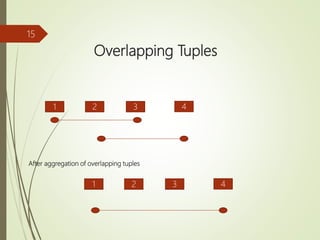
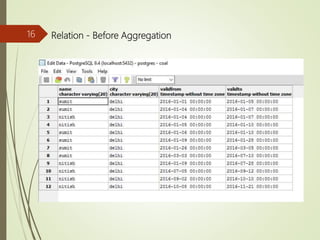
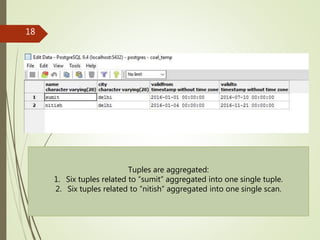
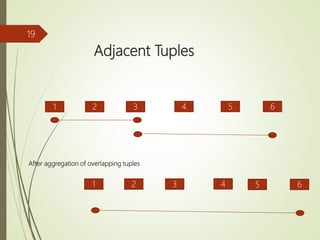
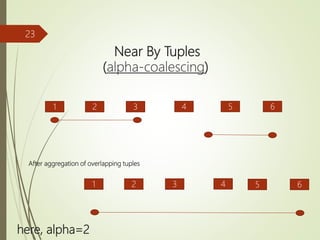
The document presents a study on implementing temporal aggregation functions through user defined aggregate (UDA) functions. It discusses aggregating tuples that are adjacent, overlapping, or near each other in timestamp. Algorithms are presented for aggregating adjacent tuples, overlapping tuples, and near by tuples within a threshold. The algorithms perform aggregation by scanning the relation once. Literature on parsimonious temporal aggregation and supporting temporal queries efficiently in databases is also summarized.








![Contd.
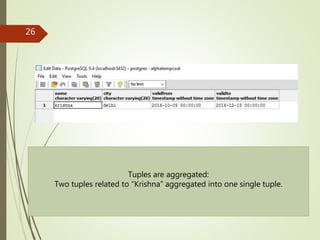
• Merge operator
Let s be an ITA result relation with schema
S = (A1, . . . , Ak , B1, . . . , Bp, T), where
A = {A1, . . . , Ak } are the grouping attributes and
B = {B1, . . . , Bp} store the aggregate values.
The merge, ⊕, of two adjacent tuples, si , s j ∈ s, si ≺ s j , is defined as
si ⊕ s j = (si .A1, . . . , si .Ak, v1, . . . , vp, [si .Tb, s j .Te]),
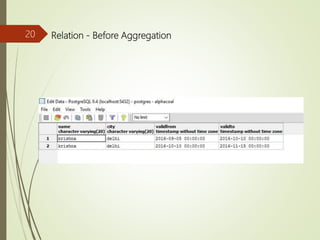
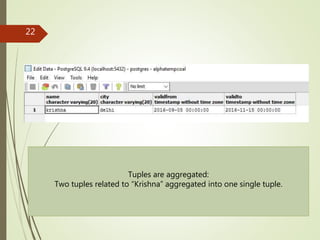
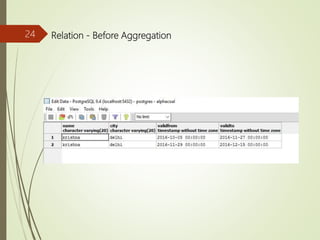
The merge operator produces a new tuple.
8](https://image.slidesharecdn.com/nitish-007-161129160114/85/Nitish-007-8-320.jpg)









![Literature Survey
Parsimonious temporal aggregation[1].
A novel temporal aggregation operator, termed parsimonious temporal
aggregation (PTA), that overcomes major limitations of existing approaches. PTA
takes the result of instant temporal aggregation (ITA) of size n, which might be up
to twice as large as the argument relation, and merges similar tuples until a given
error (e) or size (c) bound is reached. The new operator is data-adaptive and allows
the user to control the trade-off between the result size and the error introduced
by merging. For the precise evaluation of PTA queries, we propose two dynamic
programming-based algorithms for size and error-bounded queries, respectively,
with a worst-case complexity that is quadratic in n. For the quick computation of
an approximate PTA answer, we propose an efficient greedy merging strategy with
a precision that is upper bounded by O(log n). We present two algorithms that
implement this strategy and begin to merge as ITA tuples are produced. They
require O(n log(c + β)) time and O(c + β) space, where β is the size of a read-ahead
buffer and is typically very small.
27](https://image.slidesharecdn.com/nitish-007-161129160114/85/Nitish-007-27-320.jpg)
![Contd.
Efficient temporal coalescing query support in relational database systems[3].
An SQL: 2003-based query algorithm and a native relational user defined
aggregates (UDA) approach – both approaches only require a single scan of the
database. They conclude that temporal queries can be best supported by OLAP
functions supported in the current SQL: 2003 standards. These new findings
demonstrate that the current RDBMSs are mature enough to directly support
efficient temporal queries, and provide a new paradigm for temporal database
research and implementation.
28](https://image.slidesharecdn.com/nitish-007-161129160114/85/Nitish-007-28-320.jpg)


![Reference
[1] Gordevičius, Juozas, Johann Gamper, and Michael Böhlen. "Parsimonious temporal
aggregation." The VLDB Journal 21.3 (2012): 309-332.
[2] Pilman, Markus, et al. "ParTime: Parallel Temporal Aggregation." Proceedings of the 2016
International Conference on Management of Data. ACM, 2016.
[3] Zhou, Xin, Fusheng Wang, and Carlo Zaniolo. "Efficient temporal coalescing query support
in relational database systems." International Conference on Database and Expert Systems
Applications. Springer Berlin Heidelberg, 2006.
[4] Cheng, Kai. "Approximate Temporal Aggregation with Nearby Coalescing." International
Conference on Database and Expert Systems Applications. Springer International Publishing,
2016.
31](https://image.slidesharecdn.com/nitish-007-161129160114/85/Nitish-007-31-320.jpg)




















































































