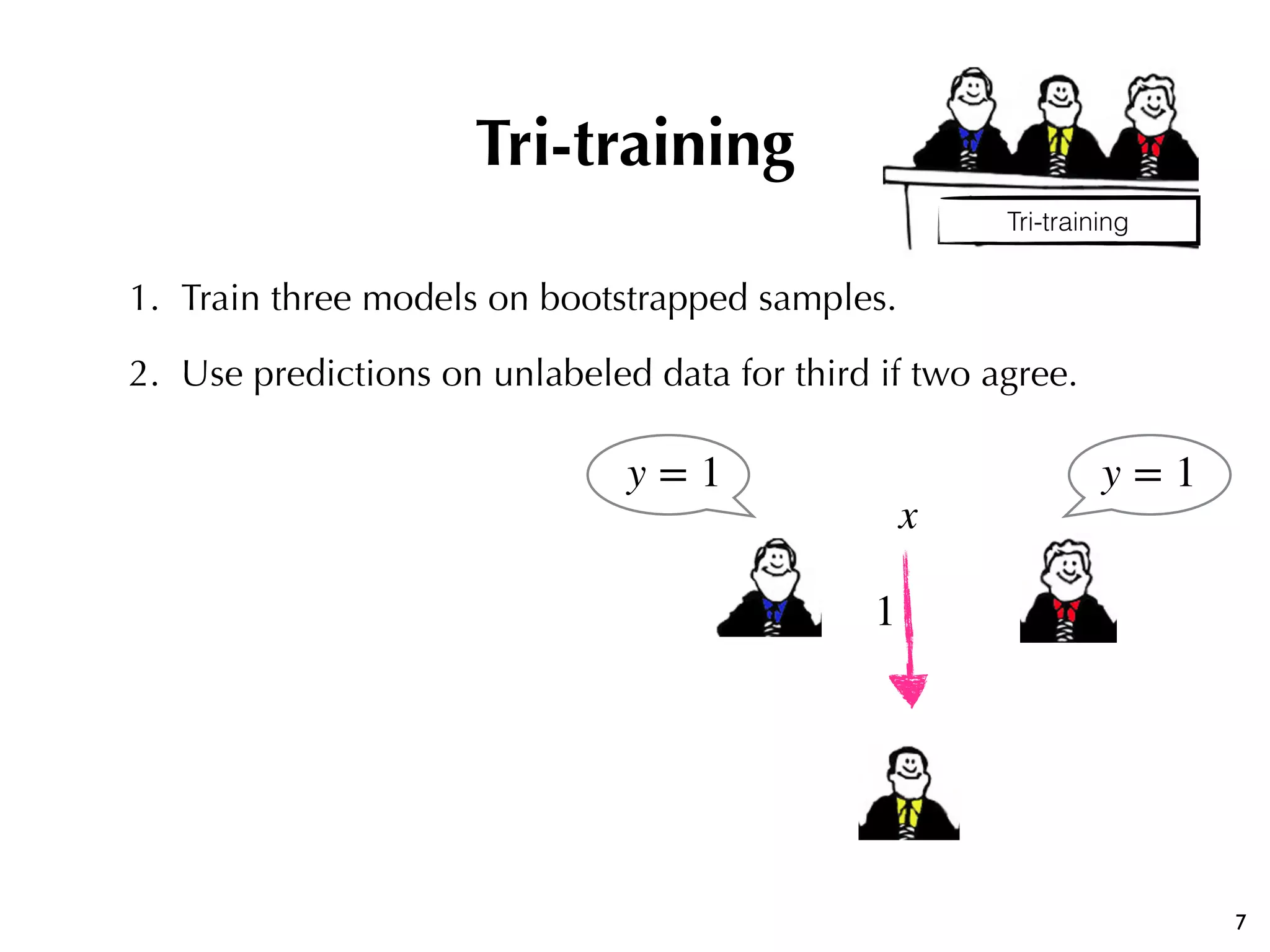
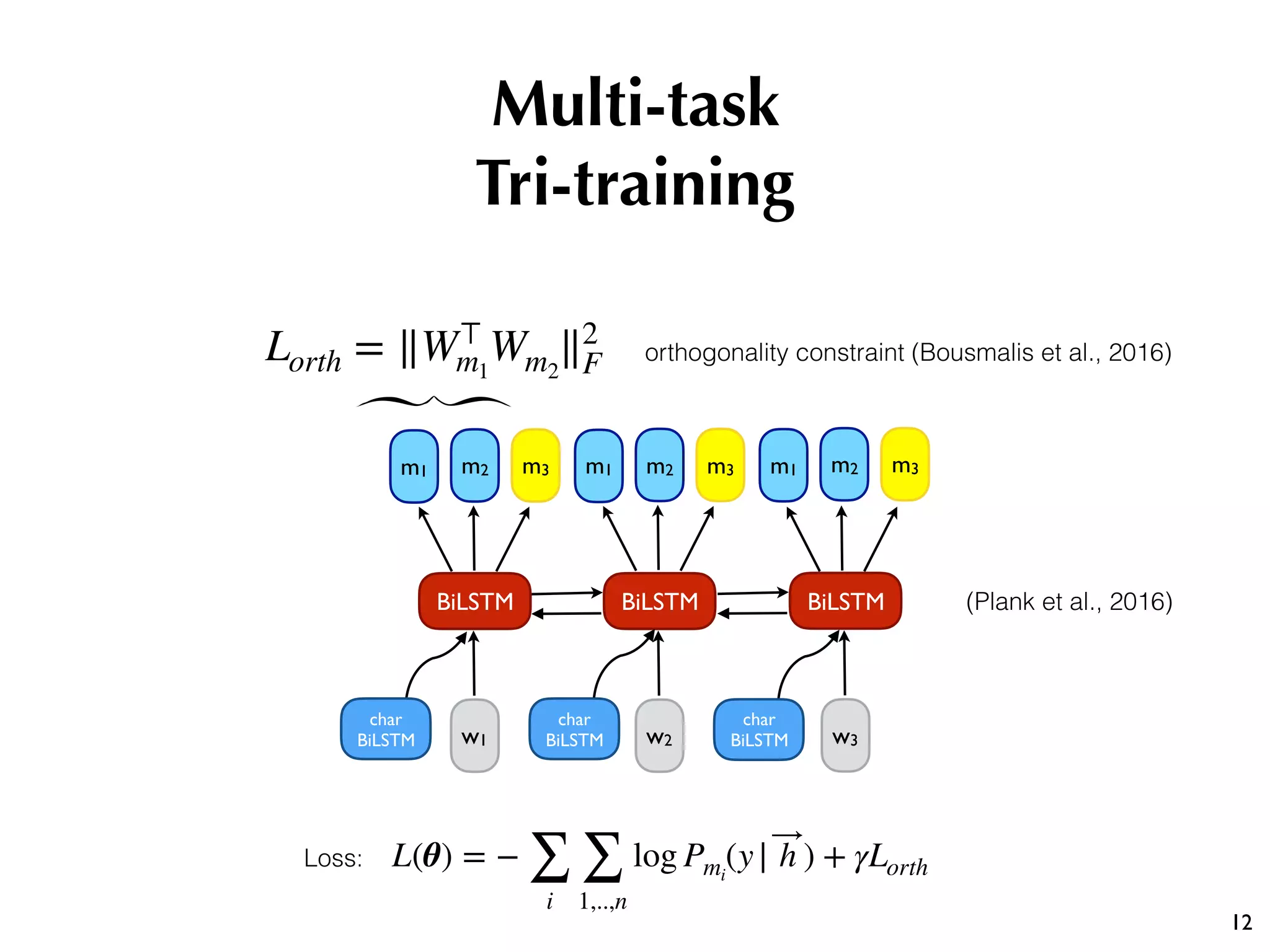
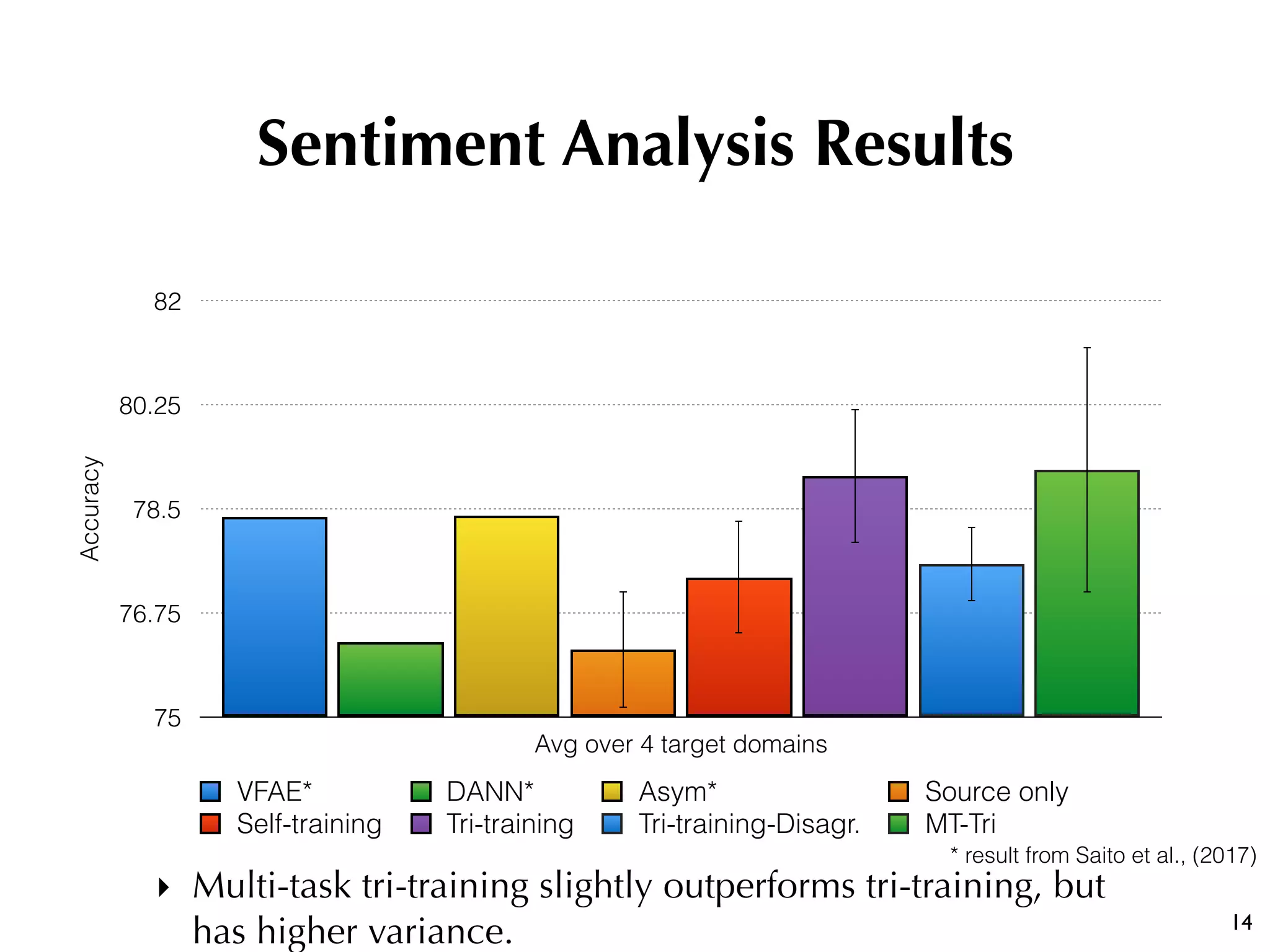
