Download as PDF, PPTX
























![Hello, Gelly!
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSet<Edge<Long, NullValue>> edges = getEdgesDataSet(env);
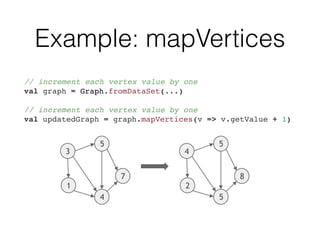
Graph<Long, Long, NullValue> graph = Graph.fromDataSet(edges, env);
DataSet<Vertex<Long, Long>> verticesWithMinIds = graph.run(
new ConnectedComponents(maxIterations));
val env = ExecutionEnvironment.getExecutionEnvironment
val edges: DataSet[Edge[Long, NullValue]] = getEdgesDataSet(env)
val graph = Graph.fromDataSet(edges, env)
val components = graph.run(new ConnectedComponents(maxIterations))
Java
Scala](https://image.slidesharecdn.com/euyhp0oaqu6qqdkv5rjj-signature-6fe544449570fe865ee69576788443e9f2a460c054bc487b931c5a8fc4ae1047-poli-161108090811/85/Apache-Flink-Graph-Processing-36-320.jpg)

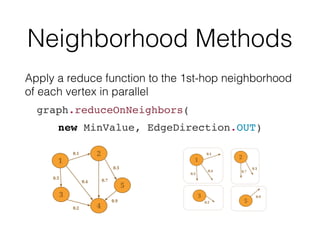
![Example: subGraph
val graph: Graph[Long, Long, Long] = ...
// keep only vertices with positive values
// and only edges with negative values
val subGraph = graph.subgraph(
vertex => vertex.getValue > 0,
edge => edge.getValue < 0
)](https://image.slidesharecdn.com/euyhp0oaqu6qqdkv5rjj-signature-6fe544449570fe865ee69576788443e9f2a460c054bc487b931c5a8fc4ae1047-poli-161108090811/85/Apache-Flink-Graph-Processing-39-320.jpg)




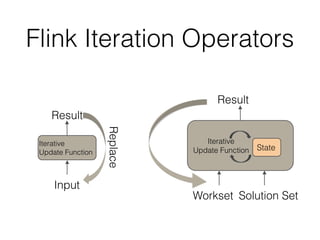
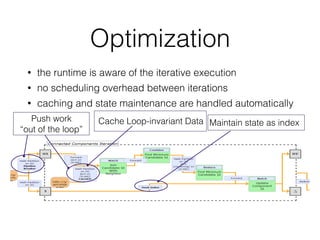

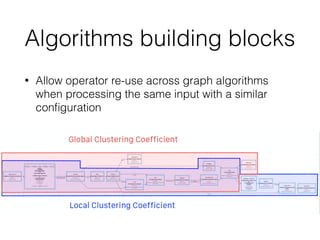

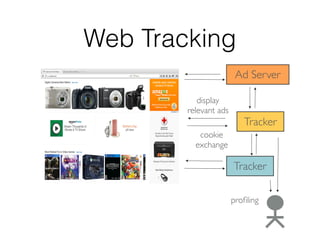
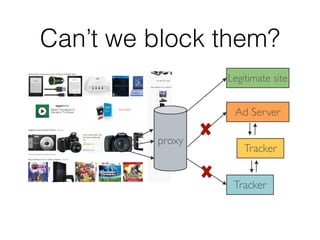


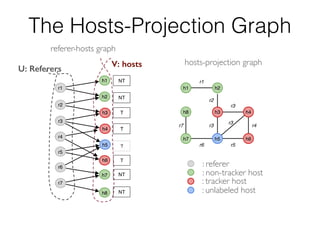
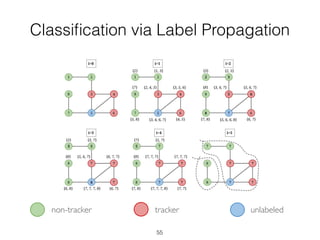
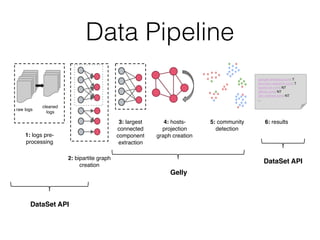








