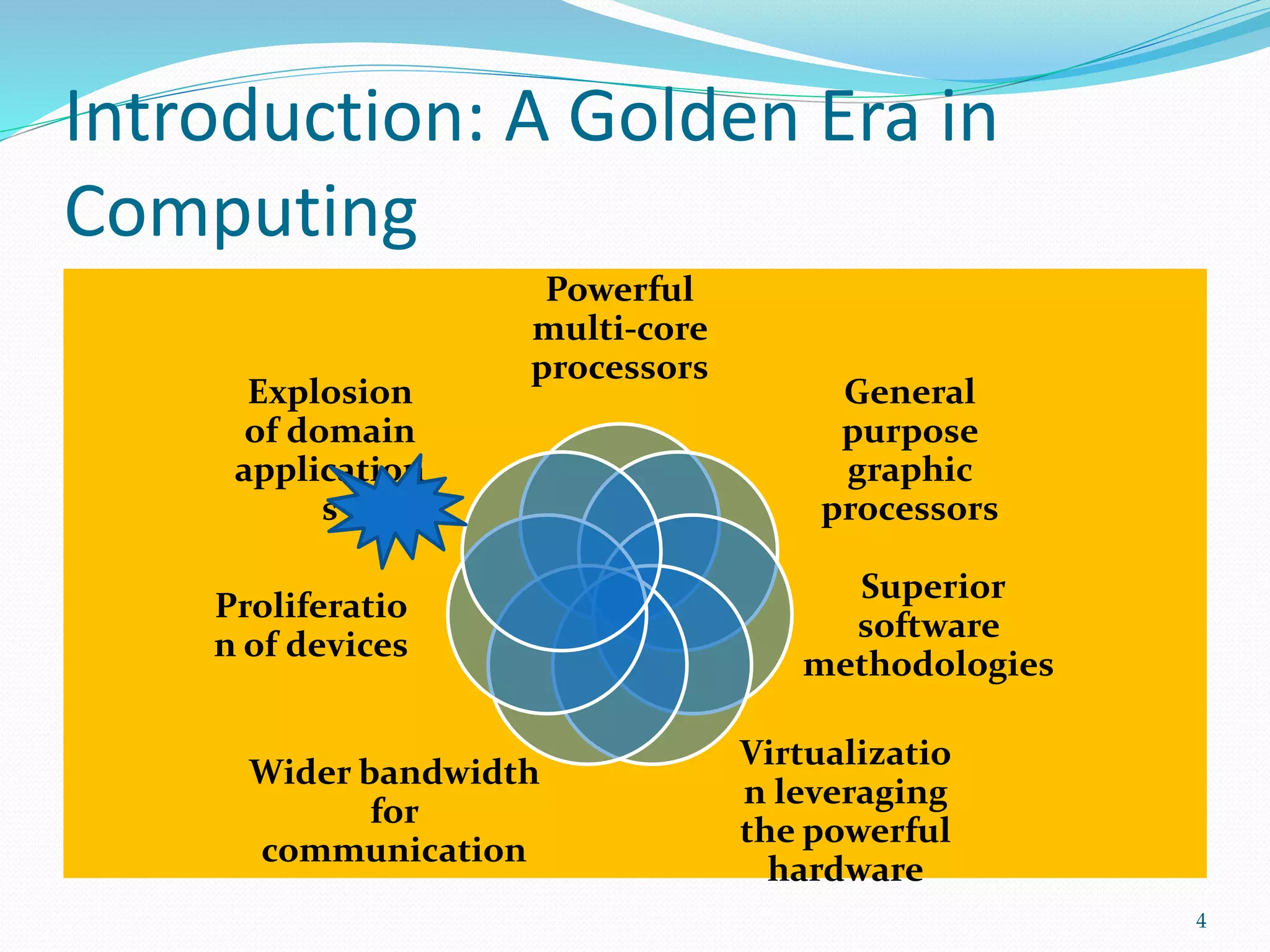
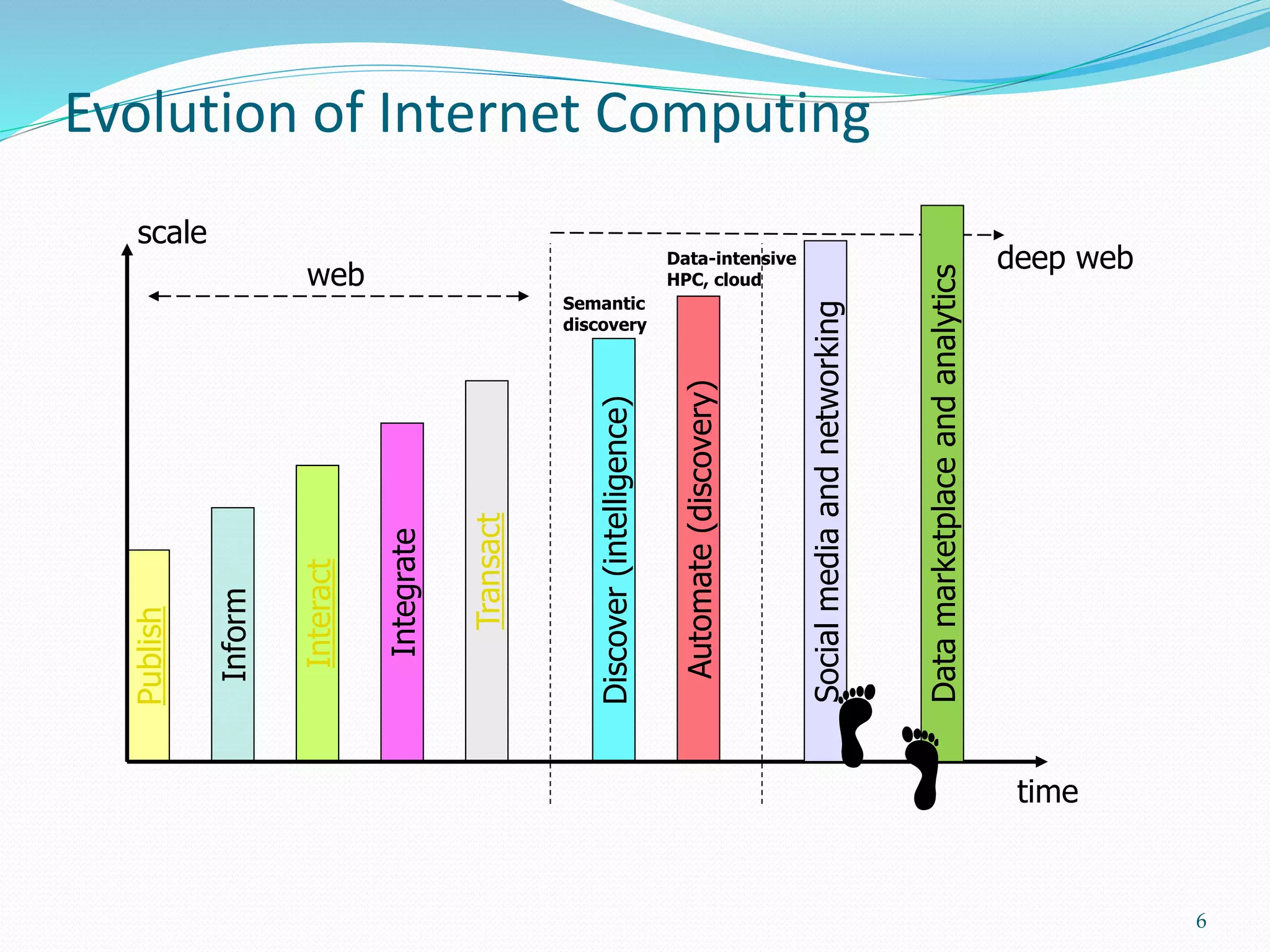
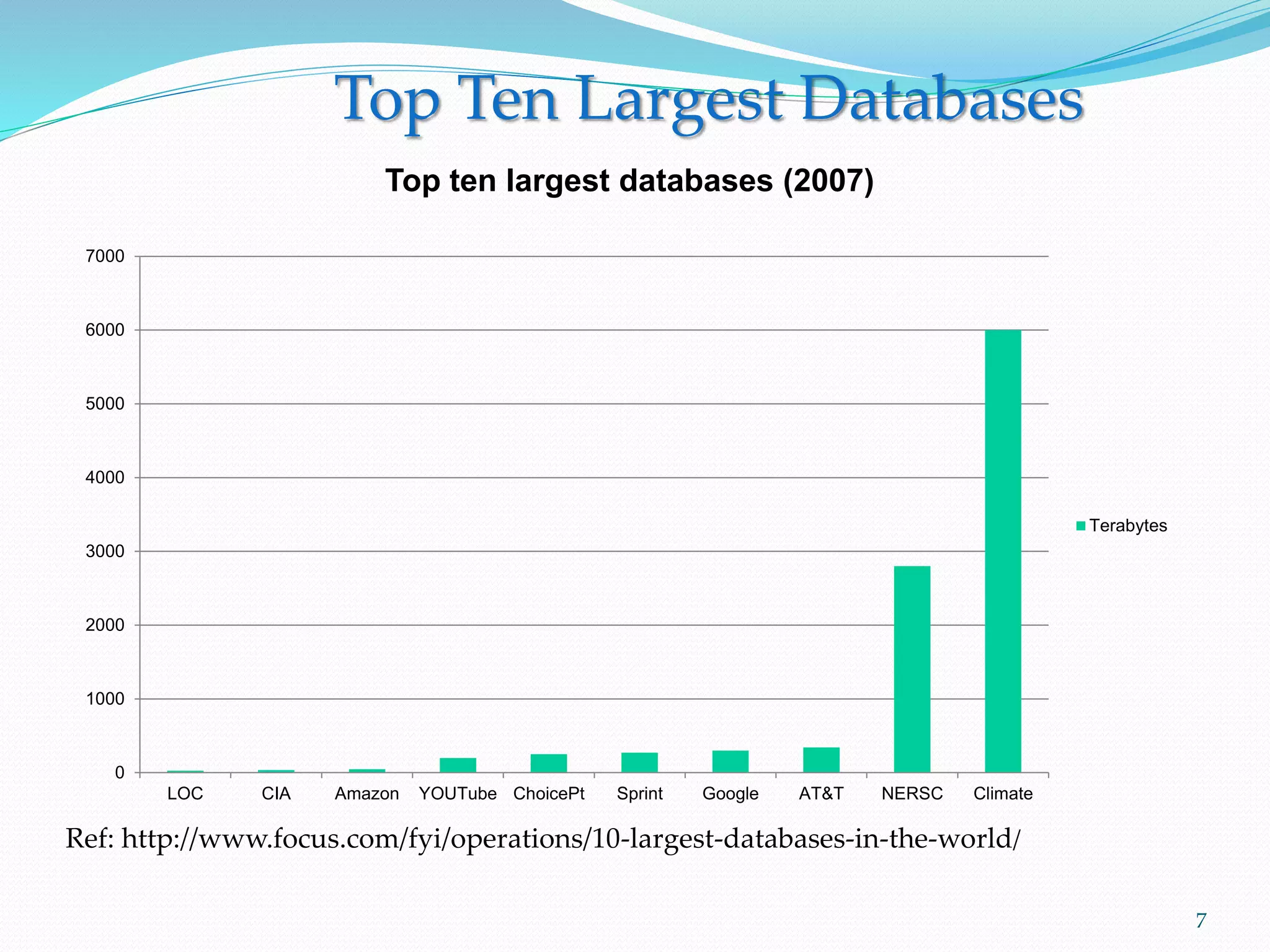
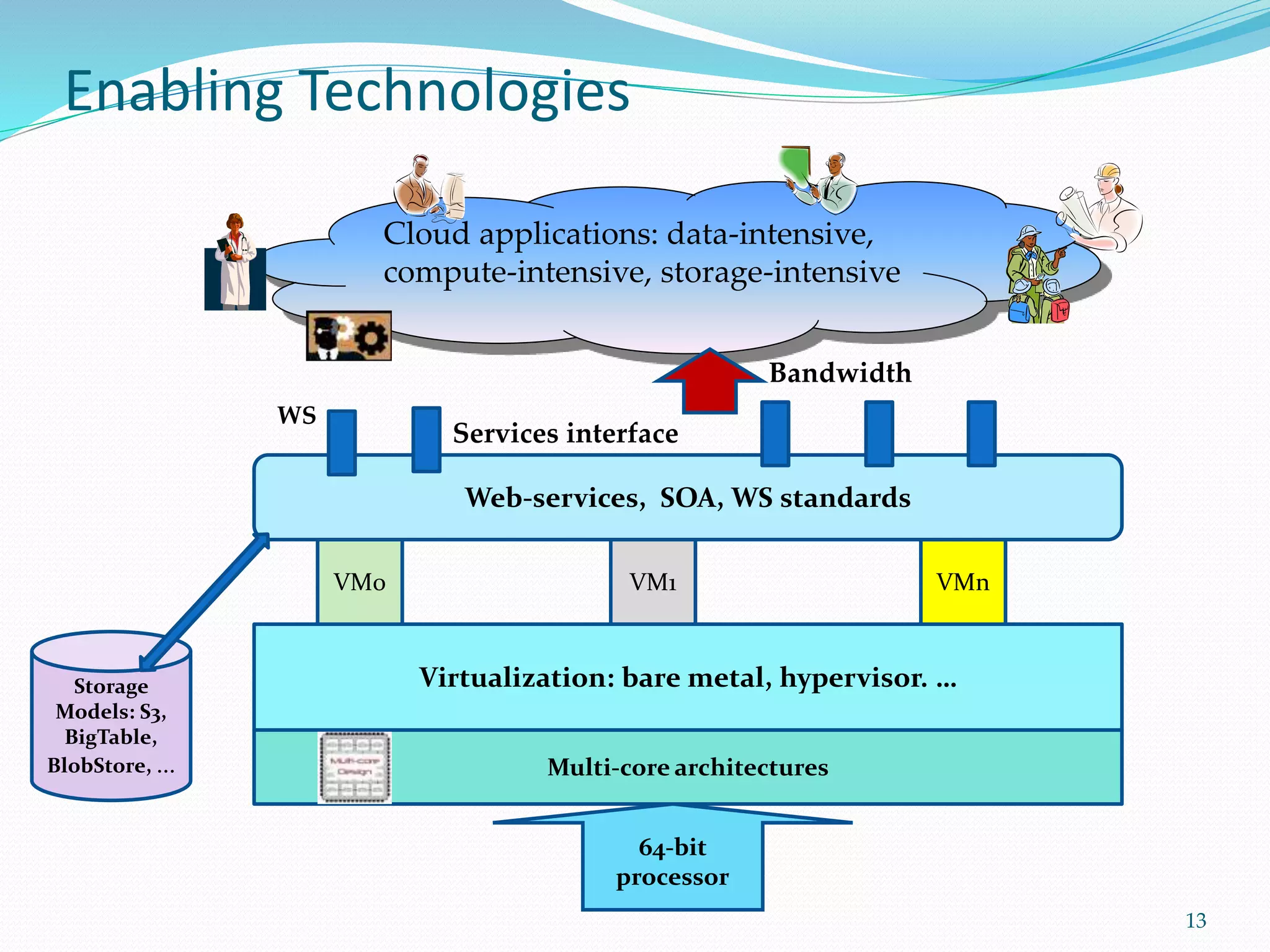
