The document presents a particle swarm inspired cuckoo search algorithm for real parameter optimization. It combines two algorithms: cuckoo search and particle swarm optimization. In cuckoo search, agents find new solutions using levy flights. The proposed algorithm adds the global best solution from particle swarm optimization to enhance exploitation. It balances exploration and exploitation through two new search strategies with random probabilities. The algorithm is tested on benchmark functions and two real-world problems, showing better performance than other algorithms.




![X. Li, M. Yin
which also forms a Markov chain whose next location only
depends on the current location and the transition probability.
The evolution phase of the xt
i begins by the donor vector
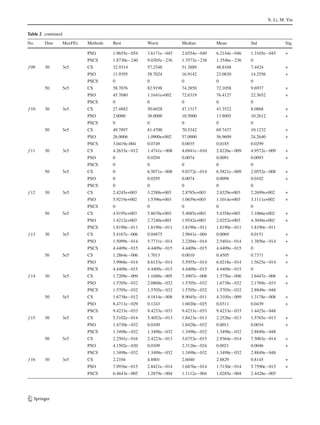
υ, where υ = xt
i . After this step, the required stepsize value
has been computed using the Eq. (3)
Stepsizej = 0.01 ·
u j
vj
1/λ
· (υ − Xbest) (3)
where u = t−λ × randn[D] and v = randn[D]. The
randn[D] function generates a Gaussian distribution. Then
the donor vector υ is random using the Eq. (4)
υ = υ + Stepsizej ∗ randn[D] (4)
After producing the new solution υi , it will be evaluated and
compared to the xi , If the objective fitness of υi is smaller
than the objective fitness of xi , υi is accepted as a new basic
solution. Otherwise xi would be obtained.
The other part of cuckoo search algorithm is to place some
nests by constructing a new solution. This crossover operator
is shown as follows:
υi =
Xi + rand · (Xr1 − Xr2) randi < pa
Xi otherwise
(5)
After producing the new solution υi , it will be evaluated and
compared to the xi . If the objective fitness of υi is smaller
than the objective fitness of xi , υi is accepted as a new basic
solution. Otherwise xi would be obtained.
Note that in the real world, a cuckoo’s egg is more difficult
to be found when it is more similar to a host’s eggs. So, the
fitness is related to the difference and that is the main reason
to use a random walk in a biased way with some random
stepsizes.
2.2 The particle swarm optimization algorithm (PSO)
PSO is fundamentally a stochastic, population-based search
algorithm which mimics organisms that interact as a swarm
such a school of fish or a swarm of bees looking for the foods.
The algorithm was first proposed by Kennedy and Eberhart
(1995)basedonthecooperationandcompetitionamongindi-
viduals to complete the search of the optimal solution in an
n-dimensional space. The standard PSO can be specifically
described as follows: during the swarm evolution, each parti-
cle has a velocity vector Vi = (vi1, vi2, . . . , vi D) and a posi-
tionvector Xi = (xi1, xi2, . . . , xi D) toguideitself toapoten-
tial optimal solution, wherei is a positive integer indexing the
particle in the swarm. The personal best position of particle
i is denoted as pbesti = (pbesti1, pbesti2, . . . , pbesti D)
and the global best position of the particle is gbest =
(gbest1, gbest2, . . . , gbestD). The velocity Vi and the posi-
tion xi are randomly initialized in the search space and they
are updated with the following formulas at the (t + 1) gen-
erations:
Vi, j (t + 1) = ωVi, j (t) + c1r1, j pbesti, j (t) − Xi, j (t)
+ c2r2, j gbestj (t) − Xi, j (t)
Xi, j (t + 1) = Xi, j (t) + Vi, j (t + 1) (6)
where i ∈ [1, 2, . . . , N P] means the ith particle in the pop-
ulation and j ∈ [1, 2, . . . , D] is the jth dimension of this
particle; NP is the population size and D is the dimension of
the searching space. c1 and c2 are acceleration constants. The
r1, j and r2, j are two random number uniformly distributed
in [0, 1]. ω is the inertia weight that is used to balance global
and local search ability.
3 Our approach: particle swarm inspired cuckoo search
algorithm (PSCS)
In this section, we will introduce our algorithm PSCS in
detail.
