Downloaded 275 times







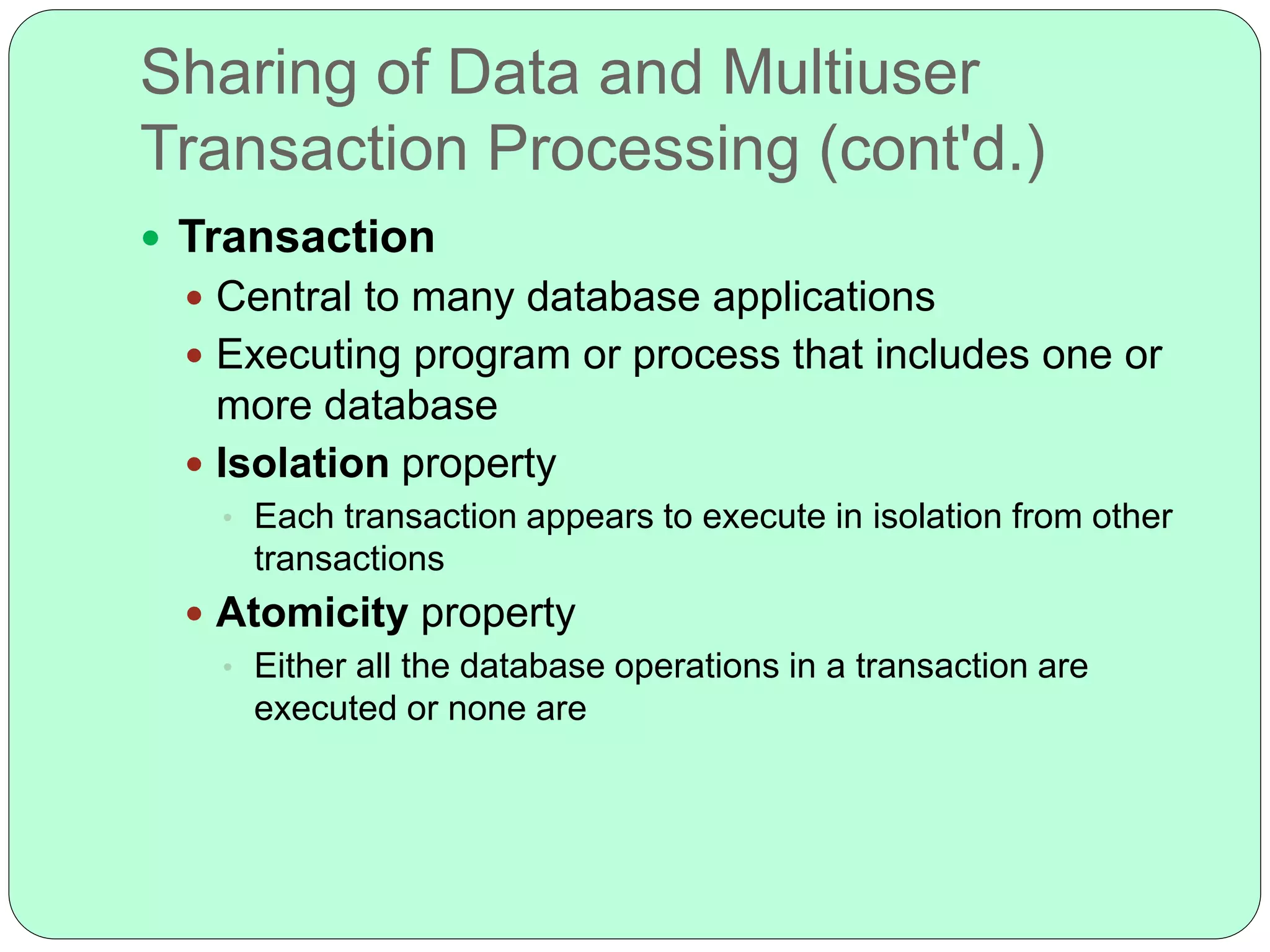









The key characteristics of the database approach include: self-describing metadata that defines the database structure; insulation between programs and data through program-data and program-operation independence; data abstraction through conceptual data representation; support for multiple views of the data; and sharing of data through multiuser transaction processing that allows concurrent access while maintaining isolation and atomicity.


![Data Models [DATABASE SYSTEMS: Design, Implementation, and Management]](https://cdn.slidesharecdn.com/ss_thumbnails/coronelpptch02-datamodels-190903105908-thumbnail.jpg?width=640&height=640&fit=bounds)




















































































