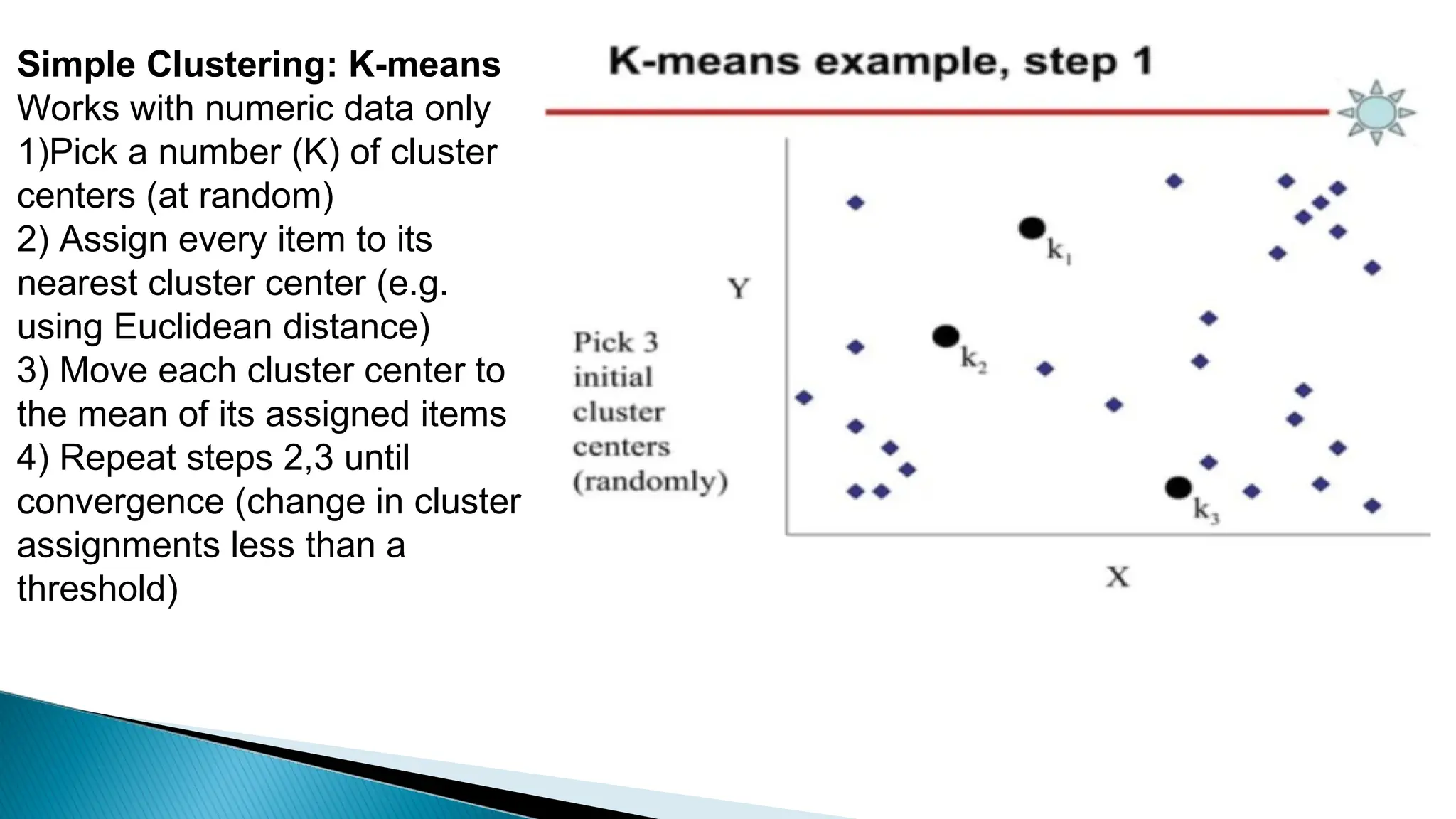
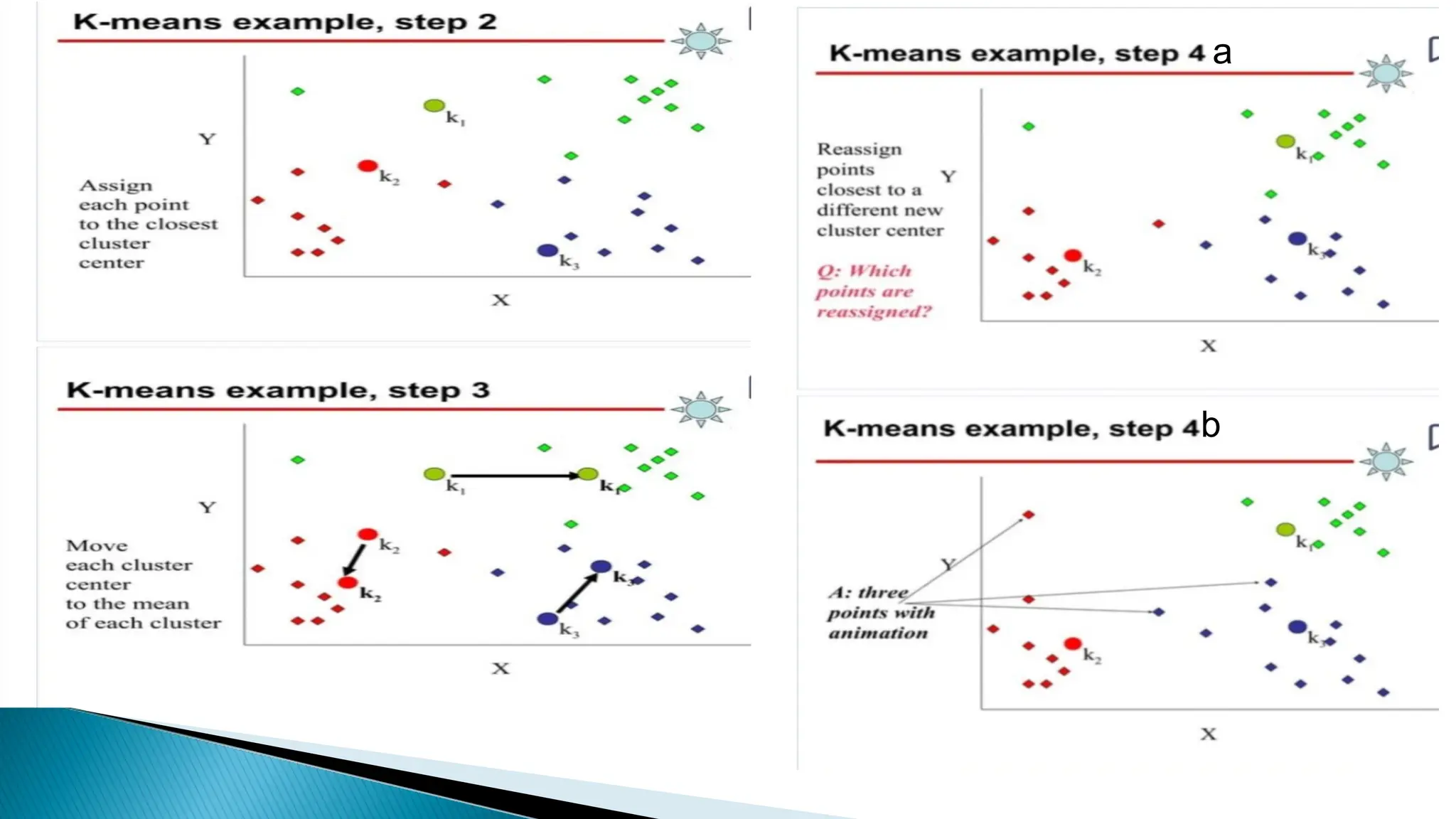
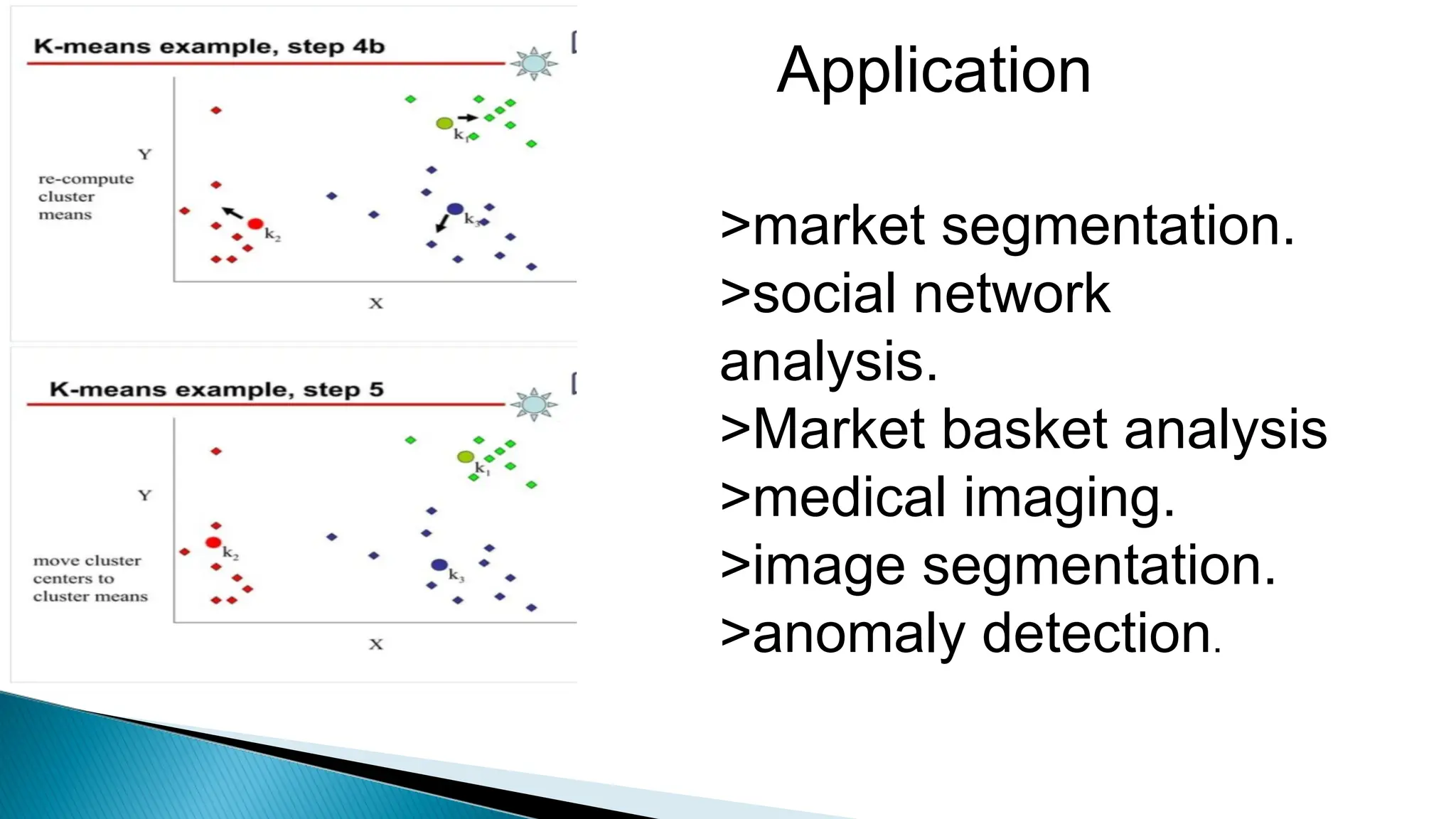
Clustering algorithms group data points into clusters based on similarities, aiming for high intra-cluster and low inter-cluster similarity. Key steps include distance measurement, cluster assignment, and evaluation, with methods like k-means facilitating this process. While clustering is valuable for applications such as market segmentation and anomaly detection, challenges like sensitivity to outliers and the need for specifying the number of clusters can affect results.














![Chapter#04[Part#01]K-Means Clusterig.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/chapter04part01k-meansclusterig-250525201708-2d369307-thumbnail.jpg?width=640&height=640&fit=bounds)


![[ML]-Unsupervised-learning_Unit2.ppt.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/ml-unsupervised-learningunit2-230916145038-acbd0397-thumbnail.jpg?width=640&height=640&fit=bounds)


































