Downloaded 359 times













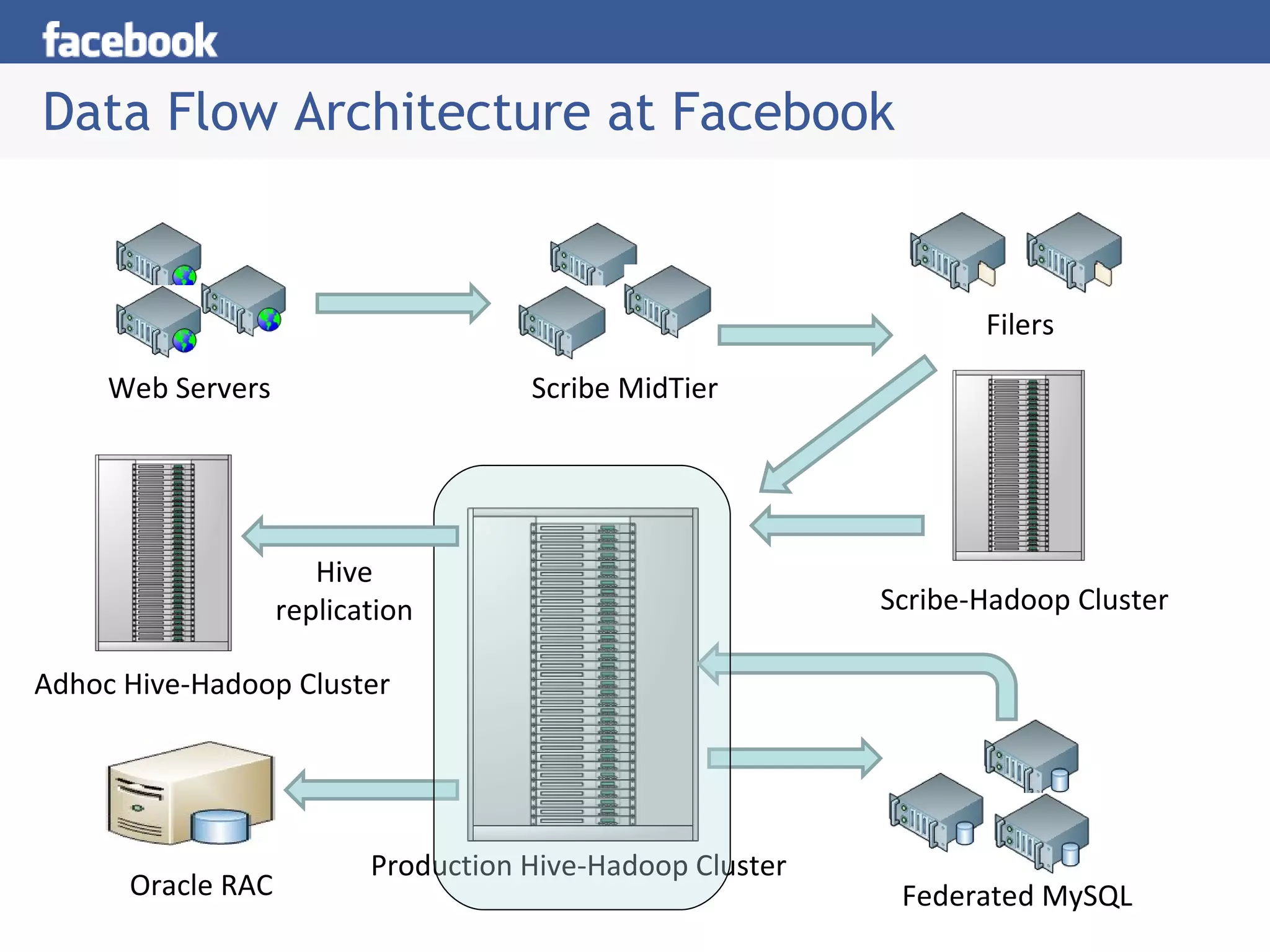






The document discusses Hive, a system for managing and querying large datasets stored in Hadoop. It describes how Hive provides a familiar SQL-like interface, simplifying Hadoop programming. The document also outlines how Facebook uses Hive and Hadoop for analytics, with over 4TB of new data added daily across a large cluster.











































































































