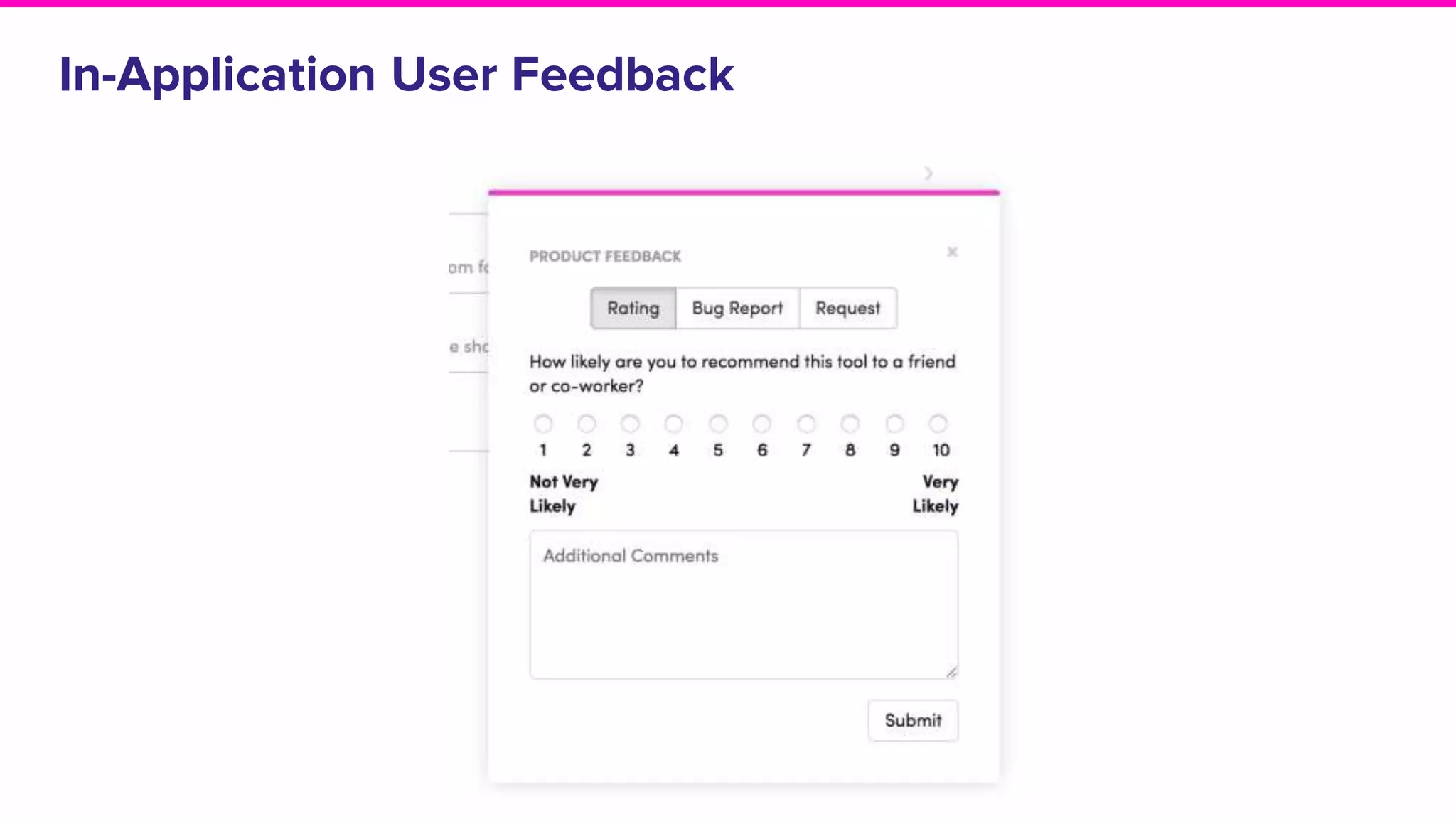
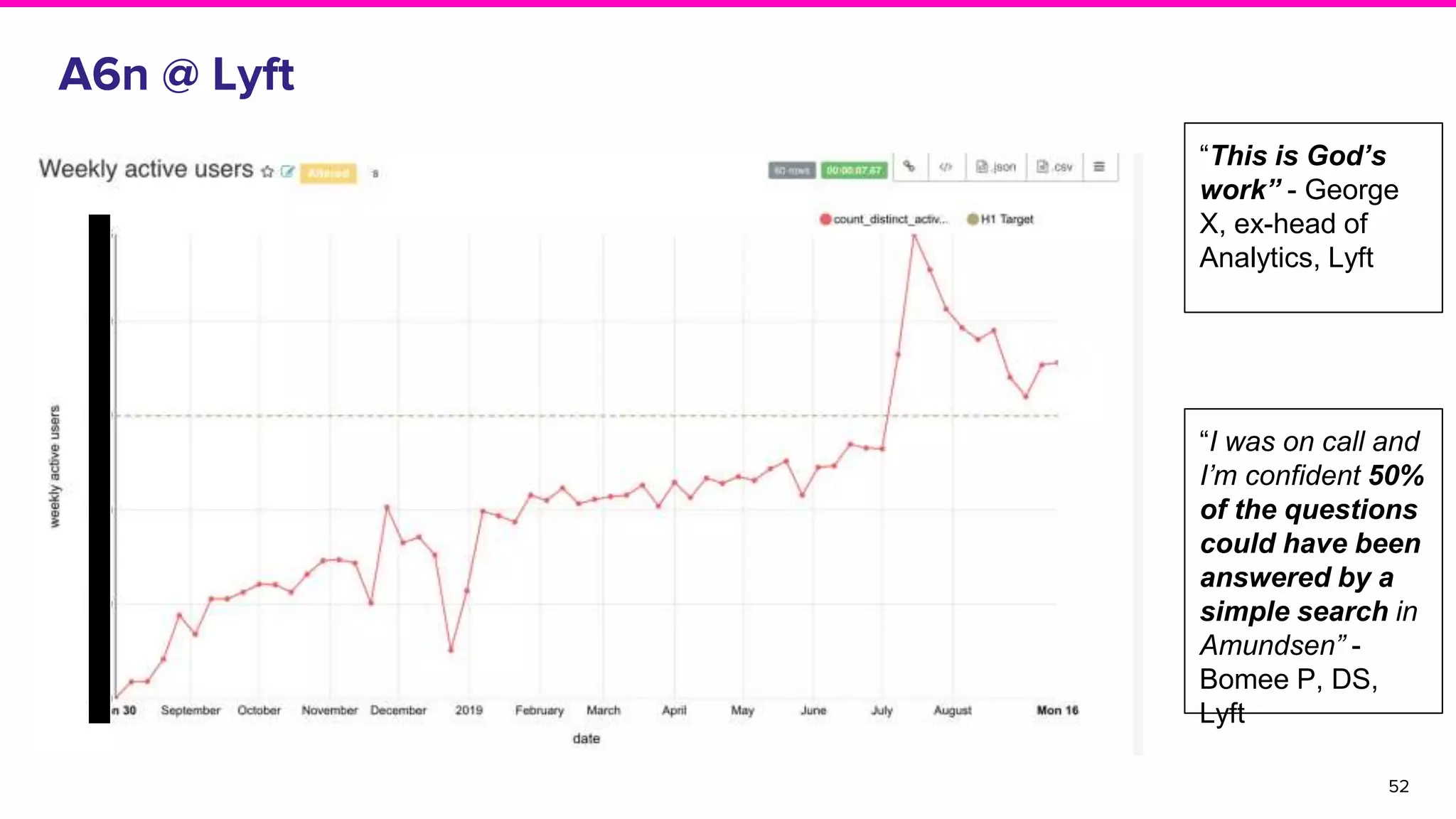
