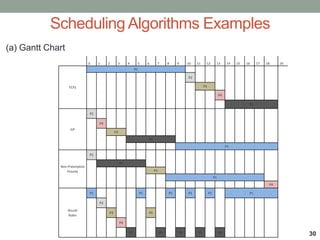
The document discusses CPU scheduling techniques used in operating systems to improve CPU utilization. It describes how multiprogramming allows multiple processes to share the CPU by switching between processes when one is waiting for I/O. Common scheduling algorithms like first-come first-served (FCFS), priority scheduling, round robin, and shortest job first are explained. The goal of scheduling is to maximize throughput and minimize average wait times for processes.