Downloaded 89 times





![10
● OSD carefully manages
consistency of its data
● All writes are transactions
– we need A+C+D; OSD provides I
● Most are simple
– write some bytes to object (file)
– update object attribute (file
xattr)
– append to update log (leveldb
insert)
...but others are arbitrarily
large/complex
[
{
"op_name": "write",
"collection": "0.6_head",
"oid": "#0:73d87003:::benchmark_data_gnit_10346_object23:head#",
"length": 4194304,
"offset": 0,
"bufferlist length": 4194304
},
{
"op_name": "setattrs",
"collection": "0.6_head",
"oid": "#0:73d87003:::benchmark_data_gnit_10346_object23:head#",
"attr_lens": {
"_": 269,
"snapset": 31
}
},
{
"op_name": "omap_setkeys",
"collection": "0.6_head",
"oid": "#0:60000000::::head#",
"attr_lens": {
"0000000005.00000000000000000006": 178,
"_info": 847
}
}
]
POSIX FAILS: TRANSACTIONS](https://image.slidesharecdn.com/20160621bluestore-160624154640/85/Ceph-Tech-Talk-Bluestore-10-320.jpg)









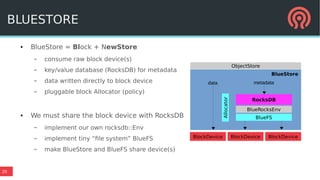
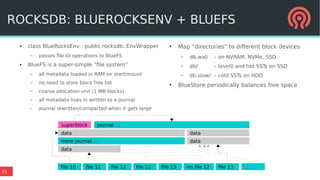








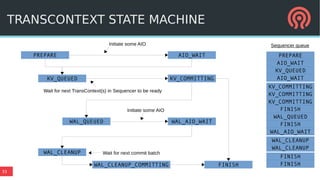





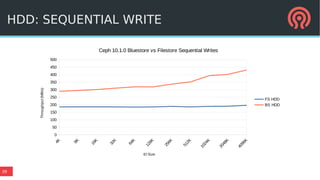
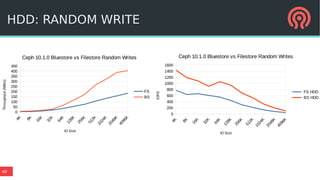
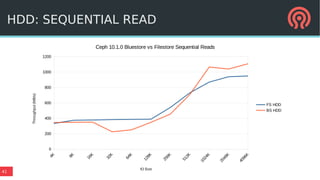
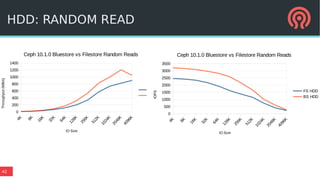






BlueStore is a new storage backend for Ceph that stores data directly on block devices rather than using a file system. It uses RocksDB to store metadata like a key-value database and pluggable block allocation policies to improve performance. BlueStore aims to provide more natural transaction support without double writes by using a write-ahead log. It also supports multiple storage devices to optimize placement of metadata, data and write-ahead logs.




















![[Bespin Global 파트너 세션] 분산 데이터 통합 (Data Lake) 기반의 데이터 분석 환경 구축 사례 - 베스핀 글로벌 장익...](https://cdn.slidesharecdn.com/ss_thumbnails/session5-datalakebaseddataanalyticsenvironmentimplementationcaseexamplebespinglobal-190903082707-thumbnail.jpg?width=640&height=640&fit=bounds)





![[2018] MySQL 이중화 진화기](https://cdn.slidesharecdn.com/ss_thumbnails/cloudinfra03-190131073325-thumbnail.jpg?width=640&height=640&fit=bounds)








































