クラスタリングと分類分析1
5.1 Feature Selectionand Data Mining
5.2 Supervised versus Unsupervised Learning
5.3 Unsupervised Learning: k-means
5.4 Unsupervised Hierarchical Clustering
5.5 Mixture Models and the EM algorithm
5.6 Supervised Learning and Linear
Discrimination
5.7 Support Vector Machines (SVM)
5.8 Classification Trees and Random Forest
5.9 Top 10 Algorithms in Data Mining 2008
4.
クラスタリングと分類分析1
% 5.1 FeatureSelection and Data Mining
CH05_SEC01_1_FischerExtraction.m
CH05_SEC01_1_FischerExtraction_production.m
% 5.2 Supervised versus Unsupervised Learning
CH05_SEC02_1_Fig5p7_Fig5p8.m
% 5.3 Unsupervised Learning: k-means
CH05_SEC03_1_Kmeans.m
CH05_SEC03_1_Kmeans_production.m
% 5.4 Unsupervised Hierarchical Clustering
CH05_SEC04_1_Dendrogram.m
CH05_SEC04_1_Dendrogram_production.m
% 5.5 Mixture Models and EM algorithm
CH05_SEC05_1_GaussianMixtureModels.m
% 5.6 Supervised Learning and LDA
CH05_SEC06_1_LDA_Classify.m
% 5.7 Support Vector Machine
CH05_SEC07_1_SVM.m
% 5.8 Classification Trees and Random Forest
CH05_SEC08_1_Trees.m
CH05_SEC08_1_Trees_production.m
特異値分解による特徴量抽出(復習)
1x 2x mx1u 1v
1σ= 2u 2v
2σ mu mv
mσ+ + +
2 21 1 1 2 m m mσ σ σ+= = + +X ΣU u v u v u vV
, , ,n m n m m m m m× × × ×
∈ ∈ ∈ ∈X ΣU V
k-平均クラスタリング:画像処理の例
clear all; clc;close all;
x = imread(‘../data/dog.jpg'); % load the image
[nx,ny,~] = size(x); % image size
figure(1); imshow(x);
X = squeeze(reshape(x,nx*ny,1,3)); % vectorize the image
X = double(X); % convert into double type
% k-means clustering
K = 10;
[idx, means] = kmeans(X, K);
% replace the color with the mean value of the cluster
X1 = zeros(size(X));
for k=1:K
X1(idx==k,:) = repmat(means(k,:),sum(idx==k),1);
end
X1 = reshape(X1,nx,ny,3); % matricize the vector
X1 = uint8(X1); % convert into integer type
figure(2); imshow(X1);
demo_Kmeans_Image.m (WebClassにあります)
33.
ここで演習
• k-平均法のコードCH05_SEC03_1_Kmeans_production.mを走らせてみましょう。コー
ドを書き換えて、共分散行列が等しい場合にk-平均法がどのように動くか、見てみ
ましょう。
% randomellipse 1 centered at (0,0)
x=randn(n1+n2,1); y=0.5*randn(n1+n2,1);
% random ellipse 2 centered at (1,-2) and rotated by theta
x2=randn(n1+n2,1)+1; y2=0.2*randn(n1+n2,1)-2; theta=pi/4;
A=[cos(theta) -sin(theta); sin(theta) cos(theta)];
x3=A(1,1)*x2+A(1,2)*y2; y3=A(2,1)*x2+A(2,2)*y2;
% random ellipse 1 centered at (0,0)
x=randn(n1+n2,1)-2.2; y=0.5*randn(n1+n2,1);
x3=randn(n1+n2,1)+2.2; y3=0.5*randn(n1+n2,1);
共分散行列が異なる場合(もともとのコード) 共分散行列が等しい場合
• 画像処理のコードdemo_Kmeans_Image.m(WebClassにあります)を実行してみま
しょう。
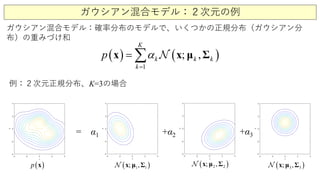
ガウシアン混合モデルからの標本生成
ガウシアン混合モデルからの標本生成
混合係数
正規分布のパラメタ
{ }kα
{ },kkμ Σ
N個の標本(サンプル点){ } 1
N
i i=
x
( ) ( )
1
; ,k
K
k
k kp α
=
= ∑ x μ Σx { } 1
N
i i=
x
alpha1 = 0.3;
alpha2 = 0.4;
alpha3 = 0.3;
mu1 = [-2 0];
mu2 = [ 1.5 -1];
mu3 = [ 0 +1];
Sigma1 = [1.2500 -0.4330; -0.4330 1.7500];
Sigma2 = [1.7500 0.4330; 0.4330 1.2500];
Sigma3 = [1 0; 0 1];
Sigma = zeros(2,2,3);
Sigma(:,:,1) = Sigma1;
Sigma(:,:,2) = Sigma2;
Sigma(:,:,3) = Sigma3;
mu = [mu1; mu2; mu3];
alpha = [alpha1 alpha2 alpha3];
gm = gmdistribution(mu, Sigma, alpha);
x = gm.random(3000);
44.
