Download as PDF, PPTX








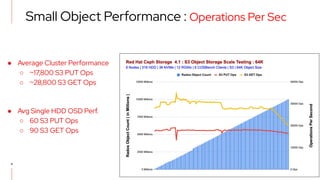


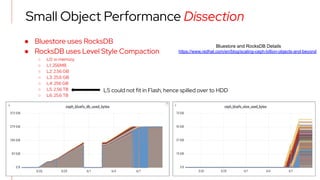
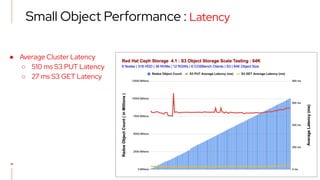






The document details a scale testing of Red Hat Ceph Storage (RHCS) with over 10 billion objects, showcasing its deterministic performance for both small and large object workloads. Key results include an average of 17,800 S3 put operations and 28,800 S3 get operations per second across 318 HDDs and 36 NVMe devices, with findings indicating acceptable performance during failure scenarios. The testing demonstrates RHCS's capability to exceed current limits, affirming its viability for high-scale object storage applications.








![[OpenInfra Days Korea 2018] Day 2 - CEPH 운영자를 위한 Object Storage Performance T...](https://cdn.slidesharecdn.com/ss_thumbnails/openinfradayobjectstorageperformancefinal2-180704062033-thumbnail.jpg?width=640&height=640&fit=bounds)

![[OpenStack Days Korea 2016] Track1 - All flash CEPH 구성 및 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/12skt-160226171513-thumbnail.jpg?width=640&height=640&fit=bounds)



















































![Lect 1 Number systems and base conversions. [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/lect1numbersystemsandbaseconversions-260111134109-67c2d865-thumbnail.jpg?width=640&height=640&fit=bounds)