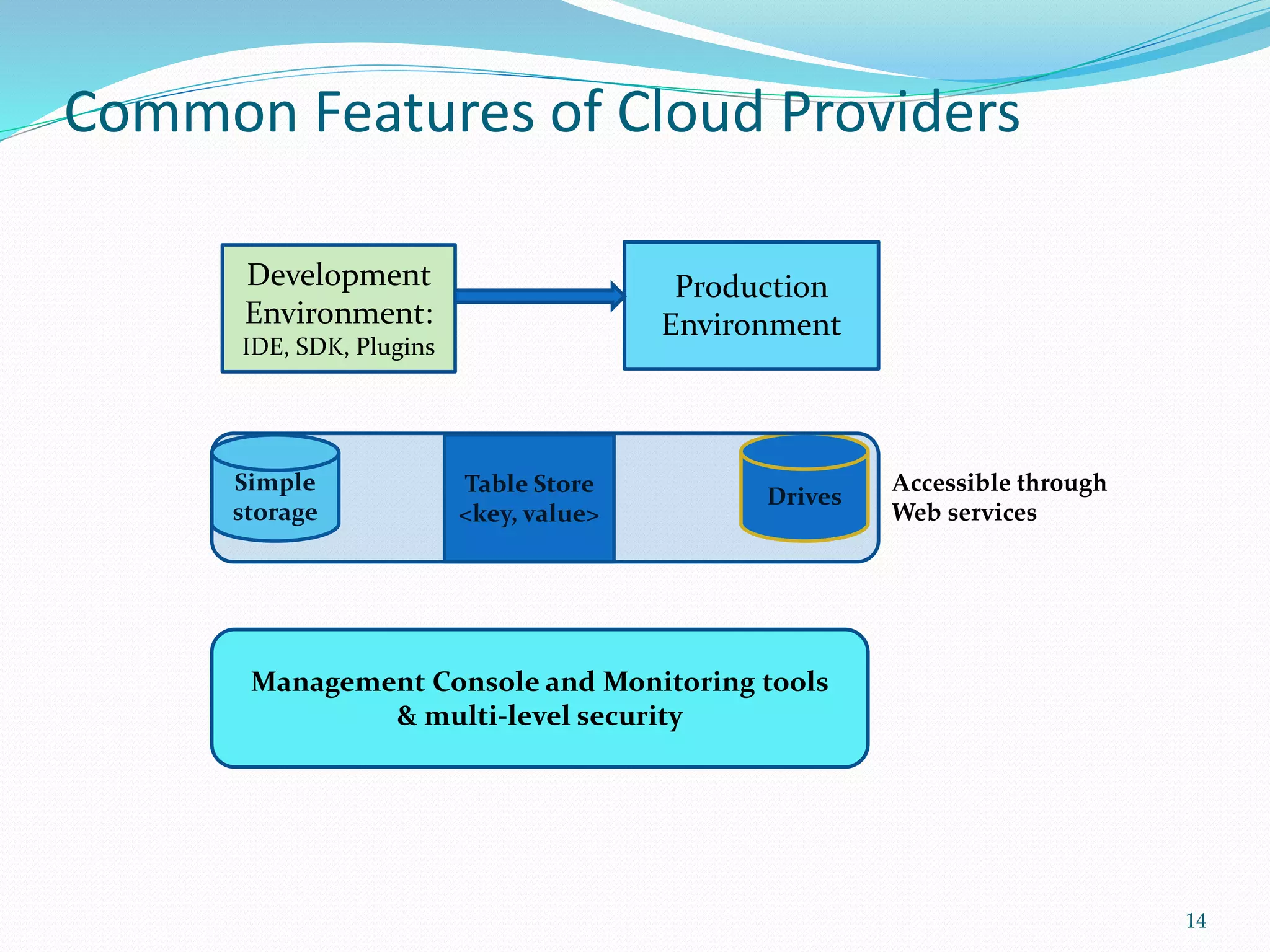
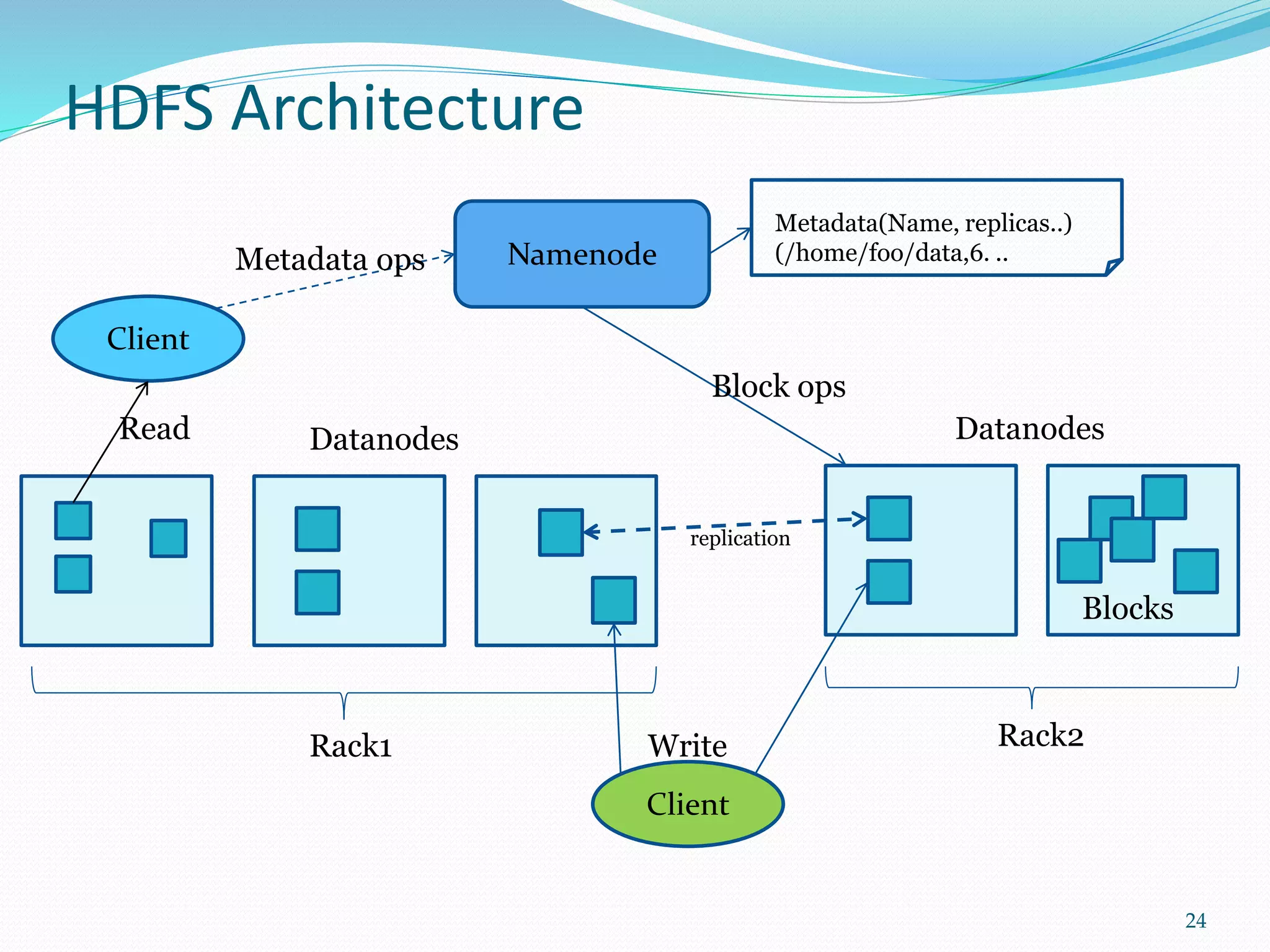
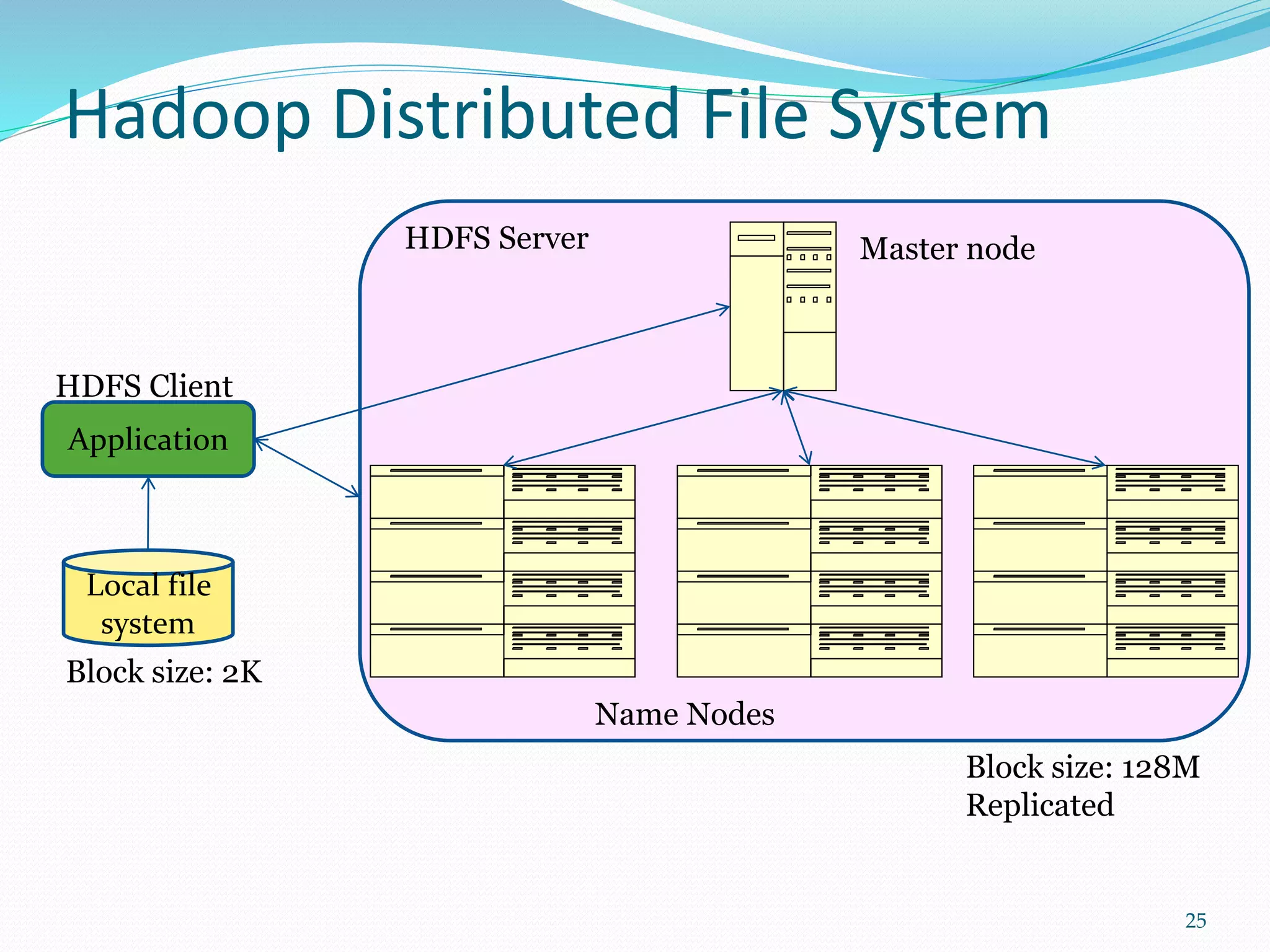