Expectation-Maximizationアルゴリズム:混合モデルのパラメタ推定
( ) ()1
ˆˆ ˆ;ˆ ,k k k
K
k
p α
=
= ∑ x μ Σx { } 1
N
i i=
x
Expectation-Maximization (EM) アルゴリズム
データから混合モデルのパラメタを推定
N個の標本(サンプル点){ } 1
N
i i=
x
混合係数
正規分布のパラメタ
{ }ˆkα
{ }ˆˆ ,k kμ Σ
options = statset('MaxIter',1000);
fm = fitgmdist(x,3, 'options', options);
45.
Expectation-Maximizationアルゴリズム:混合モデルのパラメタ推定
Expectation-Maximization (EM) アルゴリズム
E-ステップ
現在(m回目)のパラメタを用いて、サンプル点 xj がクラスkに
属する事後確率を計算
M-ステップ
上記の事後確率を用いて、パラメタを更新
( ) ( )
{ } ( )
{ } ( )
{ }( ), ,
m m m m
k k kα=Θ μ Σ
( )
( )
( ) ( ) ( )
( )
( )
( )
; ,
;
m m m
k k km
k m
j
j
j
α
τ =
x μ Σ
x Θ
x
( ) ( )
( )
( )
( )
( )
( )
( )
( )
( )
( ) ( )
( ) ( )
( )
( )
( )
1
1
1 1
1
1 1
11
1
1
j
j
n
m m
k k
j
n m
km j
k n m
kj
n m m m
j
k k kjm
k n
j
j
j j j
m
kj
n
α τ
τ
τ
τ
τ
+
=
+ =
=
+ +
=+
=
=
=
− −
=
∑
∑
∑
∑
∑
x
x
x
x
x
x
μ
x μ x μ
Σ
( ) ( )
{ } ( )
{ } ( )
{ }( ) ( ) ( )
{ } ( )
{ } ( )
{ }( )1 1 1 1
, , , ,m m m m m m m m
k k k k k kα α+ + + +
= =→Θ μ Σ Θ μ Σ
46.
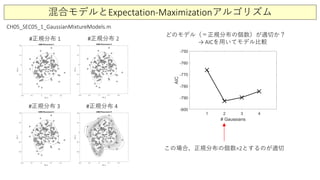
混合モデルとExpectation-Maximizationアルゴリズム
CH05_SEC05_1_GaussianMixtureModels.m
イヌ
ネコ
load catData_w.mat; %ネコ画像データ(ウェーブレット変換)
load dogData_w.mat; % イヌ画像データ(ウェーブレット変換)
CD = [dog_wave cat_wave];
[u,s,v] = svd(CD-mean(CD(:))); % 特異値分解
dogcat = v(:,2:2:4); % 特徴量として主成分2と4を採用
GMModel = fitgmdist(dogcat,2); % ① 混合ガウスモデルでフィット
AIC = GMModel.AIC; % モデルのAICを計算
estimatedLabels = cluster(GMModel, dogcat); % ② クラスを推定
① 混合ガウスモデルでフィット ② クラスを推定








![主成分分析による特徴抽出:原画像
CH05_SEC01_1_FischerExtraction.m
イヌ画像80枚 ネコ画像80枚
%%
load dogData.mat; % イヌ画像80枚
load catData.mat; % ネコ画像80枚
CD=double([dog cat]); % 4096*160行列
% 特異値分解で特徴抽出
[u,s,v]=svd(CD-mean(CD(:)),'econ');
問題点
各画像データは64×64=4096次元
→ 低次元の特徴量を見つける必要](https://image.slidesharecdn.com/8clusteringandclassification1-200811225913/85/8-1-9-320.jpg)



![特異値分解による特徴量抽出(復習)
1x 2x mx = n m×U m m×Σ ( )m m×
V
n r×U
r r×Σ ( )r m×
V
≈
>> [U, S, V] = svd(X, 'econ');
>> Utilde = U(:,1:r);
Vtilde = V(:,1:r);
Stilde = S(1:r,1:r);](https://image.slidesharecdn.com/8clusteringandclassification1-200811225913/85/8-1-13-320.jpg)
![主成分分析による特徴抽出:原画像
CH05_SEC01_1_FischerExtraction.m
イヌ画像80枚 ネコ画像80枚
%%
load dogData.mat; % イヌ画像80枚
load catData.mat; % ネコ画像80枚
CD=double([dog cat]); % 4096*160行列
% 特異値分解で特徴抽出
[u,s,v]=svd(CD-mean(CD(:)),'econ');
問題点
各画像データは64×64=4096次元
→ 低次元の特徴量を見つける必要](https://image.slidesharecdn.com/8clusteringandclassification1-200811225913/85/8-1-14-320.jpg)

![主成分分析による特徴抽出:ウェーブレット変換画像
