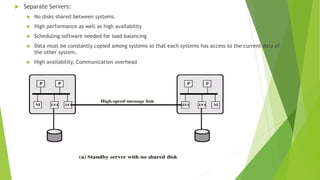
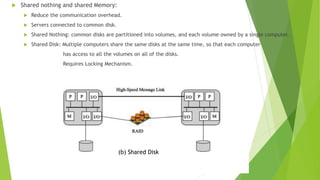
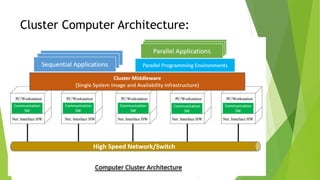
The document discusses cluster computing, highlighting its cost-effectiveness compared to supercomputers and symmetric multiprocessing (SMP). It covers design requirements, cluster configurations, implementation using blade servers, and the architecture involved in creating a cohesive computing resource from interconnected nodes. Furthermore, it compares the scalability and availability of clusters to SMP, emphasizing the advantages of clusters in high-performance server applications.