
























![26
3.5.2.1 SIFT Descriptor for Overall Description
The SIFT process generates a 128-length vector for each key point. Since SIFT
is invariant to image translation, scaling, rotation and illumination changes, and robust
to local geometric distortion, it provides valuable lung nodule data. SIFT is robust and
is able to carry out semantic classification due to its ability to capture the texture and
gradient information. Besides, it identifies the key points by computing extremum
pixels in the image local area to incorporate the intensity information. Thus, SIFT
descriptor was adopted as the first component of FS3 to give an overall description
from intensity, texture, and gradient perspectives.
In our case, we extract only one 128-length vector near the centroid of each
patch. Specially, since the shapes of the extracted patches are not uniform, we selected
the smallest rectangle sub window to cover all pixels for each patch and then ran SIFT
on this window. The final SIFT descriptor SIFT (pao)of patch pao is calculated by
selecting one key point near the centroid of the rectangle window.
3.5.2.2 MR8+LBP Descriptor for Texture Description
The combination of MR8 filters and LBP feature is designed to provide richer
texture description of patches by incorporating multi scale and rotation-invariant
properties. LBP is a powerful feature for texture based image classification.
Although LBP can be easily configured to describe the local texture structure
with multi resolution and rotation-invariance, it captures too many trivial image
variations. Therefore, we in-corporate the MR filters set before computing LBP
histogram. The MR set contains both isotropic and anisotropic filters at multiple
orientations and multiple scales and records the angle of maximum response, which
makes it possible to discriminate textures that appear to be very similar.
Specifically, MR8 bank is used in our method, which consists of 38 filters but
produces only eight filter responses by recording only the maximum filter response
across all orientations for one scale. This yields rotation invariance. The final filter
response contains two anisotropic filters for each of three different scales and two
isotropic filters (2 × 3+2). MR8 filters are directly applied to the original image. For
image I, we get eight filter responses represented by IMR8(f )where f∈ [1 , 8] .Next, as
for patch pao in image I , LBP descriptor LBP pa’o is computed for the corresponding
patch pa’o in each filter response of IMR8. As explained by Song et al., the total number](https://image.slidesharecdn.com/lungcancerwasuncommonatthebeginningofthe20thcentury-150628175701-lva1-app6891/85/A-supervised-lung-nodule-classification-method-using-patch-based-context-analysis-in-LDCT-image-26-320.jpg)












![42
REFERENCES
[1] Fan Zhan, Yang Song, Weidong Cai, Min-Zhao Lee, Yun Zhou, Heng Huang,
Shimin Shan, Michael J Fulham, and Dagan Feng “Lung nodule classification with
multi-level patch based context analysis” IEEE Transactions on Biomedical
Engineering, vol.61,no.4, April 2014.
[2] J. J. Erasmus, J. E. Connolly, H. P. McAdams, and V. L. Roggli, “Solitary
pulmonary nodules: Part I. morphologic evaluation for differentiation of benign and
malignant lesions,” Radiographic, vol. 20, no. 1, 2000.
[3] D. Wu, L. Lu, J. Bi, Y. Shinagawa, K. Boyer, A. Krishnan, and M. Salganicoff,
“Stratified learning of local anatomical context for lung nodules in CT images,” in Proc.
CVPR, 2010,
[4] R. A. Ochs, J. G. Goldin, F. Abtin, H. J. Kim, K. Brown, P. Batra, D. Roback, M. F.
McNitt-Gray, and M. S. Brown, “Automated classification of lung bronchovascular
anatomy in CT using adaboost,” Medical Image Analysis, vol. 11, no. 3, 2007.
[5] A. Farag, S. Elhabian, J. Graham, A. Farag, and R. Falk, “Toward precise
pulmonary nodule descriptors for nodule type classification,” in MICCAI LNCS, vol.
13, no. 3, 2010.
[6] A. A. Farag, “A variational approach for small-size lung nodule segmentation,” in
Proc. ISBI, 2013.
[7] D. Xu, H. J. van der Zaag-Loonen, M. Oudkerk, Y. Wang, R. Vliegenthart, E. T.
Scholten, J. Verschakelen, M. Prokop, H. J. de Koning, and R. J. van Klaveren,
“Smooth or attached solid indeterminate nodules detected at baseline CT screening in
the NELSON study: Cancer risk during 1 year of follow-up,” Radiology, vol. 250, no.
1,2009.](https://image.slidesharecdn.com/lungcancerwasuncommonatthebeginningofthe20thcentury-150628175701-lva1-app6891/85/A-supervised-lung-nodule-classification-method-using-patch-based-context-analysis-in-LDCT-image-42-320.jpg)
![43
[8] S. Diciotti, G. Picozzi, M. Falchini, M. Mascalchi, N. Villari, and G. Valli, “3-D
segmentation algorithm of small lung nodules in spiral CT images,” IEEE Trans.
Information Technology in Biomedicine, vol. 12, no. 1, 2008.
[9] B. Zhao, “Automatic detection of small lung nodules on CT utilizing a local density
maximum algorithm,” Journal of Applied Clinical Medical Physics, vol. 4, no. 3, 2003.
[10] Kakar Manish,Dag Rune Olsen,”Automatic segmentation and recognition of lungs
and lesion from CT scans of thorax”original research Article computerized Medical
Imaging and Graphics,Volume 33, Issue 1 ,January 2009.
[11] Jun-Wei LIU, Huan-Qing FENG, Ying-Yue ZHOU, Chuan-Fu LI,”A Novel
automatic extraction method of lung texture tree from HRCT images” Original
Research Article Acta Automatic Sinica, Volume 32, Issue 4, April 2009
[12]M.F.McNittGray, N.Wyckoff, J.W.Sayre, J.G.Goldin, D.R.Aberle, “The effects of
co-occurrence matrix based texture parameters on the classification of solitary
pulmonary nodules imaged on computed tomography“ original research article
computerized medical imaging and graphics, volume 23, issue 6, December 1999
[13]A. Farag, A. Ali, J. Graham, S. Elshazly, and R. Falk, “Evaluation of geometric
feature descriptors for detection and classification of lung nodules in low dose CT scans
of the chest,” in Proc. ISBI, 2011.
[14] F. Zhang, W. Cai, Y. Song, M.-Z. Lee, S. Shan, and D. Feng, “Overlapping node
discovery for improving classification of lung nodules,” in Proc. EMBC, 2013.
[15] Y. Song, W. Cai, Y. Wang, and D. Feng, “Location classification of lung nodules
with optimized graph construction,” in Proc. ISBI, 2012.
[16] S. O’Hara and B. A. Draper, “Introduction to the bag of features paradigm for
image classification and retrieval,” Computer Vision and Pattern Recognition, 2011.
[17] D. Unay and A. Ekin, “Dementia diagnosis using similar and dissimilarretrieval
items,” in Proc. ISBI, 2011.](https://image.slidesharecdn.com/lungcancerwasuncommonatthebeginningofthe20thcentury-150628175701-lva1-app6891/85/A-supervised-lung-nodule-classification-method-using-patch-based-context-analysis-in-LDCT-image-43-320.jpg)
![44
[18] Y. Song, W. Cai, Y. Zhou, L. Wen, and D. Feng, “Pathology-centric medical
image retrieval with hierarchical contextual spatial descriptor,” in Proc. ISBI, 2013.
[19] D. Unay and A. Ekin, “Dementia diagnosis using similar and dissimilar retrieval
items,” in Proc. Int. Symp. Biomed. Imag., 2011.
[20] Y. Song,W. Cai,Y. Zhou, L.Wen, andD. Feng, “Pathology-centric medical image
retrieval with hierarchical contextual spatial descriptor,” in Proc. Int. Symp. Biomed.
Imag., 2013.](https://image.slidesharecdn.com/lungcancerwasuncommonatthebeginningofthe20thcentury-150628175701-lva1-app6891/85/A-supervised-lung-nodule-classification-method-using-patch-based-context-analysis-in-LDCT-image-44-320.jpg)