load dogData_wave.mat
load catData_wave.mat
CD2=double([dog_wave cat_wave]);
CH05_SEC01_1_FischerExtraction.m
イヌ画像80枚 ネコ画像80枚](https://image.slidesharecdn.com/8clusteringandclassification1-200811225913/85/8-1-16-320.jpg)

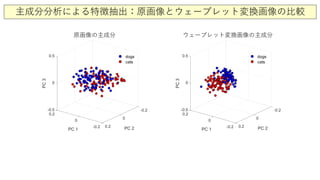
![ここで演習
• 特徴量抽出のコードCH05_SEC01_1_FischerExtraction_production.mを走らせてみま
しょう。
- アヤメのデータに関して、1, 2, 4方向以外での3次元プロットを描いてみましょう。
plot3(x1(:,1),x1(:,2),x1(:,4),'ro','Linewidth',[1],'MarkerEdgeColor','k','MarkerFaceColor',[0 1 0.2],'MarkerSize',8), hold on
plot3(x2(:,1),x2(:,2),x2(:,4),'bo','Linewidth',[1],'MarkerEdgeColor','k','MarkerFaceColor',[0.9 0 1],'MarkerSize',8)
plot3(x3(:,1),x3(:,2),x3(:,4),'bo','Linewidth',[1],'MarkerEdgeColor','k','MarkerFaceColor',[1 0.64 0.098],'MarkerSize',8)
- ネコのデータに関して、1, 2, 3方向以外での3次元プロットを描いてみましょう。
plot3(v(1:80,1),v(1:80,2),v(1:80,3),'ro','Linewidth',[1],
'MarkerEdgeColor','k',...
'MarkerFaceColor',[0 0 1],...
'MarkerSize',8), hold on % [0.49 1 .63]
plot3(v(81:end,1),v(81:end,2),v(81:end,3),'bo','Linewidth
',[1],'MarkerEdgeColor','k',...
'MarkerFaceColor',[1 0 0],...
'MarkerSize',8)](https://image.slidesharecdn.com/8clusteringandclassification1-200811225913/85/8-1-19-320.jpg)










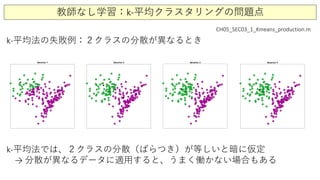
![教師なし学習:k-平均クラスタリング(k-means clustering)
k-平均法:MATLABコード CH05_SEC03_1_Kmeans_production.m
% kmeans code
>> [ind,c]=kmeans(Y,2); % データ行列Yをk=2クラスにクラスタリング
>> Y(1:10,:)
ans =
2.3370 -0.6895
2.9929 0.0962
2.9980 -0.0764
2.0982 -0.6789
1.7131 -1.0508
1.0304 -1.3045
2.0875 -0.2267
3.6068 1.0786
2.7084 0.1866
2.4458 -0.7135
>> c
c =
2.1698 -0.5501
-0.1829 -0.0536
>> ind(1:10)
ans =
1
1
1
1
1
1
1
1
1
1
データ1
データ2
データ3
150のデータ点
クラス1の重心位置
クラス2の重心位置
150のデータ点に対応するクラスラベル](https://image.slidesharecdn.com/8clusteringandclassification1-200811225913/85/8-1-31-320.jpg)
![k-平均クラスタリング:画像処理の例
clear all; clc; close all;
x = imread(‘../data/dog.jpg'); % load the image
[nx,ny,~] = size(x); % image size
figure(1); imshow(x);
X = squeeze(reshape(x,nx*ny,1,3)); % vectorize the image
X = double(X); % convert into double type
% k-means clustering
K = 10;
[idx, means] = kmeans(X, K);
% replace the color with the mean value of the cluster
X1 = zeros(size(X));
for k=1:K
X1(idx==k,:) = repmat(means(k,:),sum(idx==k),1);
end
X1 = reshape(X1,nx,ny,3); % matricize the vector
X1 = uint8(X1); % convert into integer type
figure(2); imshow(X1);
demo_Kmeans_Image.m (WebClassにあります)](https://image.slidesharecdn.com/8clusteringandclassification1-200811225913/85/8-1-32-320.jpg)
