Downloaded 39 times

















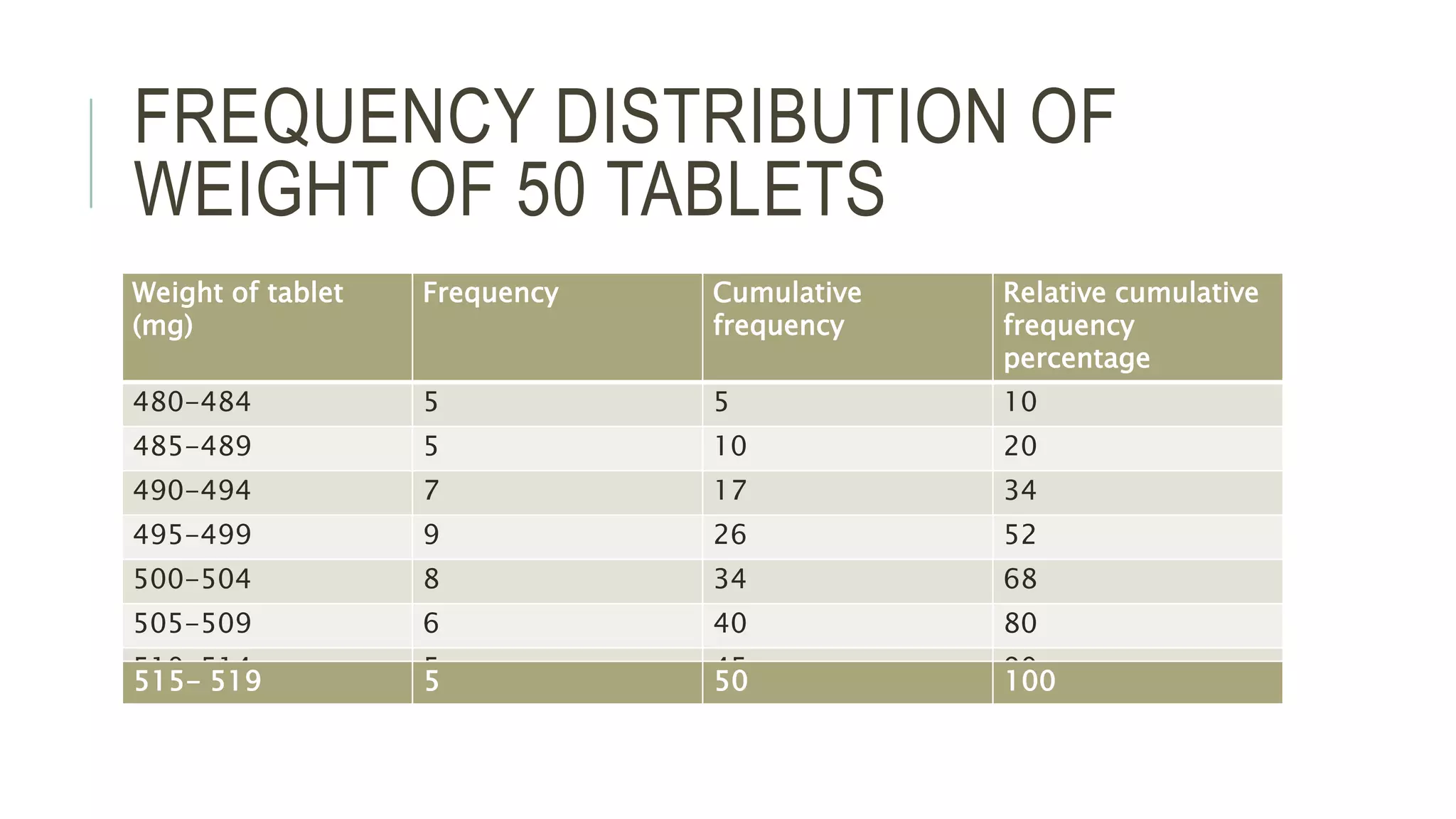



Biostatistics is a specialized branch of statistics that applies statistical methods to biological and medical research, emphasizing the importance of data analysis in areas such as health, medicine, and public health. It includes various categories like medical statistics, health statistics, and vital statistics, and employs tools for data collection and hypothesis generation. Frequency distributions are key in summarizing observations and analyzing data, aiding in the understanding of trends and characteristics in research.















































