Download as PDF, PPTX





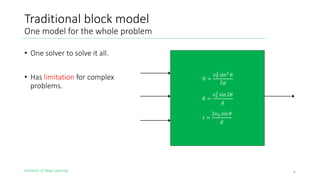
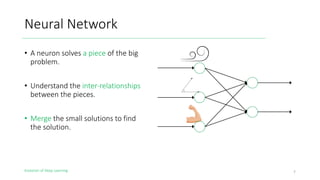
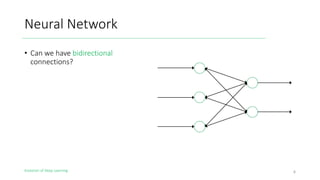
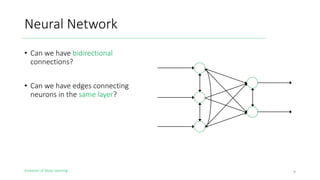
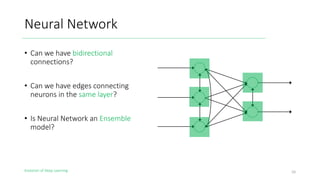


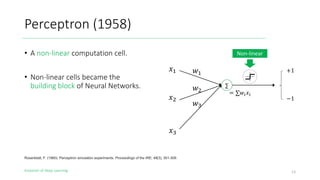
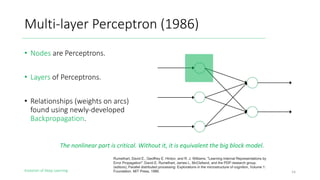
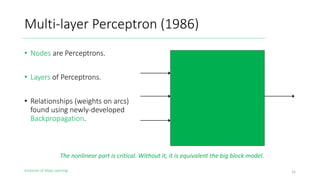
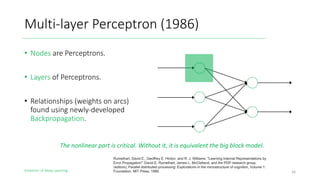
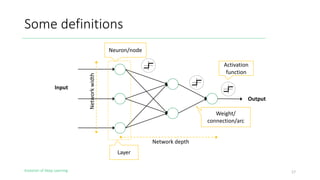


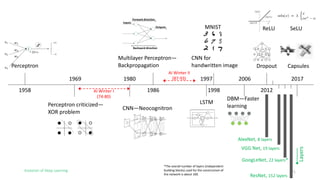

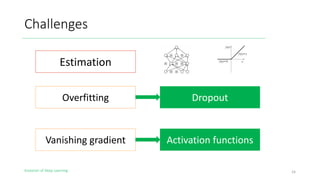

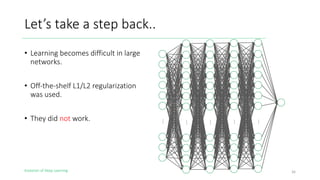
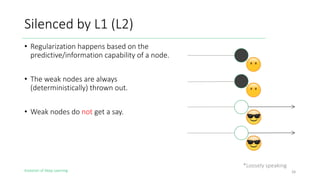
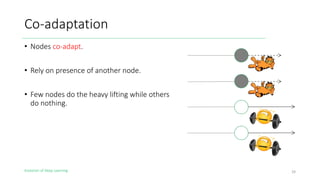

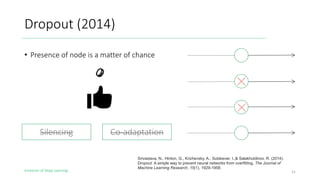





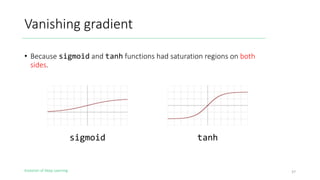
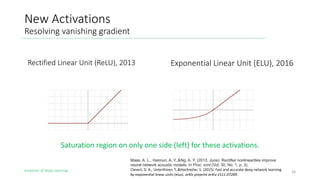




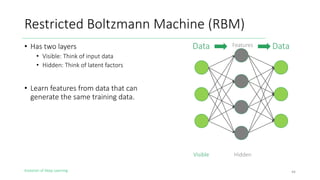
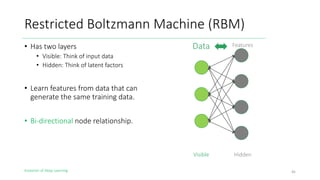
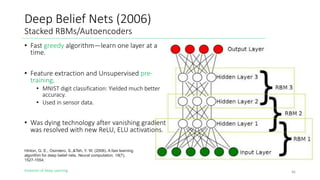
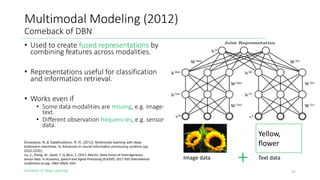

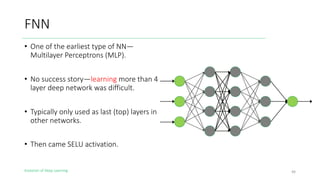


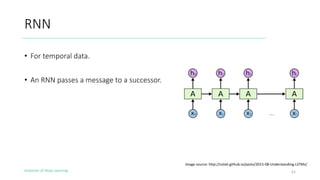
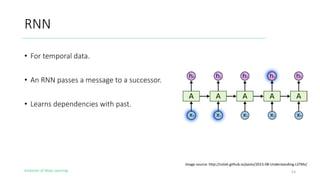
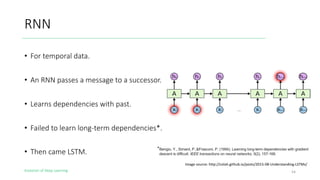
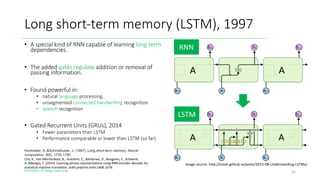


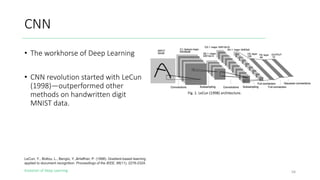
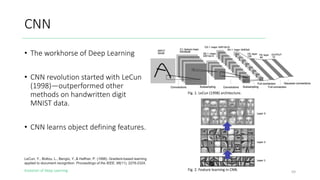

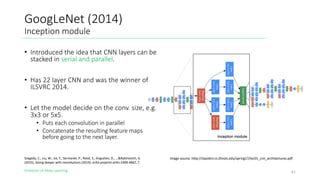

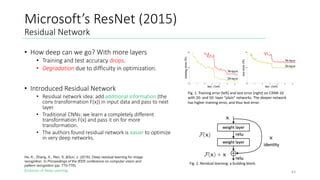




The document outlines the evolution of deep learning, discussing neural networks, their development, and various advancements such as multi-layer perceptrons and dropout techniques. It highlights key challenges in deep learning, like overfitting and the vanishing gradient problem, and presents solutions such as new activation functions and model types including convolutional and recurrent neural networks. Additionally, it situates important historical milestones in deep learning from the perceptron model to complex architectures like LSTM and attention-based models.



































































