큰 그림
쉬운 문제부터잘 풀고 조금씩 확장
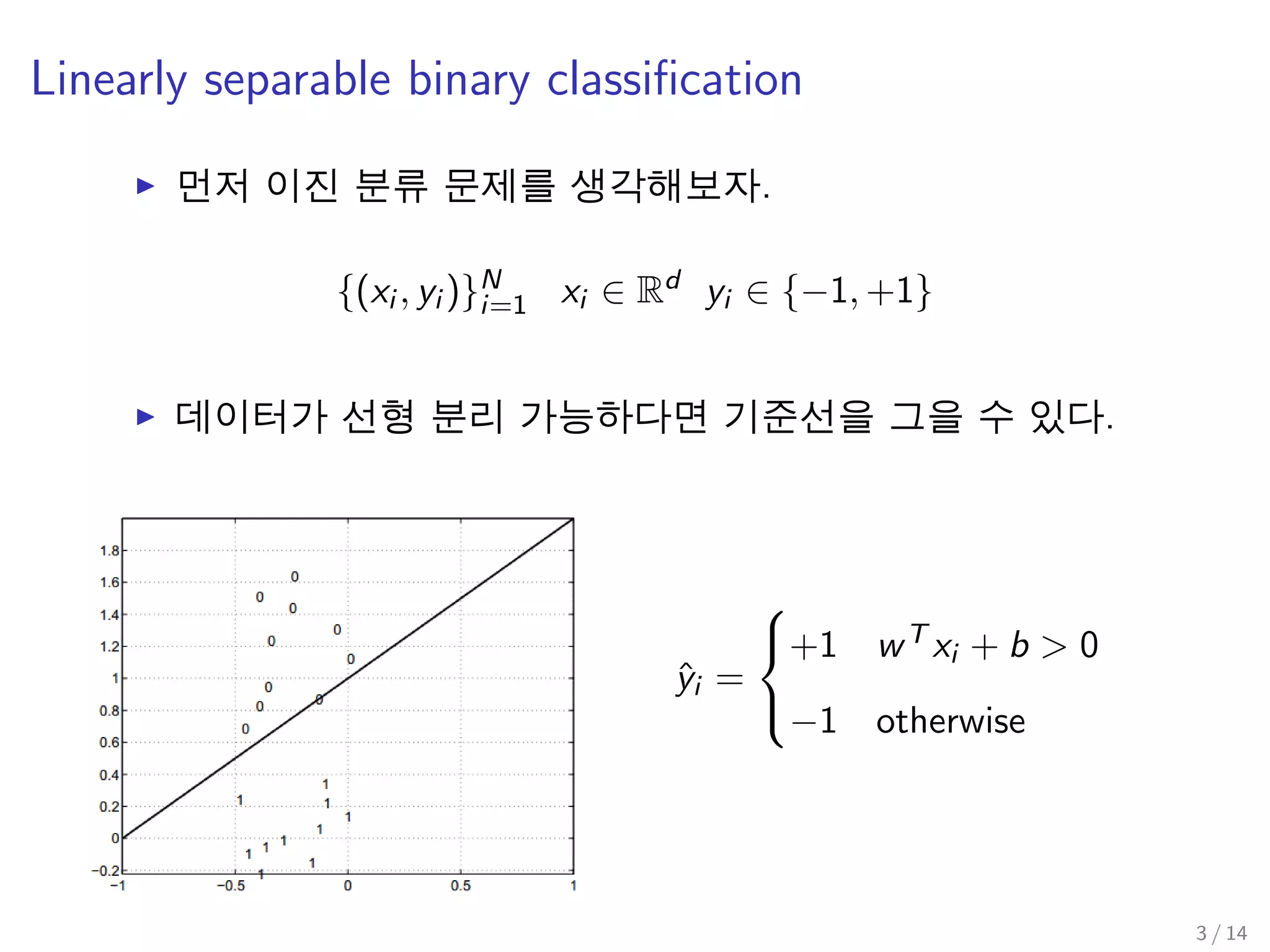
Linearly separable binary classification 문제부터 풀어보자.
Solution: Maximal margin classifer ⇒ Linear SVM
Non-linearly separable 경우도 풀고 싶다. ⇒ Kernel trick
잡음, 오차 등이 끼어들면 어떡하지? ⇒ Regularization
n-class classification 문제도 풀고 싶다. ⇒ Multiclass SVM
Regression 문제도 풀고 싶다. ⇒ Support vector regression
Structure prediction 문제도 풀고 싶다. ⇒ Structured SVM
2 / 14
3.
Linearly separable binaryclassification
먼저 이진 분류 문제를 생각해보자.
{(xi , yi )}N
i=1 xi ∈ Rd yi ∈ {−1, +1}
데이터가 선형 분리 가능하다면 기준선을 그을 수 있다.
ˆyi =
+1 wT xi + b > 0
−1 otherwise
3 / 14
4.
Linearly separable binaryclassification (cont’d)
어떤 선을 그을까?
1. 두 점 잡아서 수직이등분선 긋기 (?)
2. Perceptron: 일단 하나 긋고 예측 오차 계산해서 데이터에
맞게 점점 수렴해가기
3. Logistic regression: p(yi |xi )를 로지스틱 형태로 가정 후
maximum likelihood 추정. convex하기 때문에 stochastic
gradient descent로 빠르게 구할 수 있다.
4. Fisher’s linear discriminant: 각 class 별로 평균과 공분산을
구한 후, σ2
between/σ2
within을 최대로 하는 선 긋기
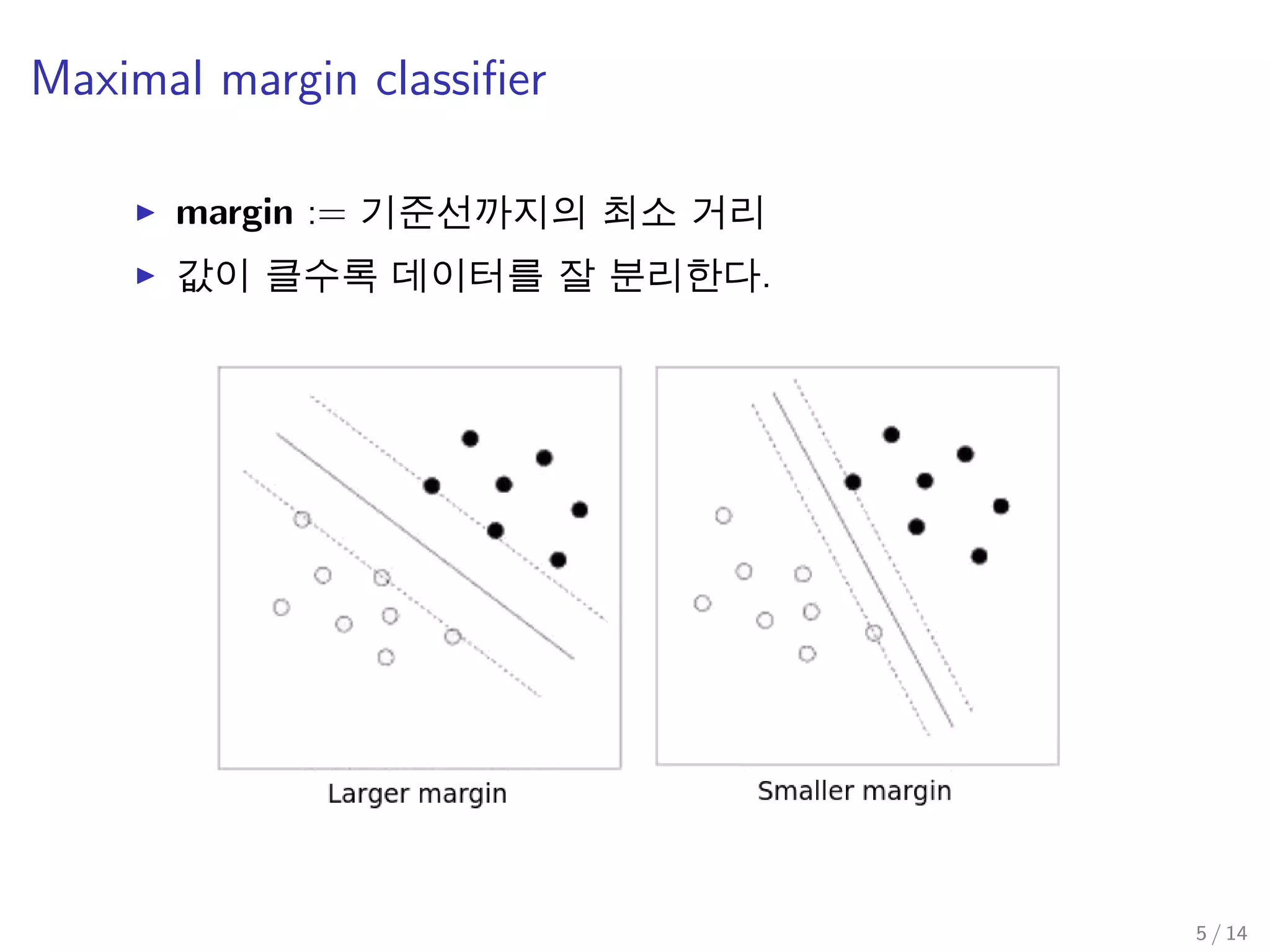
5. Maximal margin classifer: margin을 최대로 하는 선 긋기
