The document provides an overview of Hadoop including:
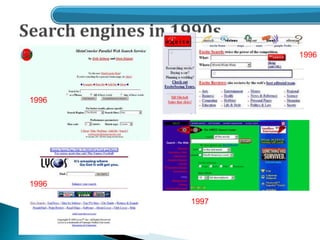
- A brief history of Hadoop and its origins from Nutch.
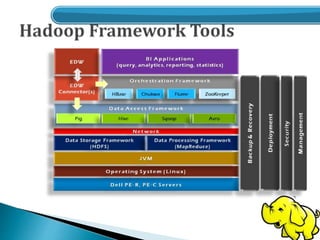
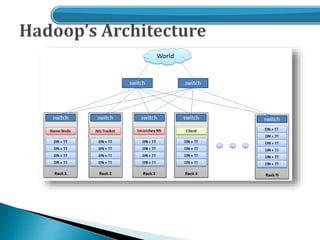
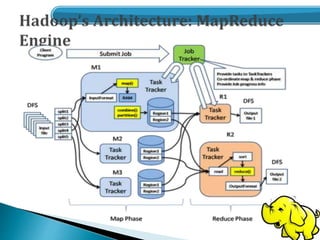
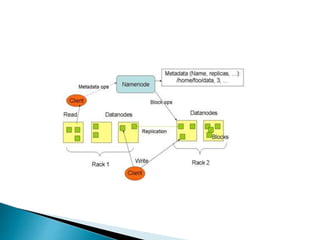
- An overview of the Hadoop architecture including HDFS and MapReduce.
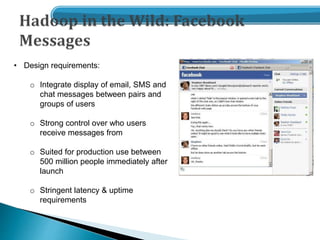
- Examples of how companies like Yahoo, Facebook and Amazon use Hadoop at large scales to process petabytes of data.































![ Check input and output, e.g. check if the
output directory is already existing
◦ job.getInputFormat().validateInput(job);
◦ job.getOutputFormat().checkOutputSpecs(fs, job);
Get InputSplits, sort, and write output to
HDFS
◦ InputSplit[] splits = job.getInputFormat().
getSplits(job, job.getNumMapTasks());
◦ writeSplitsFile(splits, out); // out is
$SYSTEMDIR/$JOBID/job.split](https://image.slidesharecdn.com/hadoop-160505200402/85/Hadoop-introduction-39-320.jpg)




![ splits = JobClient.readSplitFile(splitFile);
numMapTasks = splits.length;
maps[i] = new TaskInProgress(jobId, jobFile,
splits[i], jobtracker, conf, this, i);
reduces[i] = new TaskInProgress(jobId,
jobFile, splits[i], jobtracker, conf, this, i);
JobStatus --> JobStatus.RUNNING](https://image.slidesharecdn.com/hadoop-160505200402/85/Hadoop-introduction-44-320.jpg)




























































