3.1 The new search strategy
In the standard PSO algorithm, each particle keeps the best
position pbest found by itself. Besides, we know the global
position gbest search by the group particles, and change its
velocity according to the two best positions. The high con-
vergence speed is an important feature of the original PSO
algorithm because of the usage of the global elite “gbest”
imposes a strong influence on the whole swarm. The global
best solution is used to guide the flight of the particles, as it
can be called “social learning”. In the social learning part,
the individuals’ behaviors indicate the information share and
cooperation among the swarm. The other learning part is the
cognitive learning models which make the tendency of parti-
cles to return to previously found best positions. This part can
avoid the algorithm trapping into the local optimal. Inspired
by the social learning and cognitive learning, the two learn-
ing parts are used in standard CS to find the neighborhood of
the nest. The main model of the new search strategy can be
described as follows:
υi, j (t + 1) = Xi, j (t) + ϑi, j pbesti, j (t) − Xi, j (t)
+ ϕi, j gbestj (t) − Xi, j (t) (7)
where ϑ and ϕ are the parameter of the new search method.
In other aspect, as the global best found early in the search-
ing process may be a poor local optimum; it may attract all
food sources to a bad searching area. In this case, on com-
plex multi-modal problems, the convergence speed of the
algorithm is often very high at the beginning, but only lasts
for a few generations. After that, the search will inevitably
be trapped. Therefore, on such kind of problems, it would
mislead the search towards local optima, which inhibits the
advantages of the new strategies on multi-modal problems. In
123](https://image.slidesharecdn.com/cukoosrch-150522045525-lva1-app6891/85/Cukoo-srch-4-320.jpg)
![A particle swarm inspired cuckoo search algorithm
this paper, taking into consideration these facts and to over-
come the limitations of fast but less reliable convergence
performance of the above search strategy, we propose a new
search strategy by utilizing the best vector of a group of q%
of the randomly selected population members for each target
vector that can be described as follows:
υi, j (t + 1) = Xi, j (t) + ϑi, j pbesti, j (t) − Xi, j (t)
+ ϕi, j q_gbestj (t) − Xi, j (t) (8)
where q_gbest is the best of the q% vectors randomly cho-
sen from the current population, and none of them is equal
to q_gbest. Under this method, the target solutions are not
always attracted toward the same best position found so far in
the current population, and this feature is helpful in avoiding
premature convergence at local optima. It is seen that keeping
the value of the q% is equal to the top 5 % of the population
size.
In the standard CS algorithm, two main components com-
bine the algorithm. The first component of algorithm gets
new cuckoos by random walk with Lévy flight around the so
far best nest. The required stepsize value has been computed
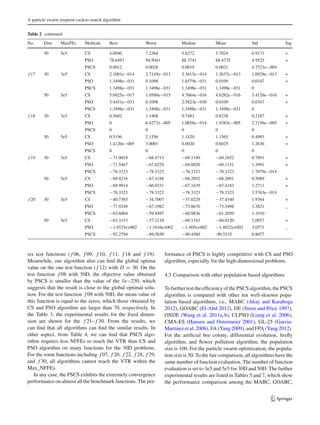
as follows:
Stepsizej = 0.01 ·
u j
vj
1/λ
· (υ − Xbest) (9)
where u = σu × randn[D] and v = randn[D]. The
randn[D] function generate an rand number between [0,1].
Then the donor vector υ can be generated as follows:
υ = υ + Stepsizej ∗ randn[D] (10)
Inspired by the new search strategy, we can modify the first
part as follows:
υ = υ + 0.01 ·
u j
vj
1/λ
· (υ − q_gbest) ∗ randn[D]
+ ϕ ∗ (Xr1 − q_gbest) (11)
wherer1 ismutuallydifferentrandomintegerindicesselected
from {1, . . . , N P}. ϕ is the parameter of this part. From the
new modified search method, we can find that the first part
shows the distance of the current individual and the global
best individual. The second part shows the distance of the
neighborhood of the current individual and the global best
individual. This new search strategy can enhance the conver-
gence rate and the diversity of the population. It can avoid
the algorithm trapping into the local optimal.
For the second component of cuckoo search algorithm,
the nest can place some nests by construct a new solution.
This crossover operator is shown as follows:
υi =
Xi + rand · (Xr1 − Xr2) randi < pa
Xi otherwise
(12)
Inspired by the new search strategy, in this section, two
improved search strategies are used in the second compo-
nent of the cuckoo search algorithm.