4 / 14
Maximal margin classifier(cont’d)
i.e., maximize w −1 subject to yi (wT xi + b) ≥ 1
maximize w −1를 minimize 1
2wT w로 바꾸자.
라그랑지 승수법으로 풀 수 있다.
L =
1
2
wT
w +
N
i=1
λi (1 − yi (wT
xi + b)),
∂L
∂w
= 0
min
w
max
λ
L(w, b, λ) s.t. λi ≥ 0
6 / 14
7.
Maximal margin classifier(cont’d)
Dual problem*:
max
λ
min
w
L(w, b, λ)
미분해서 식을 잘 정리하면:
maximize
i
λi −
1
2
i j
λi λj yi yj xT
i xj
subject to λi ≥ 0,
i
λi yi = 0
Quadratic programming!
7 / 14
8.
Support vectors
앞에서 QP로얻어진 λi 로부터 w와 b를 계산하자.
w = i λi yi xi
For b, Let g(xi ) = 1 − yi (wT xi + b).
KKT conditions say ∀i λi g(xi ) = 0.
∴ b = yi − wT xi for some i such that λi > 0
이 때 b를 계산해주는 xi 들을 support vectors라고 부른다.
이제 알고리즘을 확장해서 다른 문제들도 풀어보자.
8 / 14
9.
Kernel trick
적당한 mappingφ : Rd → Rn을 통해 Linearly seperable
문제로 바꿀 수 있는 경우, 앞선 QP 식에서 xi , xj 대신
φ(xi ), φ(xj ) 로 바꾸어 풀면 된다.
이 때 함수 K(x, y) := φ(x), φ(y) 형태를 미리 알고 있다면
φ로 mapping을 하지 않고도 빠르게 계산할 수 있다.
이런 K(x, y)를 kernel이라 부른다.
좋은 점 (Mercer 정리): ∃φ s.t. K(x, y) = φ(x), φ(y) iff