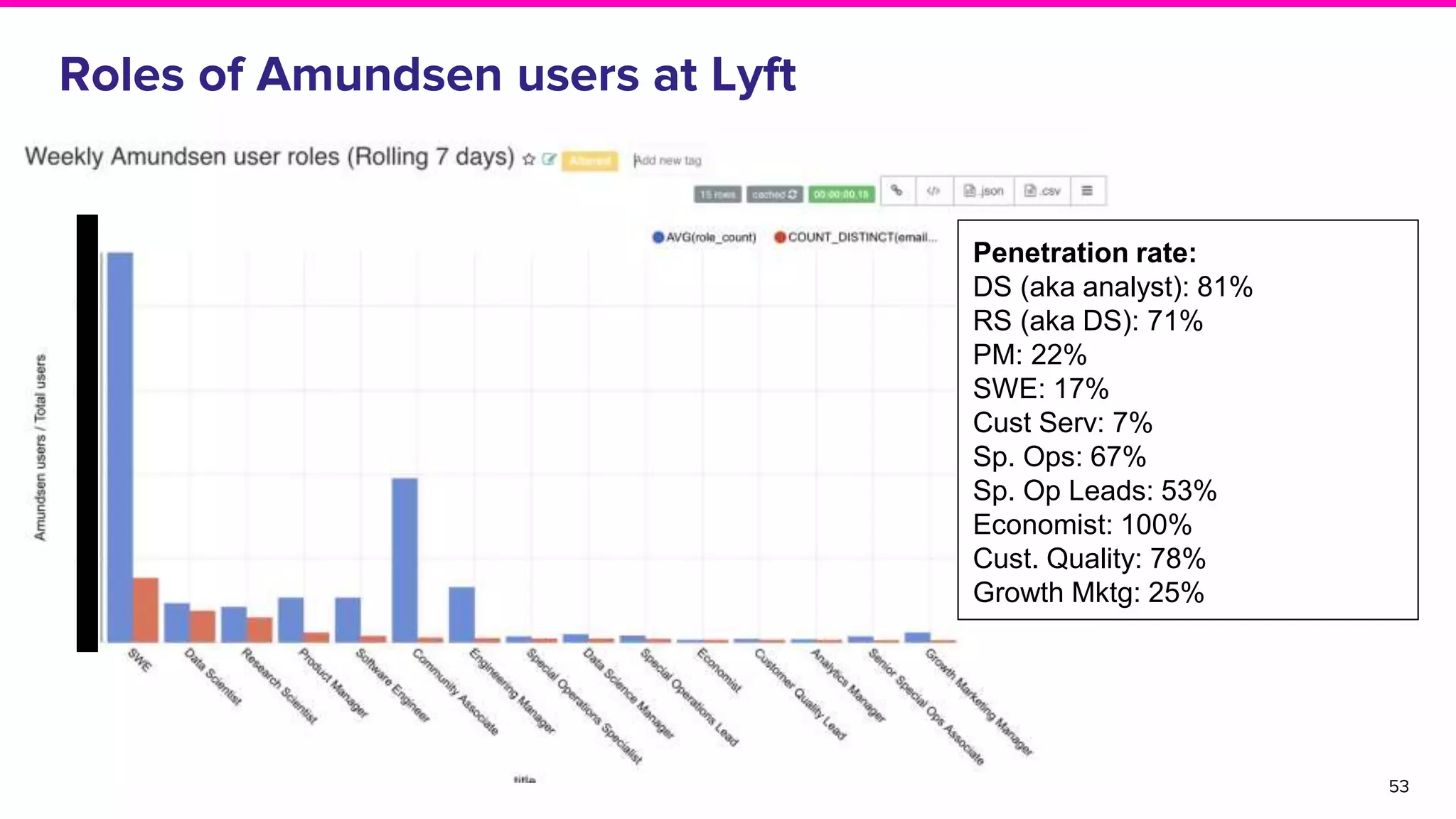
Feedback from Lyft users on Amundsen's impact on productivity and usage statistics among different user roles.