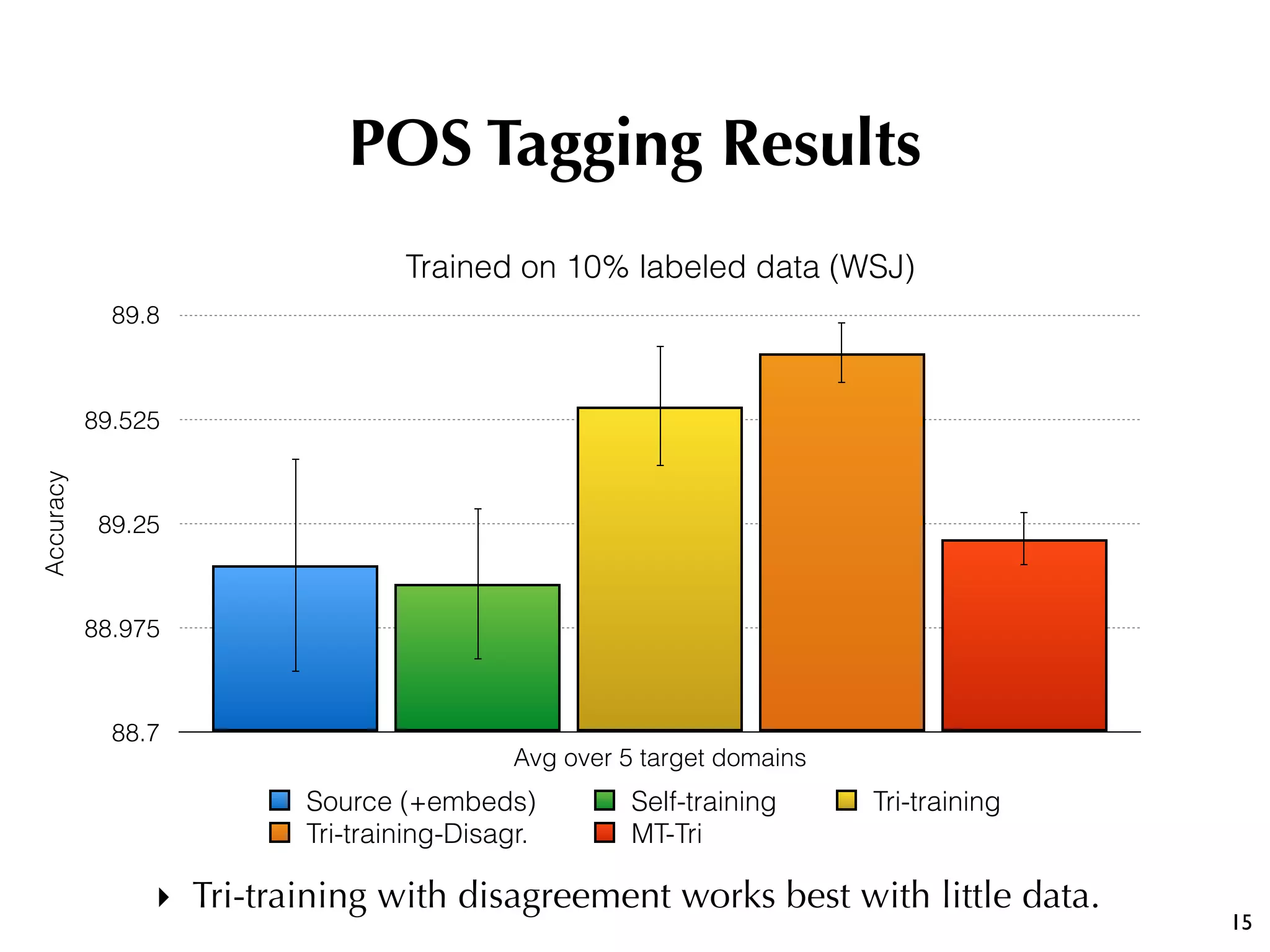
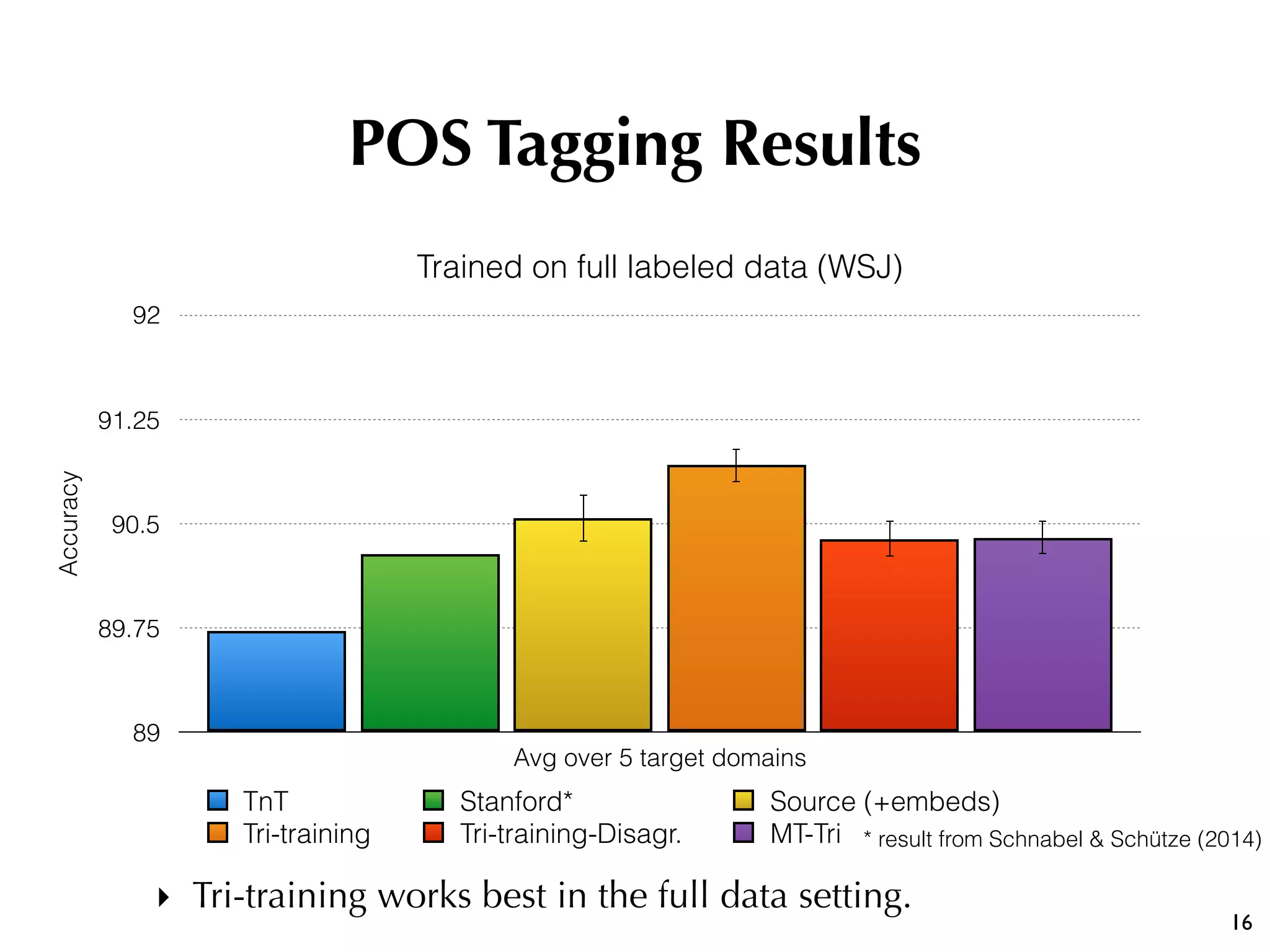