K(x, y)가 positive semidefinite
예를 들어 RBF kernel K(x, y) = exp(−1
2 x − y
2
)에
대응되는 φ는 Rd → R∞
9 / 14
10.
Regularization
앞선 SVM은 잡음,오차 등의 outliers에 취약하다.
slack term ei 을 집어넣어서 해결하자.
최적화 문제가 다음과 같이 바뀐다.
minimize
1
2
wT
w + C ei
subject to yi (wT
xi + b) ≥ 1 − ei , ei ≥ 0
여기서 C는 얼마나 많은 오차를 허용할 것인지 결정한다.
10 / 14
11.
Regularization (cont’d)
다시 라그랑지승수법에 듀얼을 취해 식을 정리하면
maximize
i
λi −
1
2
i j
λi λj yi yj xT
i xj
subject to 0 ≤ λi ≤ C,
i
λi yi = 0
이전과 비교하면 constraints에 λi ≤ C 가 추가되었다.
Sequential minimal optimization으로 빠르게 풀 수 있다.
11 / 14
Regression
f (x) =wT x + b로 모델링.
오차를 > 0 이내로 하면서 가장 평평한 함수를 찾는다.
minimize
1
2
wT
w
subject to − ≤ yi − (wT
xi + b) ≤
앞과 같이 라그랑지 승수법에 듀얼을 취한 후 QP를 푼다.
13 / 14
14.
Structured SVM
SVM은 trees,sequences 같은 structure도 학습할 수 있다.
Regularized risk function minimization as QP
minimize
1
2
wT
w + C ei
subject to wT
Ψ(xi , yi ) − wT
Ψ(xi , y) + ei ≥ ∆(yn, y) ∀y
Ψ : X × Y → Rd : feature function
∆ : Y × Y → R+: loss function
학습 후 예측은
y∗
= argmin
y∈Y
wT
Ψ(x, y)
14 / 14




















