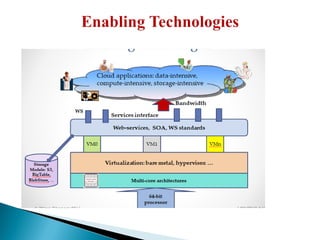
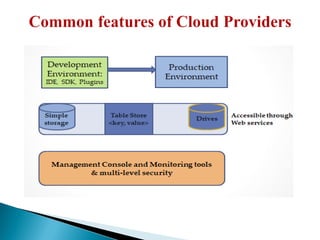
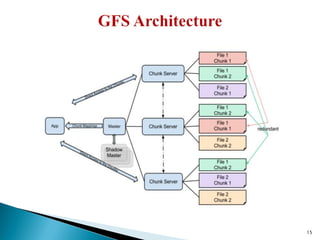
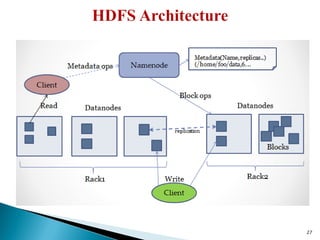
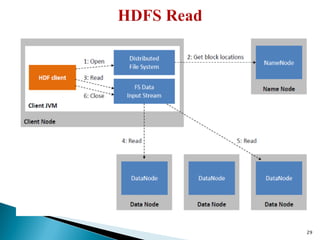
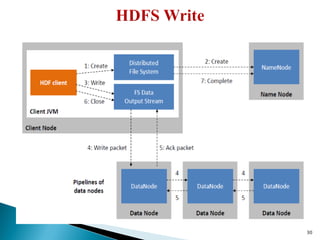
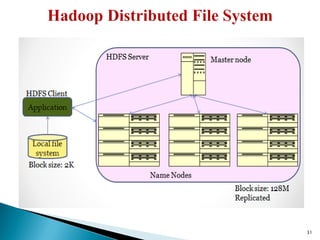
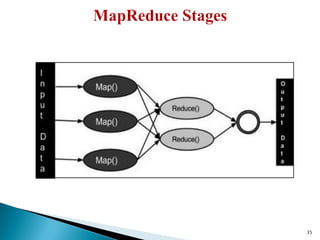
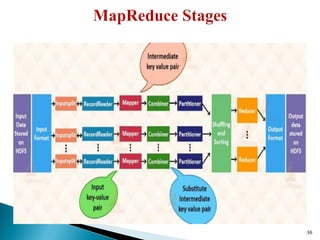
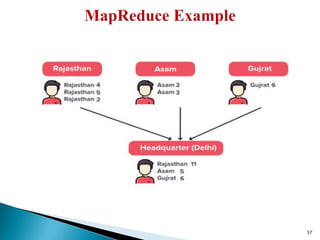
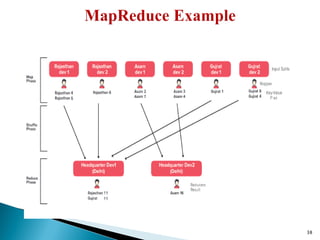
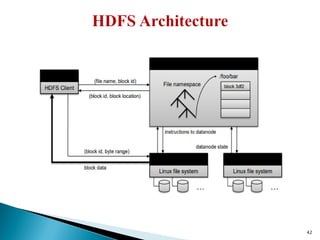
The document provides a comprehensive overview of cloud computing technologies, specifically focusing on cloud file systems like GFS and HDFS, as well as NoSQL databases such as DynamoDB. It discusses various computing models, including grid computing and MapReduce, their applications, advantages, and limitations. Additionally, it emphasizes the importance of cloud security measures to protect infrastructure, applications, and data from various threats.