![ここで演習
• k-平均法のコードCH05_SEC03_1_Kmeans_production.mを走らせてみましょう。コー
ドを書き換えて、共分散行列が等しい場合にk-平均法がどのように動くか、見てみ
ましょう。
% random ellipse 1 centered at (0,0)
x=randn(n1+n2,1); y=0.5*randn(n1+n2,1);
% random ellipse 2 centered at (1,-2) and rotated by theta
x2=randn(n1+n2,1)+1; y2=0.2*randn(n1+n2,1)-2; theta=pi/4;
A=[cos(theta) -sin(theta); sin(theta) cos(theta)];
x3=A(1,1)*x2+A(1,2)*y2; y3=A(2,1)*x2+A(2,2)*y2;
% random ellipse 1 centered at (0,0)
x=randn(n1+n2,1)-2.2; y=0.5*randn(n1+n2,1);
x3=randn(n1+n2,1)+2.2; y3=0.5*randn(n1+n2,1);
共分散行列が異なる場合(もともとのコード) 共分散行列が等しい場合
• 画像処理のコードdemo_Kmeans_Image.m(WebClassにあります)を実行してみま
しょう。](https://image.slidesharecdn.com/8clusteringandclassification1-200811225913/85/8-1-33-320.jpg)
![教師なし階層クラスタリング
Y3=[X1(1:50,:); X2(1:50,:)];
Y2 = pdist(Y3,'euclidean'); % pairwise distance
Z = linkage(Y2,'average'); % hierarchical clustering
figure(1);
thresh = 0.85*max(Z(:,3));
[H, T, O] = dendrogram(Z, 100,
'ColorThreshold',thresh);
axis off square;
figure(2);
thresh = 0.25*max(Z(:,3));
[H, T, O] = dendrogram(Z,100,'ColorThreshold',thresh);
axis off square;
CH05_SEC04_1_Dendrogram_production.m
>> Y2(1:10)
ans =
Columns 1 through 7
0.9408 0.3609 0.7604 0.3216 1.5054
1.3019 0.6734
Columns 8 through 10
0.7518 1.3065 0.3372
>> Z(1:10,:)
ans =
26.0000 27.0000 0.0248
3.0000 42.0000 0.0266
19.0000 43.0000 0.0375
7.0000 10.0000 0.0421
62.0000 94.0000 0.0425
1.0000 46.0000 0.0475
38.0000 48.0000 0.0476
11.0000 36.0000 0.0665
16.0000 31.0000 0.0681
8.0000 22.0000 0.0708
すべてのデータ対間の距離
階層クラスタリングの情報](https://image.slidesharecdn.com/8clusteringandclassification1-200811225913/85/8-1-35-320.jpg)
![教師なし階層クラスタリング:デンドログラム
Y3=[X1(1:50,:); X2(1:50,:)];
Y2 = pdist(Y3,'euclidean'); % pairwise distance
Z = linkage(Y2,'average'); % hierarchical clustering
figure(1);
thresh = 0.85*max(Z(:,3));
[H, T, O] = dendrogram(Z, 100,
'ColorThreshold',thresh);
axis off square;
figure(2);
thresh = 0.25*max(Z(:,3));
[H, T, O] = dendrogram(Z,100,'ColorThreshold',thresh);
axis off square;
CH05_SEC04_1_Dendrogram_production.m
閾値=0.85
閾値=0.25](https://image.slidesharecdn.com/8clusteringandclassification1-200811225913/85/8-1-36-320.jpg)
![教師なし階層クラスタリング
Y3=[X1(1:50,:); X2(1:50,:)];
Y2 = pdist(Y3,'euclidean'); % pairwise distance
Z = linkage(Y2,'average'); % hierarchical clustering
figure(4); clf; hold on;
t = cluster(Z,2);
plot(Y3(t==1,1),Y3(t==1,2),'ro','Linewidth',[1],'MarkerEdgeColor','k',...
