Downloaded 53 times









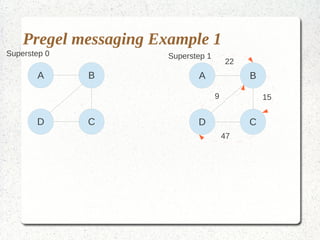
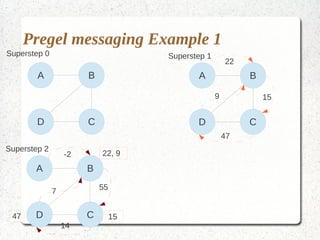
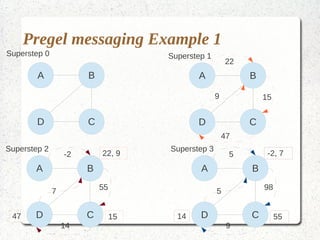

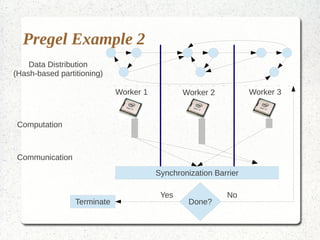

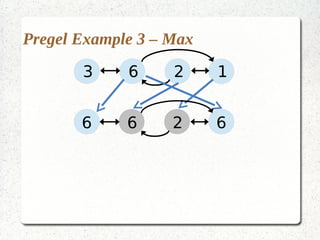
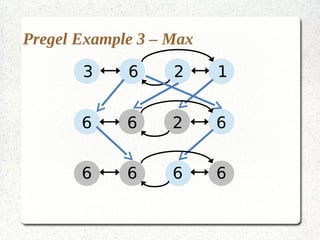
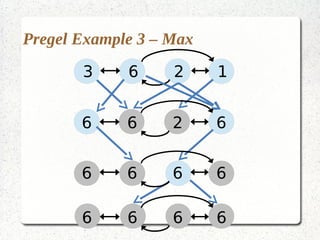





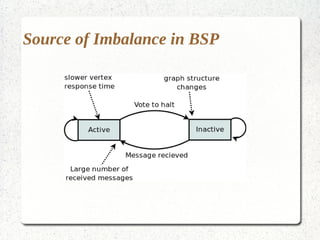
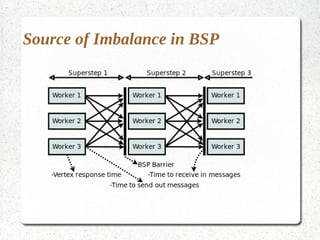

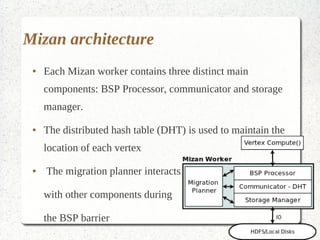
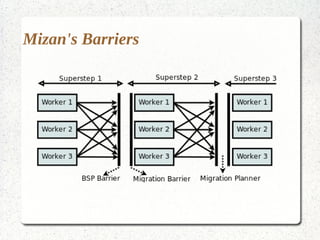
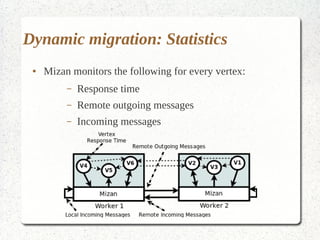

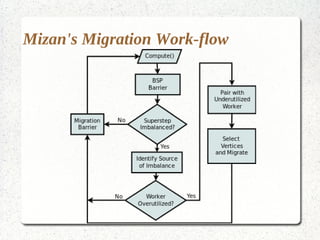





This document discusses large-scale graph processing and the challenges involved. It introduces Pregel, an influential graph processing system based on the bulk synchronous parallel model. Key aspects of Pregel are explained such as its vertex-centric approach, use of supersteps with messaging between steps, and guarantees of message delivery. The document also discusses Mizan, a graph processing system developed locally that aims to improve load balancing through dynamic graph partitioning between supersteps. Examples of graph algorithms like PageRank and Max are provided in the Pregel and Mizan models. Finally, the class is assigned to install and run Mizan on a single machine following an online tutorial.












![[Capella Day 2019] Model execution and system simulation in Capella](https://cdn.slidesharecdn.com/ss_thumbnails/modelexecutionandsystemsimulationincapellav1-191001130117-thumbnail.jpg?width=640&height=640&fit=bounds)































































