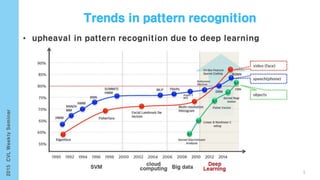
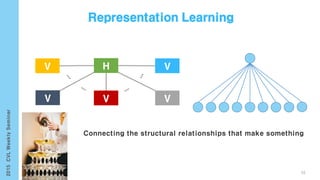
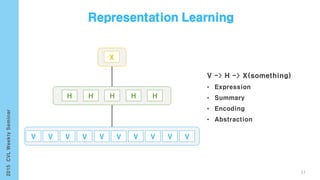
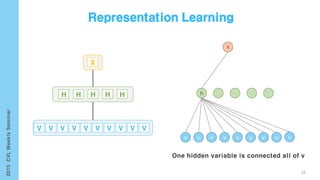
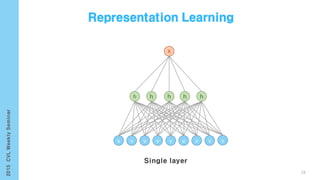
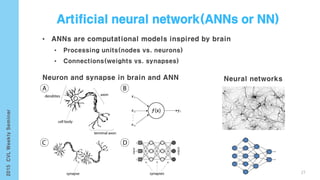
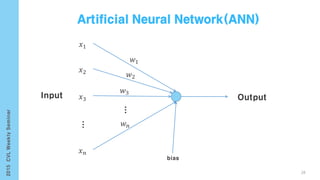
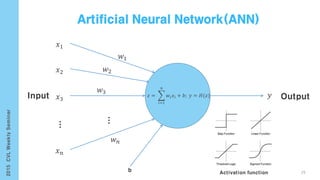
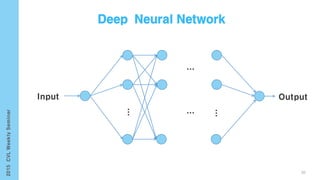
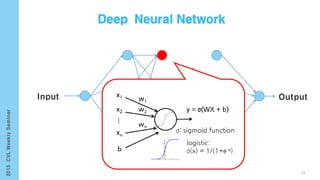
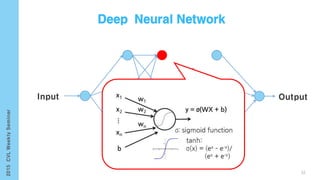
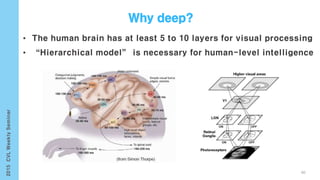
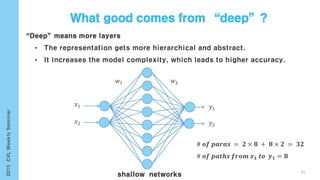
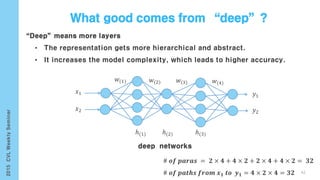
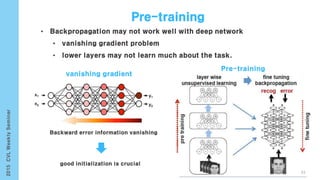
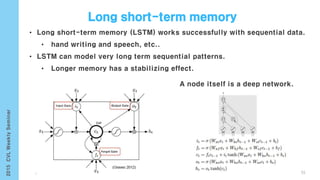
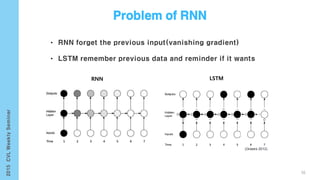
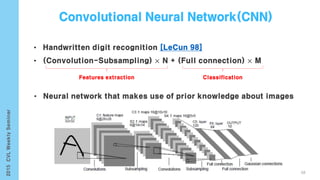
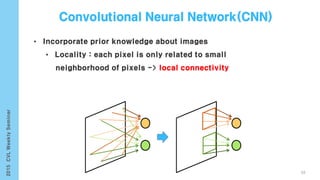
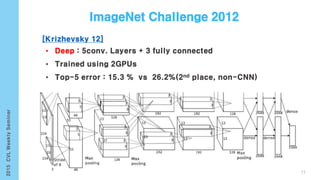
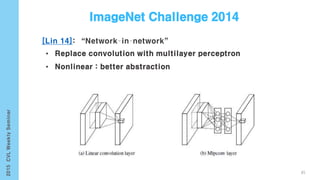
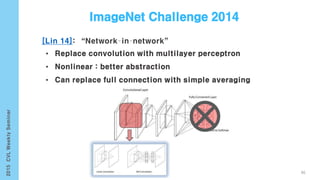
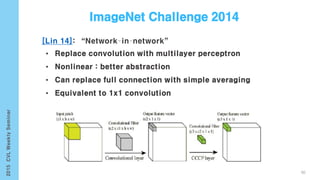
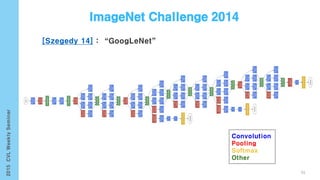
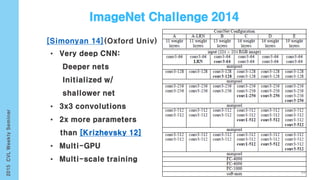
This document provides an overview of the history and development of deep learning and neural networks. It discusses early work in the 1940s-1950s on neural networks and perceptrons. It then covers the development of backpropagation and multi-layer perceptrons in the 1980s which enabled training of deeper models. Recent advances discussed include deep neural networks in 2006 and the shift from shallow to deep learning models around 2006. The document also examines recurrent neural networks, LSTMs, word embeddings, and convolutional neural networks as well as applications in computer vision like image captioning.
