'MarkerFaceColor',[0 1 0.2],...
'MarkerSize',8), hold on % [0.49 1 .63]
plot(Y3(t==2,1),Y3(t==2,2),'bo','Linewidth',[1],'MarkerEdgeColor','k',...
'MarkerFaceColor',[0.9 0 1],...
'MarkerSize',8)
CH05_SEC04_1_Dendrogram_production.mの追記](https://image.slidesharecdn.com/8clusteringandclassification1-200811225913/85/8-1-37-320.jpg)
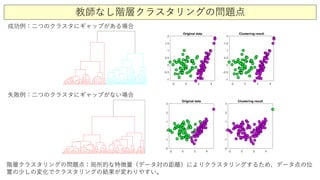
![ここで演習
• 階層的クラスタリングのコードCH05_SEC04_1_Dendrogram_production.mを走らせて
みましょう。
以下のコードを追記して、階層クラスタリングを図示してみましょう。
figure(4); clf; hold on;
t = cluster(Z,2);
plot(Y3(t==1,1),Y3(t==1,2),'ro','Linewidth',[1],'MarkerEdgeColor','k',...
'MarkerFaceColor',[0 1 0.2],...
'MarkerSize',8), hold on % [0.49 1 .63]
plot(Y3(t==2,1),Y3(t==2,2),'bo','Linewidth',[1],'MarkerEdgeColor','k',...
'MarkerFaceColor',[0.9 0 1],...
'MarkerSize',8)](https://image.slidesharecdn.com/8clusteringandclassification1-200811225913/85/8-1-39-320.jpg)


![ガウシアン混合モデルからの標本生成
ガウシアン混合モデルからの標本生成
混合係数
正規分布のパラメタ
{ }kα
{ },k kμ Σ
N個の標本(サンプル点){ } 1
N
i i=
x
( ) ( )
1
; ,k
K
k
k kp α
=
= ∑ x μ Σx { } 1
N
i i=
x
alpha1 = 0.3;
alpha2 = 0.4;
alpha3 = 0.3;
mu1 = [-2 0];
mu2 = [ 1.5 -1];
mu3 = [ 0 +1];
Sigma1 = [1.2500 -0.4330; -0.4330 1.7500];
Sigma2 = [1.7500 0.4330; 0.4330 1.2500];
Sigma3 = [1 0; 0 1];
Sigma = zeros(2,2,3);
Sigma(:,:,1) = Sigma1;
Sigma(:,:,2) = Sigma2;
Sigma(:,:,3) = Sigma3;
mu = [mu1; mu2; mu3];
alpha = [alpha1 alpha2 alpha3];
gm = gmdistribution(mu, Sigma, alpha);
x = gm.random(3000);](https://image.slidesharecdn.com/8clusteringandclassification1-200811225913/85/8-1-43-320.jpg)


![混合モデルとExpectation-Maximizationアルゴリズム
CH05_SEC05_1_GaussianMixtureModels.m
イヌ
ネコ
load catData_w.mat; % ネコ画像データ(ウェーブレット変換)
load dogData_w.mat; % イヌ画像データ(ウェーブレット変換)
CD = [dog_wave cat_wave];
[u,s,v] = svd(CD-mean(CD(:))); % 特異値分解
dogcat = v(:,2:2:4); % 特徴量として主成分2と4を採用
GMModel = fitgmdist(dogcat,2); % ① 混合ガウスモデルでフィット
AIC = GMModel.AIC; % モデルのAICを計算
estimatedLabels = cluster(GMModel, dogcat); % ② クラスを推定
① 混合ガウスモデルでフィット ② クラスを推定](https://image.slidesharecdn.com/8clusteringandclassification1-200811225913/85/8-1-46-320.jpg)












![古典プログラマ向け量子プログラミング入門 [フル版]](https://cdn.slidesharecdn.com/ss_thumbnails/sal-qc-prog-full-191128113651-thumbnail.jpg?width=640&height=640&fit=bounds)





















