![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 5장. 서포트 벡터 머신](https://cdn.slidesharecdn.com/ss_thumbnails/handson-mlch-180905033306-thumbnail.jpg?width=640&height=640&fit=bounds)

![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 4장. 모델 훈련](https://cdn.slidesharecdn.com/ss_thumbnails/handson-mlch-180814064959-thumbnail.jpg?width=640&height=640&fit=bounds)
![[홍대 머신러닝 스터디 - 핸즈온 머신러닝] 2장. 머신러닝 프로젝트 처음부터 끝까지](https://cdn.slidesharecdn.com/ss_thumbnails/handon-mlch-180710075557-thumbnail.jpg?width=640&height=640&fit=bounds)


![[신경망기초] 신경망의시작-퍼셉트론](https://cdn.slidesharecdn.com/ss_thumbnails/nn02-180318141341-thumbnail.jpg?width=640&height=640&fit=bounds)














![[공간정보시스템 개론] L06 GIS의 이해](https://cdn.slidesharecdn.com/ss_thumbnails/l06gis-170314114559-thumbnail.jpg?width=640&height=640&fit=bounds)

![[공간정보시스템 개론] L07 원격탐사의 개념과 활용](https://cdn.slidesharecdn.com/ss_thumbnails/l07-170314114620-thumbnail.jpg?width=640&height=640&fit=bounds)
![[공간정보시스템 개론] L08 gnss의 개념과 활용](https://cdn.slidesharecdn.com/ss_thumbnails/l08gnss-170314114625-thumbnail.jpg?width=640&height=640&fit=bounds)
![[공간정보시스템 개론] L05 우리나라의 수치지도](https://cdn.slidesharecdn.com/ss_thumbnails/l05-170314114527-thumbnail.jpg?width=640&height=640&fit=bounds)

![[F2]자연어처리를 위한 기계학습 소개](https://cdn.slidesharecdn.com/ss_thumbnails/f2-120919022113-phpapp02-thumbnail.jpg?width=640&height=640&fit=bounds)




















![[한글] Tutorial: Sparse variational dropout](https://cdn.slidesharecdn.com/ss_thumbnails/tutorialsparsevariationaldropout-190728122300-thumbnail.jpg?width=640&height=640&fit=bounds)








