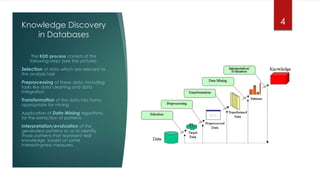
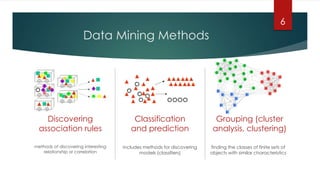
This document summarizes an exploratory data mining project analyzing a bank marketing dataset using the WEKA software. The goals were to study data mining techniques, analyze a dataset for classification, clustering, and prediction. The project involved preprocessing the bank marketing data, which recorded responses to phone calls for bank term deposits. Data mining methods like decision trees, naive Bayes, and k-means clustering were applied for classification and clustering. Association rule mining using the Apriori algorithm discovered rules for subscribing to term deposits. The results provide profiles for customers likely to subscribe or not subscribe to deposits based on attributes like age, job, education level, loan status and contact method.