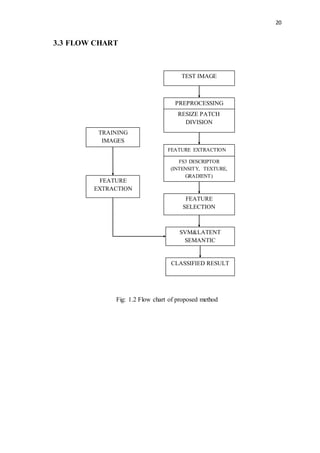
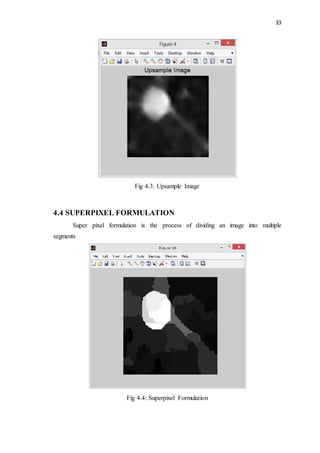
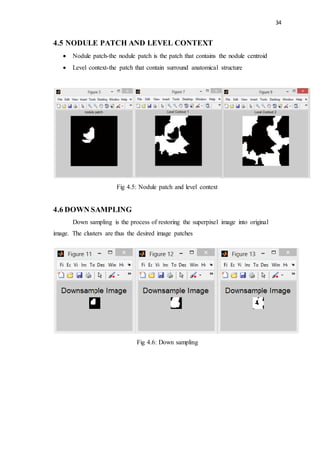
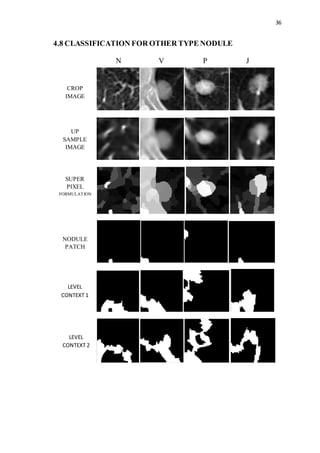
This document discusses lung nodules and digital image processing for lung cancer detection. It defines lung nodules as small masses in the lungs that can be used to identify potentially cancerous tissue. Computed tomography (CT) scans are commonly used but interpreting large numbers of scans can be challenging. Computer-aided diagnosis (CAD) systems help by automatically analyzing scans. The document then provides an overview of digital image processing, describing it as the science of manipulating digital images to extract useful information. Key steps include acquisition, preprocessing, segmentation, representation, recognition, and knowledge-based analysis.




















































































