Downloaded 77 times












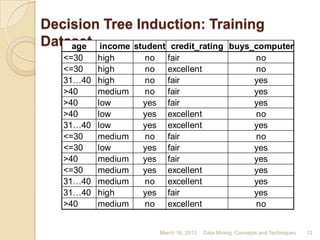



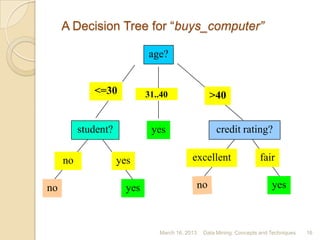




The document discusses data classification techniques. It begins with definitions of data classification and describes the learning and classification steps. It then discusses applications of data classification such as fraud detection and target marketing. Next, it covers decision tree induction as a classification technique, describing decision trees as flowchart structures and the parameters and algorithms used to construct them. Finally, it provides examples of decision tree construction and discusses future work and references.






























































