Downloaded 517 times












































![TRAINING
PHASE
X
Pre-trained VGG-
16
[3x224x224]
Wih](https://image.slidesharecdn.com/imagecaptioning-190720133200/85/Image-captioning-46-320.jpg)




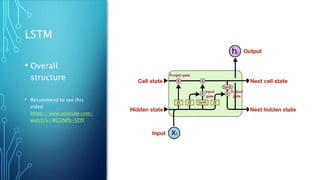



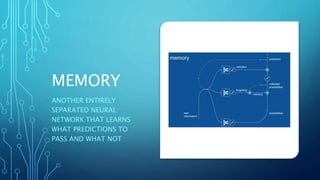

















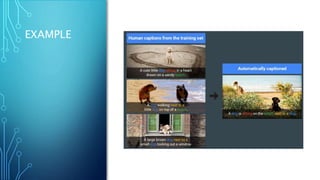
The document discusses image captioning using deep neural networks. It begins by providing examples of how humans can easily describe images but generating image captions with a computer program was previously very difficult. Recent advances in deep learning, specifically using convolutional neural networks (CNNs) to recognize objects in images and recurrent neural networks (RNNs) to generate captions, have enabled automated image captioning. The document discusses CNN and RNN architectures for image captioning and provides examples of pre-trained models that can be used, such as VGG-16.



































