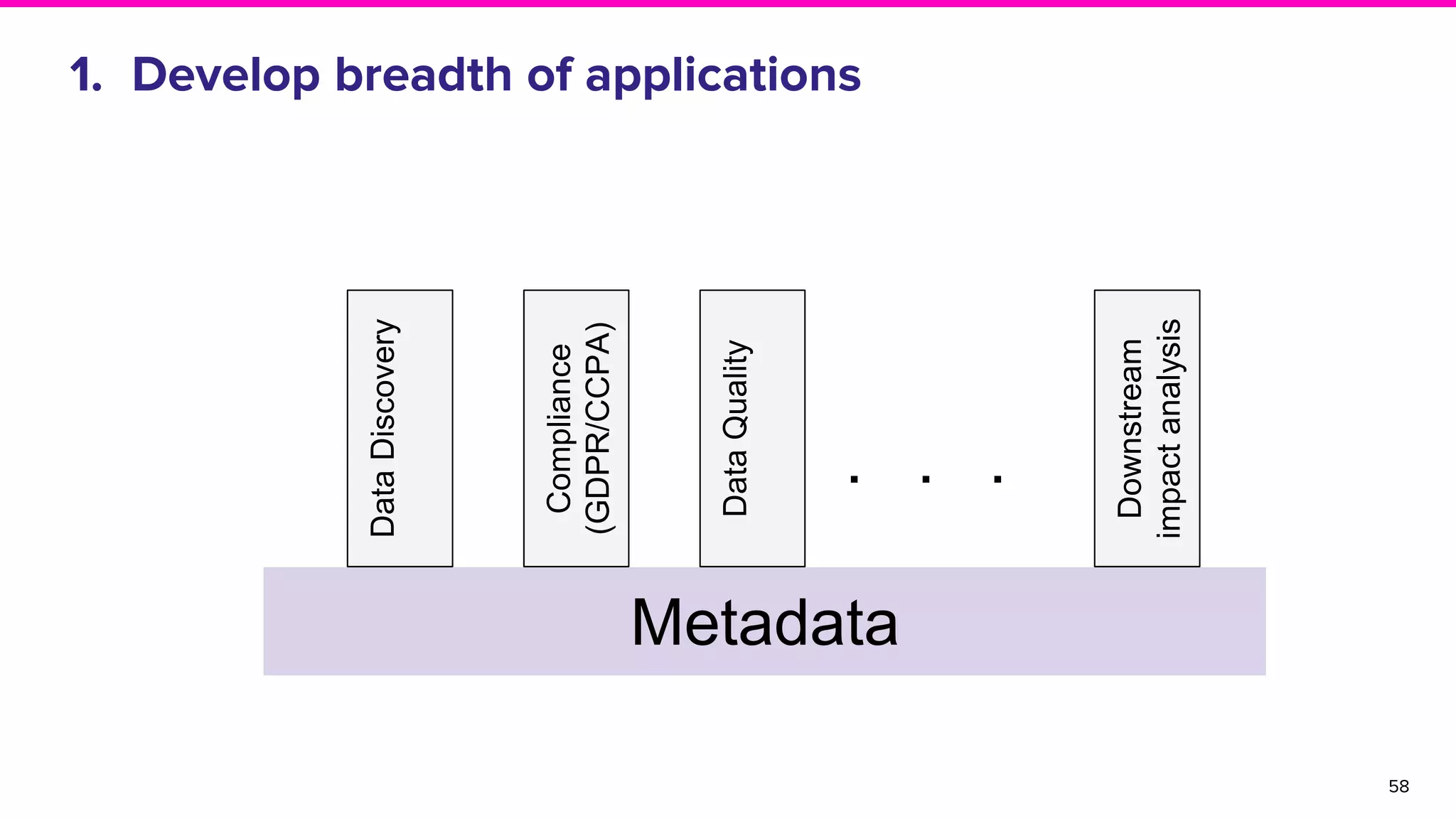
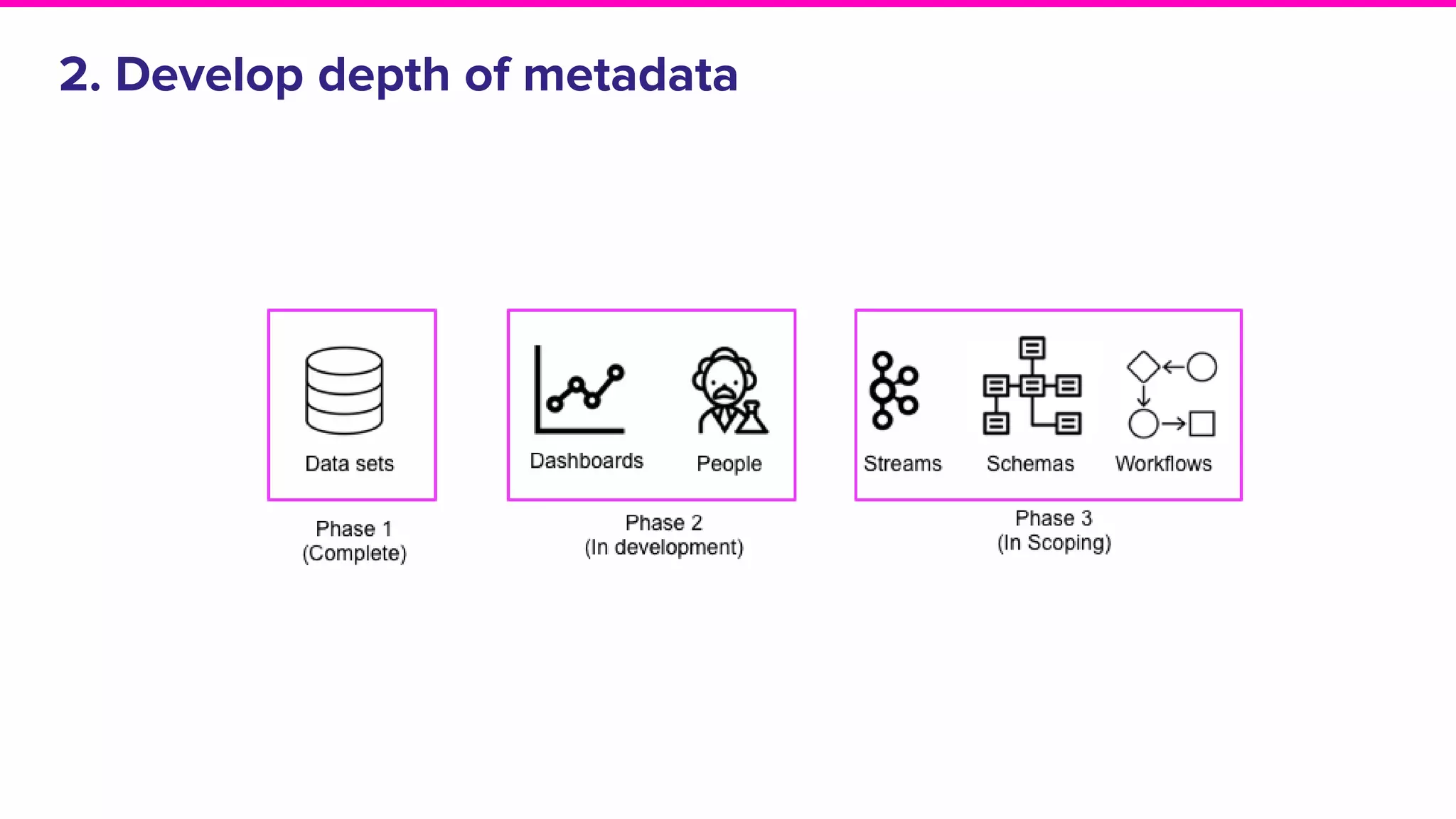
Plans for expanding applications, enhancing metadata depth, and developing a roadmap for future improvements.







![[Machine Learning 15minutes! #61] Azure OpenAI Service](https://cdn.slidesharecdn.com/ss_thumbnails/20211127ml15minazureopenaiservice-211206154233-thumbnail.jpg?width=640&height=640&fit=bounds)






![제 17회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [ztyle] : 손그림 의류 검색 서비스](https://cdn.slidesharecdn.com/ss_thumbnails/ztyle-230221082810-938747b1-thumbnail.jpg?width=640&height=640&fit=bounds)








![[메조미디어] 2022년 숏폼 콘텐츠 마케팅 리포트](https://cdn.slidesharecdn.com/ss_thumbnails/ss2022-220812054246-a3323634-thumbnail.jpg?width=640&height=640&fit=bounds)

















![[Strata NYC 2019] Turning big data into knowledge: Managing metadata and data...](https://cdn.slidesharecdn.com/ss_thumbnails/dkpstratanyc2019presentation-191004091826-thumbnail.jpg?width=640&height=640&fit=bounds)













































