
















![Google MapReduce – Idea
The core idea behind MapReduce is mapping your
data set into a collection of <key, value> pairs, and
then reducing over all pairs with the same key.
Map
Apply function to all elements of a list
square x = x * x;
Map square [1, 2, 3, 4, 5];
[1, 4, 9, 16, 25]
Reduce
Combine all elements of a list
Reduce (+)[1, 2, 3, 4, 5];
15](https://image.slidesharecdn.com/cloudcomputing-130617033940-phpapp01/75/Cloud-computing-22-2048.jpg)
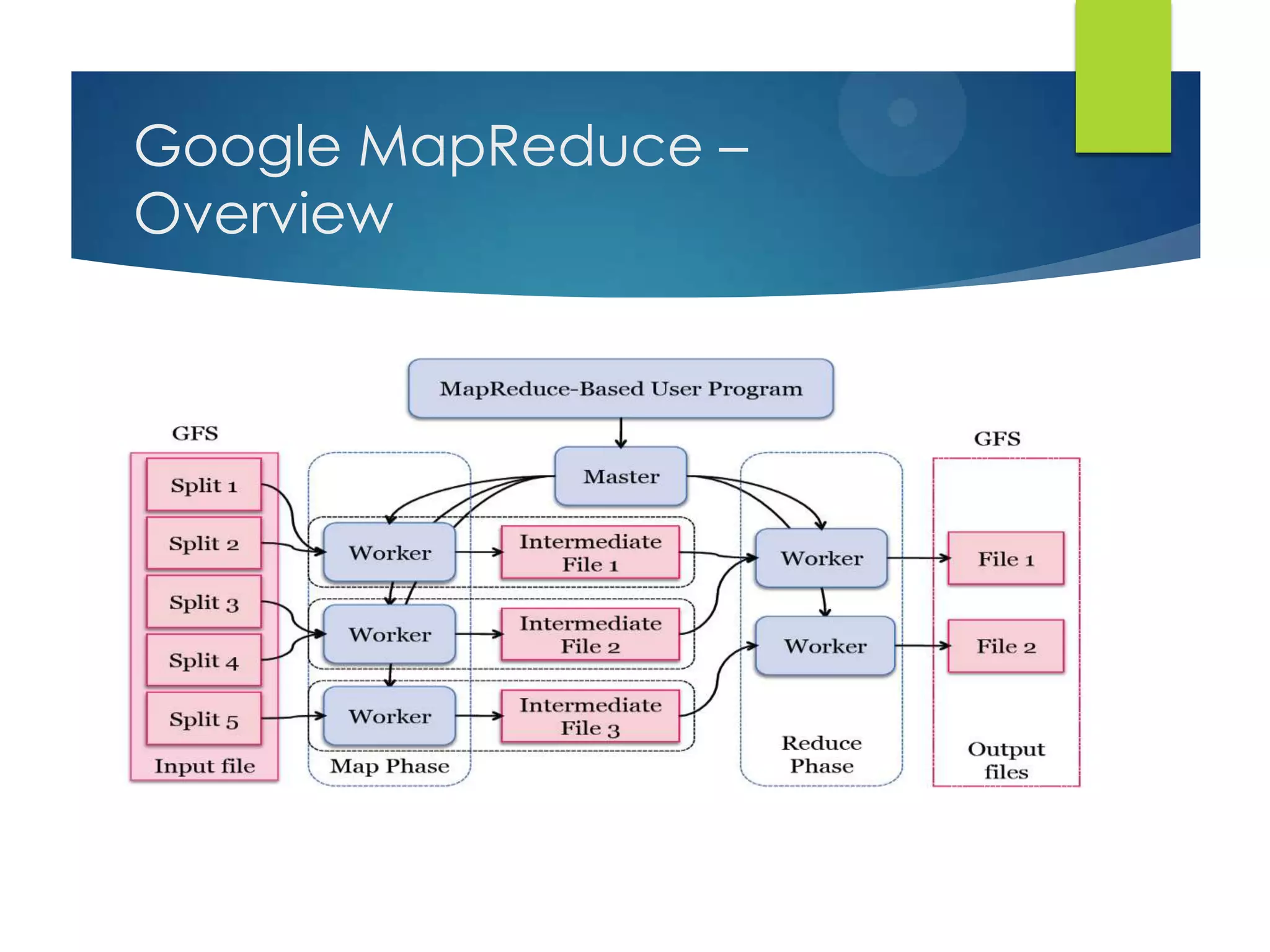