![𝑥 𝑡
ℎ 𝑡
=
𝑥0
ℎ0
𝑥2
ℎ2
𝑥1
ℎ1
𝑥 𝑡
ℎ 𝑡
…
[http://karpathy.github.io/2015/05/21/rnn-effectiveness]53](https://image.slidesharecdn.com/computervisionlabseminardeeplearningyonghoon-150925004127-lva1-app6892/85/Computer-vision-lab-seminar-deep-learning-yong-hoon-53-320.jpg)
![• Bidirection Neural Network utilize in the past and future context for
every point in the sequence
• Two Hidden Layer(Forwards and Backwards) shared same output layer
Visualized of the amount of input information for prediction by different network structures
[Schuster 97]
54](https://image.slidesharecdn.com/computervisionlabseminardeeplearningyonghoon-150925004127-lva1-app6892/85/Computer-vision-lab-seminar-deep-learning-yong-hoon-54-320.jpg)
![ℎ 𝑡−1(𝑝𝑟𝑒𝑣 𝑟𝑒𝑠𝑢𝑙𝑡)
𝜎
𝑥 𝑡(𝑐𝑢𝑟𝑟𝑒𝑛𝑡 𝑑𝑎𝑡𝑎)
𝐶𝑡−1 𝐶𝑡
𝑓𝑡 = 𝜎(𝑊𝑓 ∙ ℎ 𝑡−1, 𝑥 𝑡 + 𝑏𝑓)
𝑓𝑡
[http://colah.github.io/posts/2015-08-Understanding-LSTMs]
57](https://image.slidesharecdn.com/computervisionlabseminardeeplearningyonghoon-150925004127-lva1-app6892/85/Computer-vision-lab-seminar-deep-learning-yong-hoon-57-320.jpg)
![ℎ 𝑡−1(𝑝𝑟𝑒𝑣 𝑟𝑒𝑠𝑢𝑙𝑡)
𝜎
𝑥 𝑡(𝑐𝑢𝑟𝑟𝑒𝑛𝑡 𝑑𝑎𝑡𝑎)
𝐶𝑡−1 𝐶𝑡
𝑖 𝑡 = 𝜎(𝑊𝑖 ∙ ℎ 𝑡−1, 𝑥 𝑡 + 𝑏𝑖)
𝜎
𝑓𝑡
𝑖 𝑡
𝑡𝑎𝑛ℎ
𝐶𝑡
𝐶𝑡 = 𝑡𝑎𝑛ℎ(𝑊𝑐 ∙ ℎ 𝑡−1, 𝑥 𝑡 + 𝑏 𝑐)
58
[http://colah.github.io/posts/2015-08-Understanding-LSTMs]](https://image.slidesharecdn.com/computervisionlabseminardeeplearningyonghoon-150925004127-lva1-app6892/85/Computer-vision-lab-seminar-deep-learning-yong-hoon-58-320.jpg)
![ℎ 𝑡−1(𝑝𝑟𝑒𝑣 𝑟𝑒𝑠𝑢𝑙𝑡)
𝜎
𝑥 𝑡(𝑐𝑢𝑟𝑟𝑒𝑛𝑡 𝑑𝑎𝑡𝑎)
𝐶𝑡−1 𝐶𝑡
𝐶𝑡 = 𝑓𝑡 ∗ 𝐶𝑡−1 + 𝑖 𝑡 ∗ 𝐶𝑡
𝜎
𝑓𝑡
𝑖 𝑡
𝑡𝑎𝑛ℎ
𝐶𝑡
ⅹ
+ⅹ
59
[http://colah.github.io/posts/2015-08-Understanding-LSTMs]](https://image.slidesharecdn.com/computervisionlabseminardeeplearningyonghoon-150925004127-lva1-app6892/85/Computer-vision-lab-seminar-deep-learning-yong-hoon-59-320.jpg)
![ℎ 𝑡−1(𝑝𝑟𝑒𝑣 𝑟𝑒𝑠𝑢𝑙𝑡)
𝜎
𝑥 𝑡(𝑐𝑢𝑟𝑟𝑒𝑛𝑡 𝑑𝑎𝑡𝑎)
𝐶𝑡−1 𝐶𝑡
𝑂𝑡 = 𝜎(𝑊𝑜 ∙ ℎ 𝑡−1, 𝑥 𝑡 + 𝑏 𝑜)
𝜎
𝑓𝑡
𝑖 𝑡
𝑡𝑎𝑛ℎ
𝐶𝑡
ⅹ
+ⅹ
𝜎
ⅹ
𝑡𝑎𝑛ℎ
ℎ 𝑡
ℎ 𝑡
ℎ 𝑡 = 𝑂𝑡 ∗ 𝑡𝑎nh(𝐶𝑡)
60
[http://colah.github.io/posts/2015-08-Understanding-LSTMs]](https://image.slidesharecdn.com/computervisionlabseminardeeplearningyonghoon-150925004127-lva1-app6892/85/Computer-vision-lab-seminar-deep-learning-yong-hoon-60-320.jpg)