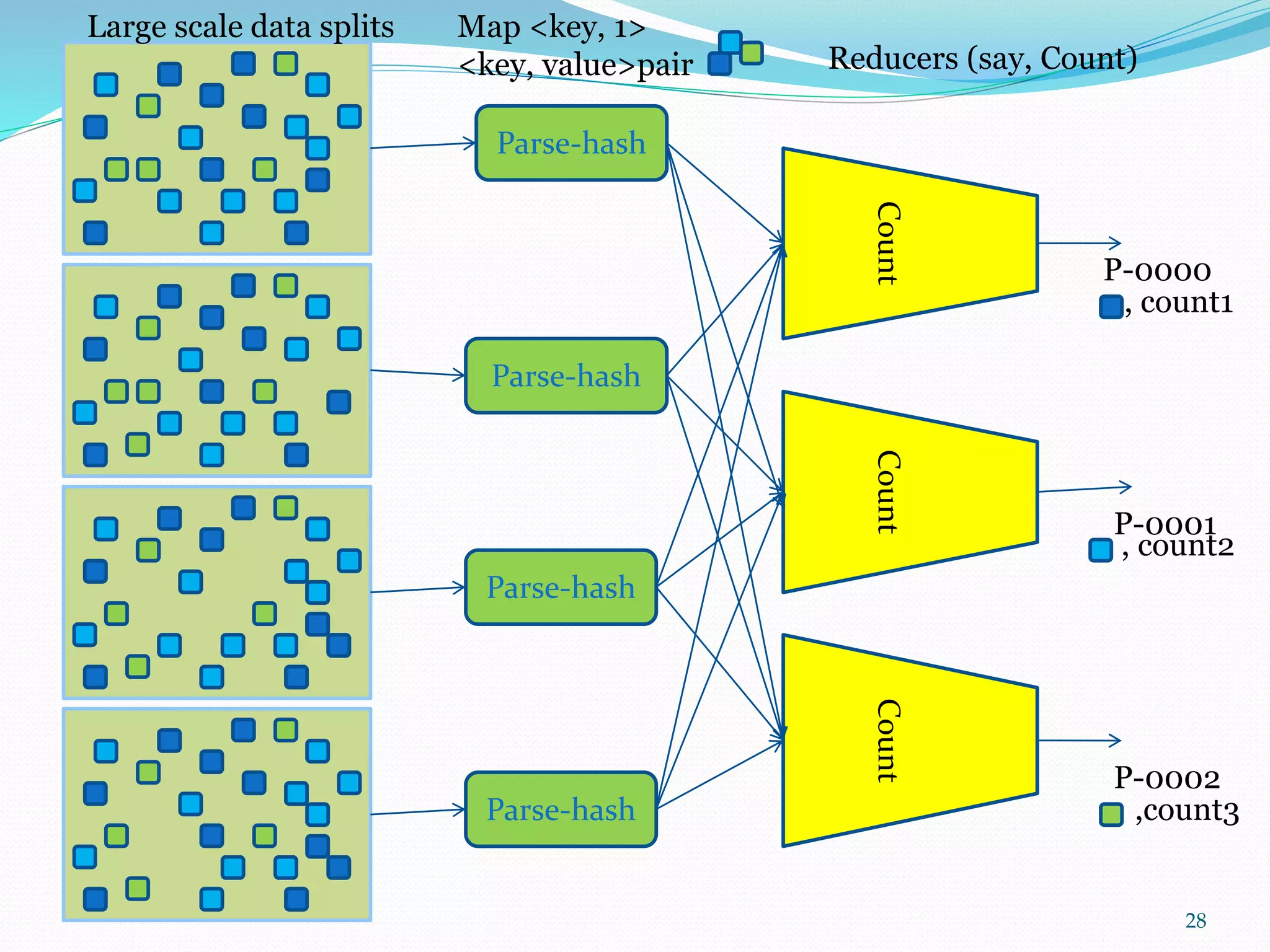
This document provides an outline for a talk on cloud computing. It begins with an introduction to cloud concepts and technologies like virtualization and parallel computing models. It then discusses different cloud models including IaaS, PaaS and SaaS. The outline includes demonstrations of cloud capabilities with Amazon AWS and Microsoft Azure, as well as data and computing models using MapReduce. It concludes with a case study of a real business application of the cloud and a question and answer section.




















































































![Automating ISP Networks Using Ansible and IPAM as a Source of Truth [SoT]](https://cdn.slidesharecdn.com/ss_thumbnails/automatingispnetworksusingansibleandipamasasourceoftruthsot-v25-1-251124105117-d7d4ca24-thumbnail.jpg?width=640&height=640&fit=bounds)