υi, j (t + 1) = Xi, j (t) + ϑi, j Xr1, j (t) − Xi, j (t)
υi, j (t + 1) = Xi, j (t) + ϑi, j Xr1, j (t) − Xi, j (t)
+ ϕi, j q_gbestj (t) − Xi, j (t) (13)
For the first mutation strategy, it is able to maintain popula-
tion diversity and global search capability, but it slows down
the convergence of CS algorithms. For the second mutation
strategy, the best solution in the current population is very
useful information that can explore the region around the best
vector. Besides, it also favors exploitation ability since the
new individual is strongly attracted around the current best
vector and at same time enhances the convergence speed.
However, it is easy to trap into the local minima. Based on
these two new search strategies, the new crossover strategy
is embedded into the cuckoo search algorithm and it is com-
bined with these two new search strategies through a random
probability rule as follows:
If rand > 0.5 Then
υi, j (t + 1) = Xi, j (t) + ϑi, j Xr1, j (t) − Xi, j (t)
Else
υi, j (t + 1) = Xi, j (t) + ϑi, j Xr1, j (t) − Xi, j (t)
+ ϕi, j q_gbestj (t) − Xi, j (t)
End If (14)
It can be found that one of the two strategies is used to
produce the current individual relative to a uniformly distrib-
uted random value within the range (0, 1). Hence, based on
the random probability rule and two new search methods, the
algorithm can balance the exploitation and exploration in the
search space.
3.2 Boundary constraints
The PSCS algorithm assumes that the whole population
should be in an isolated and finite space. During the search-
ing process, if there are some individuals that will move out
of bounds of the space, the original algorithm stops them
on the boundary. In other words, the nest will be assigned
a boundary value. The disadvantage is that if there are too
many individuals on the boundary, and especially when there
exists some local minimum on the boundary, the algorithm
will lose its population diversity to some extent. To tackle
this problem, we proposed the following repair rule:
xi =
⎧
⎨
⎩
2 ∗ li − xi if xi < li
2 ∗ ui − xi if xi > ui
xi otherwise
(15)
123](https://image.slidesharecdn.com/cukoosrch-150522045525-lva1-app6891/85/Cukoo-srch-5-320.jpg)


![X. Li, M. Yin
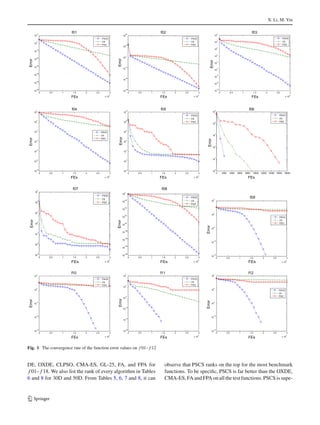
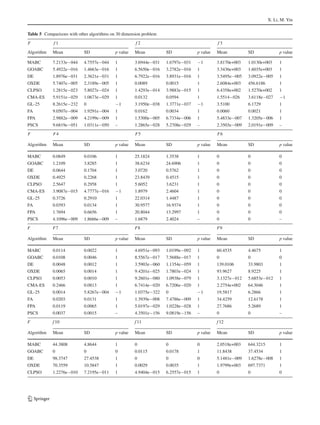
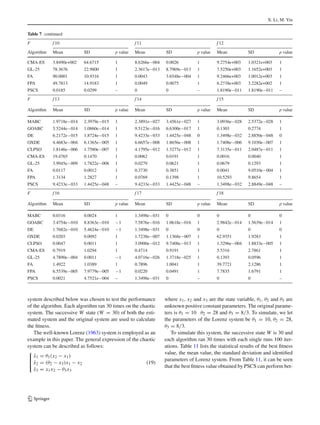
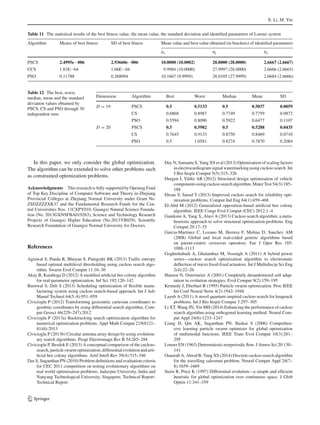