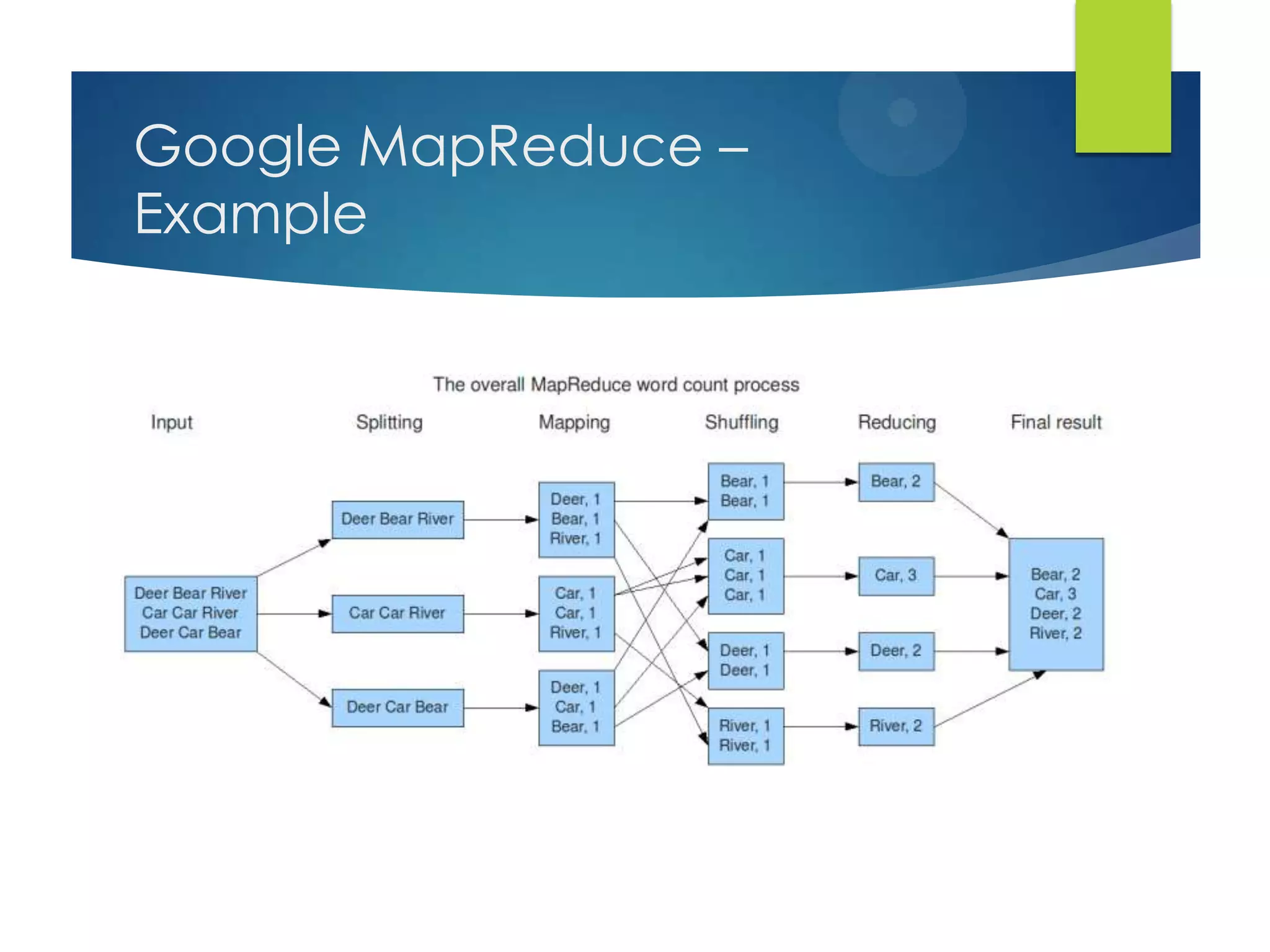











This document provides an overview of cloud computing and distributed systems. It discusses large scale distributed systems, cloud computing paradigms and models, MapReduce and Hadoop. MapReduce is introduced as a programming model for distributed computing problems that handles parallelization, load balancing and fault tolerance. Hadoop is presented as an open source implementation of MapReduce and its core components are HDFS for storage and the MapReduce framework. Example use cases and running a word count job on Hadoop are also outlined.



























































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)












![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)