This document discusses various techniques for analyzing and visualizing data to gain insights. It covers data attribute types, basic statistical descriptions to understand data distribution and outliers, different visualization methods to discover patterns and relationships, and various ways to measure similarity between data objects, including distances, coefficients, and cosine similarity for text. The goal is to preprocess and understand data at a high level before applying more advanced analytics.




![5
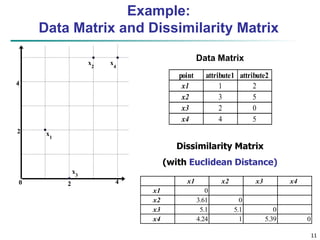
Similarity and Dissimilarity
Similarity
Numerical measure of how alike two data objects are
Value is higher when objects are more alike
Often falls in the range [0,1]
Dissimilarity (e.g., distance)
Numerical measure of how different two data objects
are
Lower when objects are more alike
Minimum dissimilarity is often 0
Upper limit varies
Proximity refers to a similarity or dissimilarity](https://image.slidesharecdn.com/422865is465201912102data-2-230301142633-0d12407d/85/4_22865_IS465_2019_1__2_1_02Data-2-ppt-5-320.jpg)







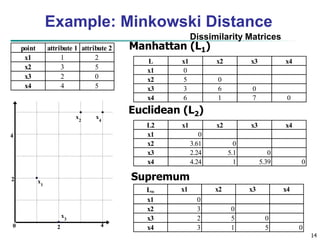
![15
Ordinal Variables
An ordinal variable can be discrete or continuous
Order is important, e.g., rank
Can be treated like interval-scaled
replace xif by their rank
map the range of each variable onto [0, 1] by replacing
i-th object in the f-th variable by
compute the dissimilarity using methods for interval-
scaled variables
1
1
f
if
if M
r
z
}
,...,
1
{ f
if
M
r ](https://image.slidesharecdn.com/422865is465201912102data-2-230301142633-0d12407d/85/4_22865_IS465_2019_1__2_1_02Data-2-ppt-15-320.jpg)





































![[DSC Europe 25] Mikhail Rozhkov - AI Product Canvas: From Business Goals to T...](https://cdn.slidesharecdn.com/ss_thumbnails/d53doddtpgfqivmzqel6-mikhail-rozhkov-ai-product-canvas-v1-260121115910-9dd517a7-thumbnail.jpg?width=640&height=640&fit=bounds)





![[DSC Europe 25] Paula Garcia Esteban -Building the Future: The Role of Data S...](https://cdn.slidesharecdn.com/ss_thumbnails/9ld1r1bsqpwve8qfvphy-paula-garcia-esteban-building-the-future-260122103838-4171f5cb-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Milovan Jovicic - Beyond AI's Reach: The Enduring Value of Ev...](https://cdn.slidesharecdn.com/ss_thumbnails/pyeij0hurgwq5jugmtnv-2-milovan-jovicic-beyond-ais-reach-the-enduring-value-of-evergreen-design-v2-260120105856-d6ee57e5-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Bojan Banjac - AI is always right when it comes to the matter...](https://cdn.slidesharecdn.com/ss_thumbnails/syoxtqierpydwxm5srcb-4-bojan-banjac-ai-is-always-right-when-it-comes-to-the-matters-of-taste-260119101519-694ee7d7-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Tali Fulman - Guild Meetings, Then What? Building Data Commun...](https://cdn.slidesharecdn.com/ss_thumbnails/fgohhi33rwmhqdowdj5k-tali-fulman-guild-meetings-then-what-building-data-communities-that-actually-ch-260120105855-528492c3-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Josip Saban - Career building for data professionals.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/zroflcttkm1vmli0txea-josip-saban-career-building-for-data-professionals-260123083019-587cdb8c-thumbnail.jpg?width=640&height=640&fit=bounds)