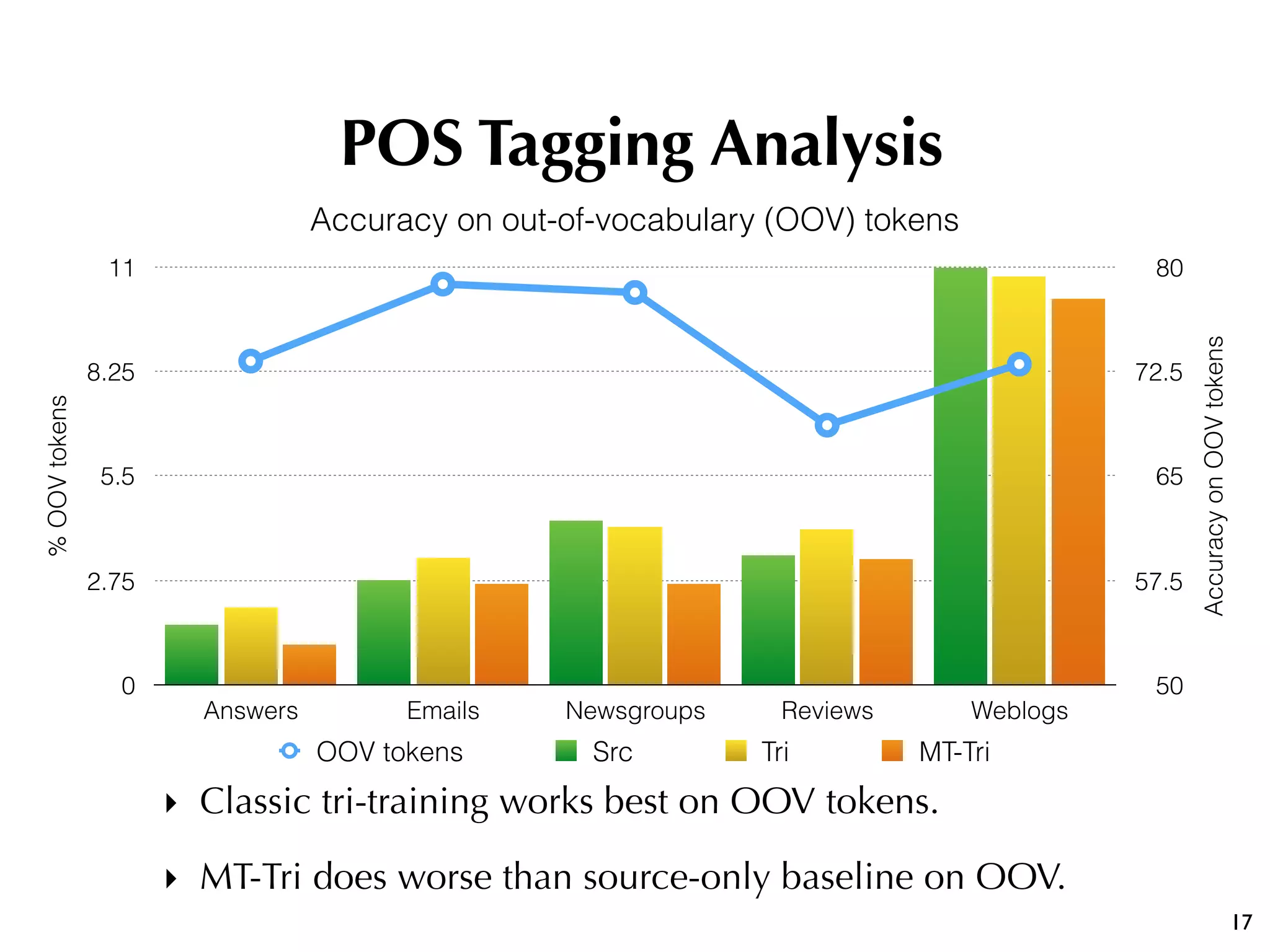
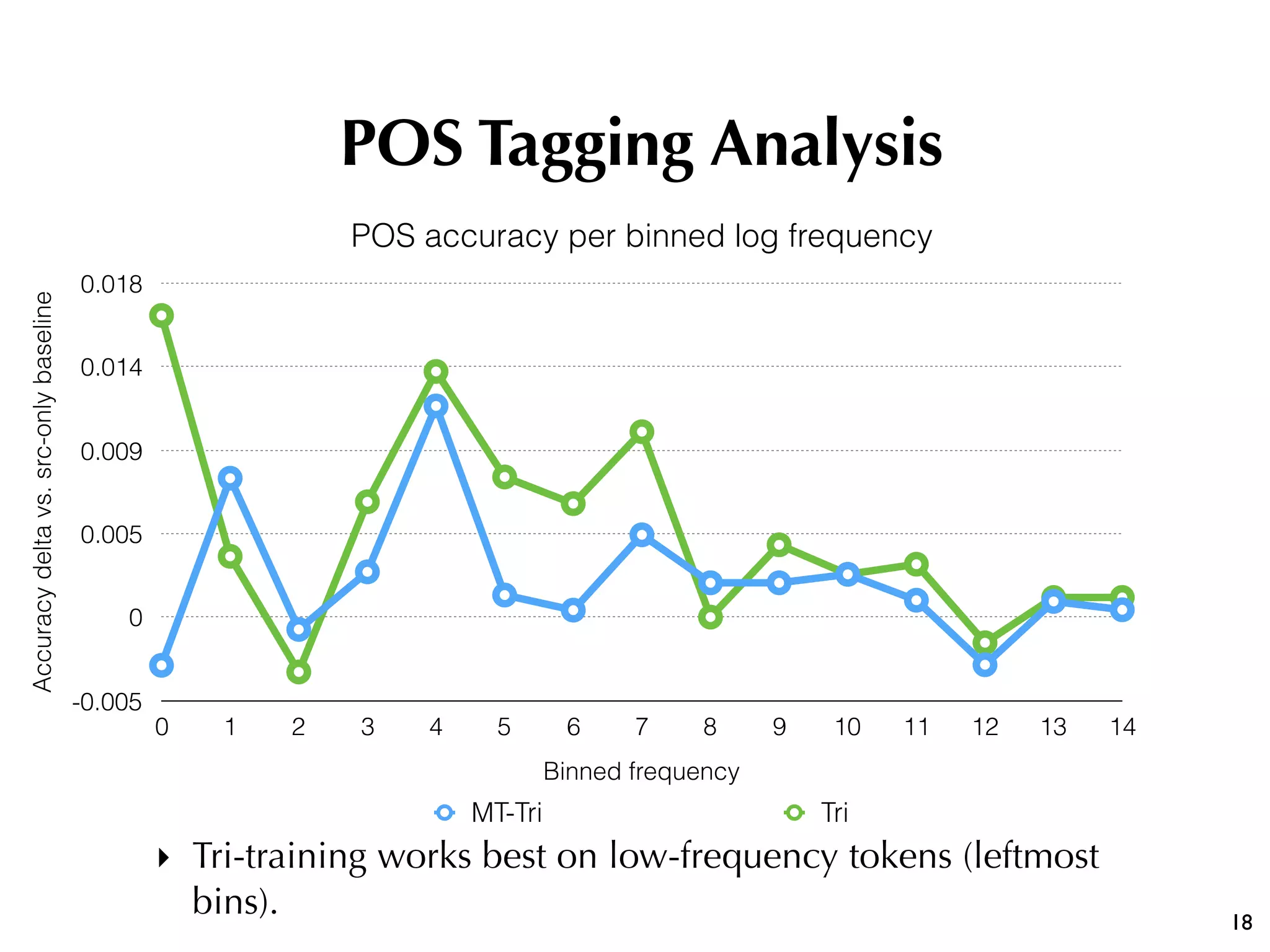
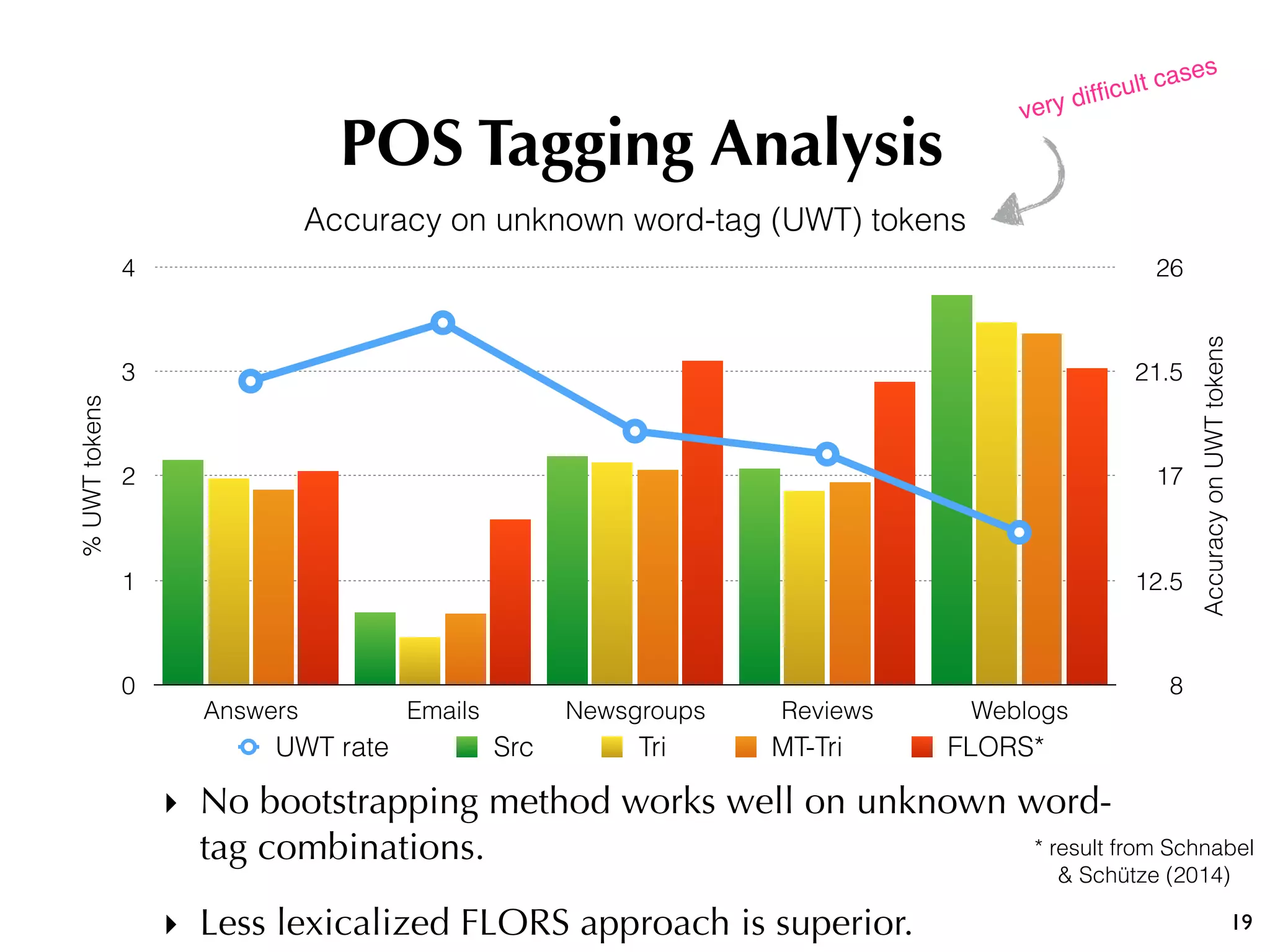
The document discusses the effectiveness of various semi-supervised learning (SSL) approaches under domain shift, particularly focusing on tri-training methods. It compares traditional SSL techniques with recent neural adaptations, highlighting performance on tasks like sentiment analysis and part-of-speech tagging. Findings suggest that classic tri-training outperforms recent methods, despite the proposed multi-task tri-training model showing competitive results, particularly for sentiment analysis.