Downloaded 1,225 times






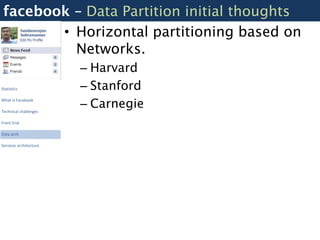


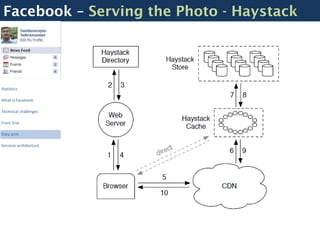
![Facebook – Scribe - Logging
Nodes Nodes Nodes
Scribe Scribe Scribe
Statistics
What is Facebook
Technical challenges
Front End $messages = array();
$entry = new LogEntry;
Data arch
Central Scribe Server $entry->category = "buckettest";
Services architecture $entry->message = "something very”;
$messages []= $entry;
$result = $conn->Log($messages);
Dashboards
HBase](https://image.slidesharecdn.com/opentalk-facebookarchitecture-120103014701-phpapp02/85/Facebook-Architecture-Breaking-it-Open-13-320.jpg)



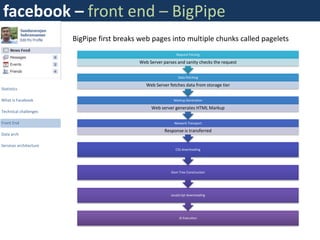
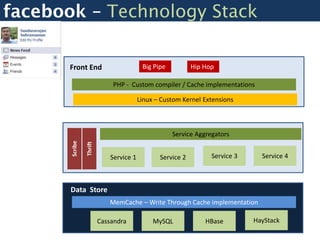
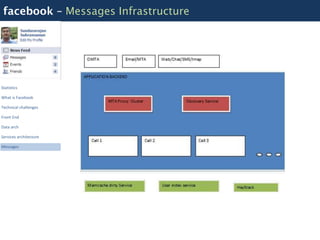
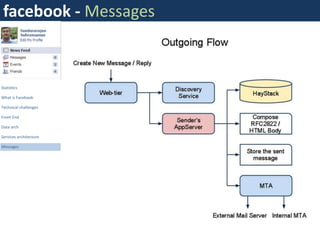
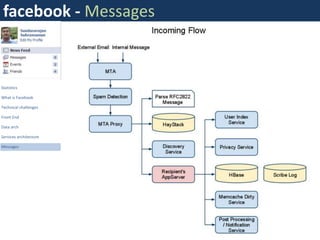
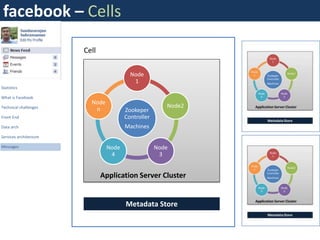






Facebook uses a distributed systems architecture with services like Memcache, Scribe, Thrift, and Hip Hop to handle large data volumes and high concurrency. Key components include the Haystack photo storage system, BigPipe for faster page loading, and a PHP front-end optimized using Hip Hop. Data is partitioned horizontally and services communicate using lightweight protocols like Thrift.












































![Facebook[The Nuts and Bolts Technology]](https://cdn.slidesharecdn.com/ss_thumbnails/facebookthenutsandbolts-technology-160206142954-thumbnail.jpg?width=640&height=640&fit=bounds)










