![61
• Dropout operator only to non-recurrent connections
[Zaremba14]
Arrow dash applied dropout otherwise solid line is not applied
ℎ 𝑡
𝑙
: hidden state in layer 𝑙 in timestep 𝑡.
dropout operator
Frame-level speech recognition accuracy](https://image.slidesharecdn.com/computervisionlabseminardeeplearningyonghoon-150925004127-lva1-app6892/85/Computer-vision-lab-seminar-deep-learning-yong-hoon-61-320.jpg)
![decode
encode
V1
W1
X2
X1
X1
V1
W1
X2
X1
X1
X2
V2
W2
X3
• Regress from observation to itself (input X1 -> output X1)
• ex : data compression(JPEG etc..)
[Lemme 10]
62
output
hidden
input](https://image.slidesharecdn.com/computervisionlabseminardeeplearningyonghoon-150925004127-lva1-app6892/85/Computer-vision-lab-seminar-deep-learning-yong-hoon-62-320.jpg)
![0 1 0 0…
0.05 0.7 0.5 0.01…
0.9 0.1 10−8…10−4
cow dog cat bus
original target
output of ensemble
[Hinton 14]
Softened outputs reveal the dark knowledge in the ensemble
dog
dog
training result
cat buscow
dog cat buscow
63](https://image.slidesharecdn.com/computervisionlabseminardeeplearningyonghoon-150925004127-lva1-app6892/85/Computer-vision-lab-seminar-deep-learning-yong-hoon-63-320.jpg)
![• Distribution of the top layer has more information.
• Model size in DNN can increase up to tens of GB
input
target
input
output
Training a DNN
Training a shallow network
64
[Hinton 14]](https://image.slidesharecdn.com/computervisionlabseminardeeplearningyonghoon-150925004127-lva1-app6892/85/Computer-vision-lab-seminar-deep-learning-yong-hoon-64-320.jpg)
![65
0 1 0 0 0 0 0 0 0 0dog
0 0 1 0 0 0 0 0 0 0cat
• Word embedding 𝑊: 𝑤𝑜𝑟𝑑𝑠 → ℝ 𝑛 function mapping to high-dimensional vectors
0.3 0.2 0.1 0.5 0.7dog
0.2 0.8 0.3 0.1 0.9cat
one hot vector representation
[Vinyals 14]
Nearest neighbors a few words
Word Embedding](https://image.slidesharecdn.com/computervisionlabseminardeeplearningyonghoon-150925004127-lva1-app6892/85/Computer-vision-lab-seminar-deep-learning-yong-hoon-65-320.jpg)