Table 1 Benchmark functions based in our experimental study
Test function Range Optimum
f01 = D
i=1 x2
i [−100,100] 0
f02 = D
i=1 |xi | + D
i=1 |xi | [−10,10] 0
f03 = D
i=1 ( i
j=1 x j )
2
[−100, 100] 0
f04 = maxi {|xi | , 1 ≤ i ≤ D} [−100, 100] 0
f05 = D−1
i=1 [100(xi+1 − x2
i )2 + (xi − 1)2] [−30, 30] 0
f06 = D
i=1 ( xi + 0.5 )2
[−100, 100] 0
f07 = D
i=1 ix4
i + random[0, 1) [−1.28, 1.28] 0
f08 = D
i=1 |x|(i+1)
[−1, 1] 0
f09 = D
i=1 [x2
i − 10 cos(2πxi ) + 10] [−5.12, 5.12] 0
f10 = D
i=1 [y2
i − 10 cos(2πyi ) + 10] [−5.12, 5.12] 0
yi =
xi |xi | < 1
2
round(2xi )
2 |xi | ≥ 1
2
f11 = 1
400
D
i=1 x2
i − D
i=1 cos( xi√
i
) + 1 [−600, 600] 0
f12 = 418.9828872724338 × D + D
i=1 −xi sin
√
|xi | [−500, 500] 0
f13 = −20 exp −0.2 1
D
D
i=1 x2
i − exp 1
D
D
i=1 cos 2πxi + 20 + e [−32, 32] 0
f14 = π
D 10 sin2(πyi ) + D−1
i=1 (yi − 1)2
[1 + 10 sin2(πyi + 1)]
+(yD − 1)2 + D
i=1 u(xi , 10, 100, 4)
[−50, 50] 0
yi = 1 + xi +1
4 u(xi , a, k, m) =
⎧
⎨
⎩
k(xi − a)m
0
k(−xi − a)m
xi > a
−a < xi < a
xi < −a
f15 = 0.1 10 sin2(πyi ) + D−1
i=1 (yi − 1)2[1 + 10 sin2(πyi + 1)] + (yD − 1)2 + D
i=1 u(xi , 10, 100, 4) [−50, 50] 0
f16 = D
i=1 |xi · sin(xi ) + 0.1xi | [−10, 10] 0
f17 = D
i=1 (xi − 1)2
1 + sin2(3πxi+1) + sin2(3πx1) + |xD − 1| 1 + sin2(3πxn) [−10, 10] 0
f18 = D
i=1
kmax
k=0 ak cos(ak cos(2πbk(xi + 0.5))) − D kmax
k=0 ak cos(2πbk0.5) , a = 0.5, b = 3,
kmax = 20
[−0.5, 0.5] 0
f19 = 1
D
D
i=1 x4
i − 16x2
i + 5xi [−5, 5] −78.33236
f20 = − D
i=1 sin(xi ) sin20 i×x2
i
π [0,π ] −99.2784
f21 = 1
500 + 25
j=1
1
j+ 2
i=1 (xi −ai j )6
−1
[−65.53, 65.53] 0.998004
f22 = 11
i=1 ai −
x1(b2
i +bi xi )
b2
i +b1x3+x4
2
[−5, 5] 0.0003075
f23 = 4x2
1 − 2.1x4
i + 1
3 x6
1 + x1x2 − 4x2
2 + 4x4
2 [−5,5] −1.0316285
f24 = x2 − 5.1
4π2 x2
1 + 5
π x1 − 6
2
+ 10(1 − 1
8π ) cos x1 + 10 [−5, 10]*[0, 15] 0.398
f25 = 1 + (x1 + x2 + 1)2(19 − 14x1 + 3x2
1 − 14x2 + 6x1x2 + 3x2
2 )
×[30 + (2x1 − 3x2)2(18 − 32x1 + 12x2
1 + 48x2 − 36x1x2 + 27x2
2 )]
[−5, 5] 3
f26 = − 4
i=1 ci exp(− 3
j=1 ai j (x j − pi j )2
) [0, 1] −3.86
f27 = − 4
i=1 ci exp(− 6
j=1 ai j (x j − pi j )2
) [0, 1] −3.32
f28 = − 5
i=1 [(X − ai )(X − ai )T + ci ]
−1
[0, 10] −10.1532
f29 = − 7
i=1 [(X − ai )(X − ai )T + ci ]
−1
[0, 10] −10.4029
f30 = − 10
i=1 [(X − ai )(X − ai )T + ci ]
−1
[0, 10] −10.5364
123](https://image.slidesharecdn.com/cukoosrch-150522045525-lva1-app6891/85/Cukoo-srch-8-320.jpg)