Downloaded 71 times











![Nova Recommendations
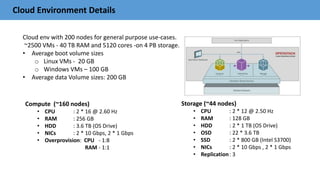
• What is Nova ?
• Configuration settings: /etc/nova/nova.conf
• Use librados (instead of krdb).
[libvirt]
# enable discard support (be careful of perf)
hw_disk_discard = unmap
# disable password injection
inject_password = false
# disable key injection
inject_key = false
# disable partition injection
inject_partition = -2
# make QEMU aware so caching works
disk_cachemodes = "network=writeback"
live_migration_flag="VIR_MIGRATE_UNDEFINE_SOURCE,VIR_MIGRATE_PEER2PEER,
VIR_MIGRATE_LIVE,VIR_MIGRATE_PERSIST_DEST“](https://image.slidesharecdn.com/ceph-barcelona-v-1-161121051504/85/Ceph-barcelona-v-1-2-15-320.jpg)





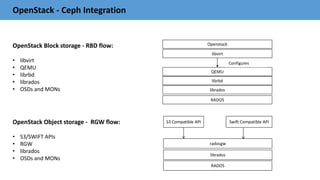
![OS Considerations
• Kernel: Latest stable release
• BIOS : Enable HT (hyperthreading) and VT(Virtualization Technology).
• Kernel PID max:
• Read ahead: Set in all block devices
• Swappiness:
• Disable NUMA : Disabled by passing the numa_balancing=disable parameter to the kernel.
• The same parameter could be controlled via the kernel.numa_balancing sysctl:
• CPU Tuning: Set “performance” mode use 100% CPU frequency always.
• I/O Scheduler:
# echo “4194303” > /proc/sys/kernel/pid_max
# echo "8192" > /sys/block/sda/queue/read_ahead_kb
# echo "vm.swappiness = 0" | tee -a /etc/sysctl.conf
# echo 0 > /proc/sys/kernel/numa_balancing
SATA/SAS Drives: # echo "deadline" > /sys/block/sd[x]/queue/scheduler
SSD Drives : # echo "noop" > /sys/block/sd[x]/queue/scheduler
# echo "performance" | sudo tee /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor](https://image.slidesharecdn.com/ceph-barcelona-v-1-161121051504/85/Ceph-barcelona-v-1-2-21-320.jpg)





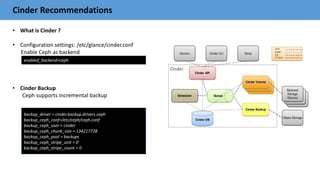
![Ceph Ops Recommendations
• Decreasing recovery and backfilling performance impact
• Settings for recovery and backfilling :
Note: The above setting will slow down the recovery/backfill process and prolongs the recovery process, if we decrease the values.
Increasing these settings value will increase recovery/backfill performance, but decrease client performance and vice versa
‘osd max backfills’ - maximum backfills allowed to/from a OSD [default 10]
‘osd recovery max active’ - Recovery requests per OSD at one time. [default 15]
‘osd recovery threads’ - The number of threads for recovering data. [default 1]
‘osd recovery op priority’ - Priority for recovery Ops. [ default 10]](https://image.slidesharecdn.com/ceph-barcelona-v-1-161121051504/85/Ceph-barcelona-v-1-2-27-320.jpg)







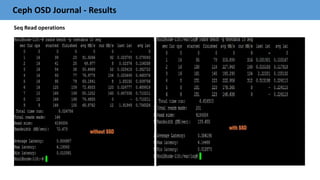
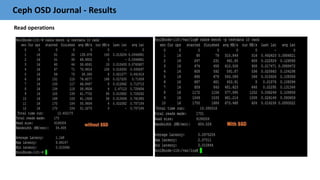

The document outlines best practices and performance tuning for OpenStack cloud storage using Ceph, presented at the OpenStack Summit in Barcelona. It covers integration recommendations, configuration settings for key components like Glance, Cinder, and Nova, as well as optimization strategies for Ceph clusters. The discussion includes guidelines for network configuration, failure domains, and performance measurement essential for efficient deployment and management of Ceph in cloud environments.



































