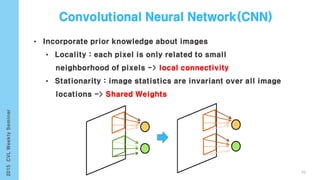
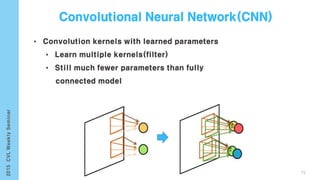

















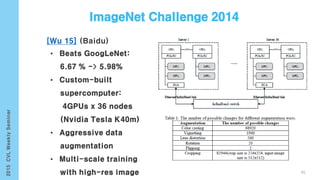





![[Karpathy 14]
[Girshick 13]
• Generate dense, free-from descriptions of images
Infer region word alignments use to R-CNN + BRNN + MRF
101
Image Segmentation(Graph Cut + Disjoint union)](https://image.slidesharecdn.com/computervisionlabseminardeeplearningyonghoon-150925004127-lva1-app6892/85/Computer-vision-lab-seminar-deep-learning-yong-hoon-101-320.jpg)
![[Karpathy 14]
Infer region word alignments use to R-CNN + BRNN + MRF
102
𝑆 𝑘𝑙 =
𝑡∈𝑔 𝑙 𝑖∈𝑔 𝑘
𝑚𝑎𝑥(0, 𝑣𝑖
𝑇
𝑆𝑡)
Result BRNN
Result RNN
𝑔𝑙
𝑔 𝑘
• 𝑆𝑡 and 𝑣𝑖 with their additional
Multiple Instance Learning
hⅹ4096 maxrix(h is 1000~1600)
t-dimensional word dictionary](https://image.slidesharecdn.com/computervisionlabseminardeeplearningyonghoon-150925004127-lva1-app6892/85/Computer-vision-lab-seminar-deep-learning-yong-hoon-102-320.jpg)
![[Karpathy 14]
103
𝐸 𝑎1, . . , 𝑎 𝑛 = 𝑎 𝑗=𝑡
−𝑠𝑖𝑚𝑖𝑙𝑎𝑟𝑖𝑡𝑦(𝑤𝑗, 𝑟𝑡) + 𝑗=1..𝑁−1 𝛽[𝑎𝑗 = 𝑎𝑗+1]
Smoothing with an MRF
• Best region independently align each other
• Similarity regions are arrangement nearby
• Argmin can found dynamic programming
(word, region)](https://image.slidesharecdn.com/computervisionlabseminardeeplearningyonghoon-150925004127-lva1-app6892/85/Computer-vision-lab-seminar-deep-learning-yong-hoon-103-320.jpg)

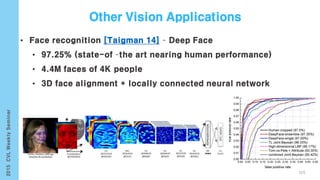


![• Divided to five part of human body(two arms, two legs, trunk)
• Modeling movements of these individual part and layer composed of 9
layers(BRNN, fusion layer, fully connection layer)
[Yong 15]
108](https://image.slidesharecdn.com/computervisionlabseminardeeplearningyonghoon-150925004127-lva1-app6892/85/Computer-vision-lab-seminar-deep-learning-yong-hoon-108-320.jpg)















































![ujava.org workshop : Deep Learning [2015-03-08]](https://cdn.slidesharecdn.com/ss_thumbnails/ujava-150316035315-conversion-gate01-thumbnail.jpg?width=640&height=640&fit=bounds)









