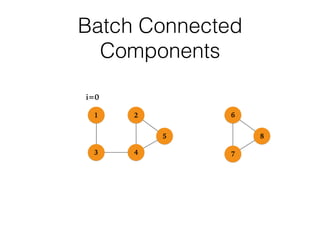


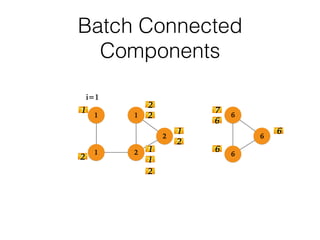
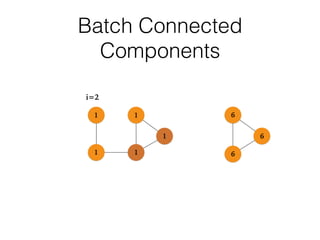
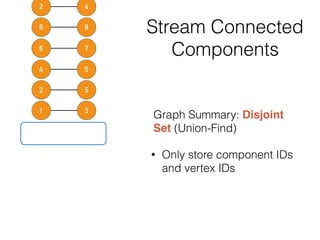
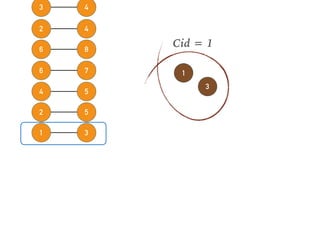
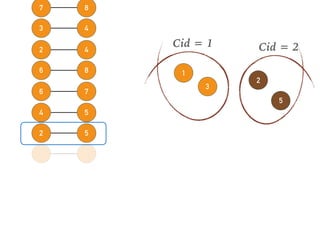
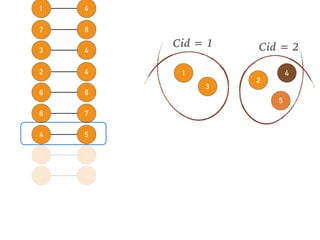
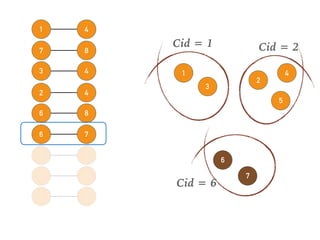
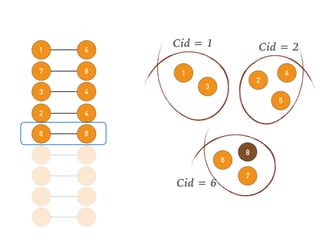
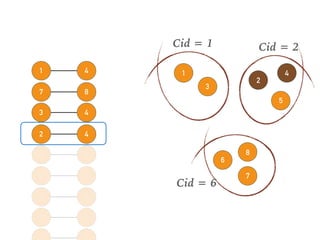

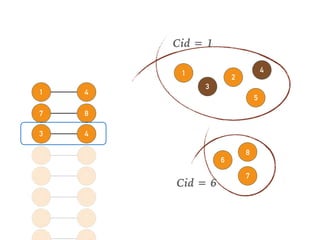






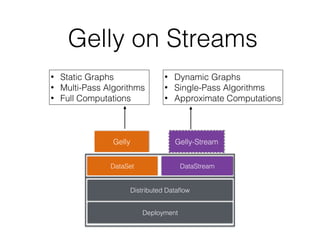


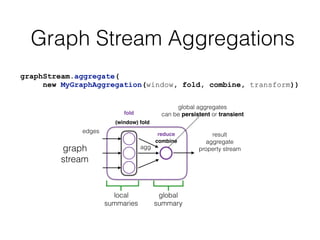
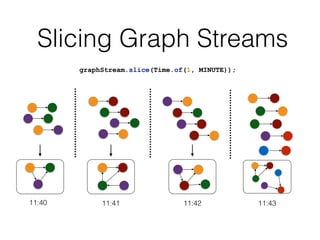

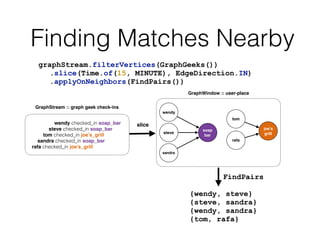



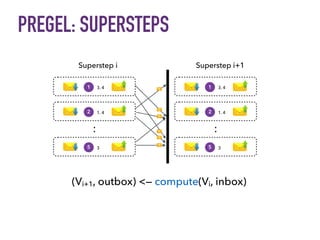
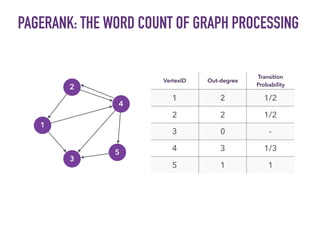
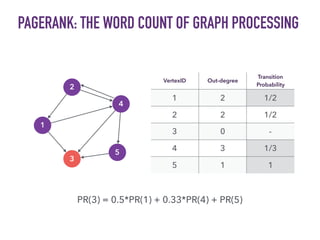
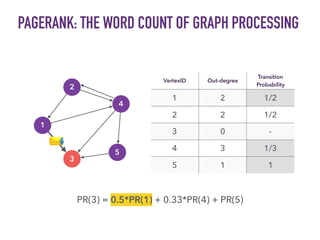
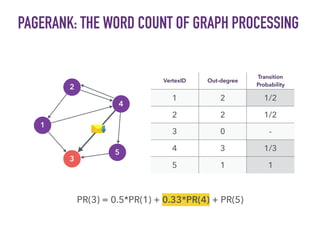
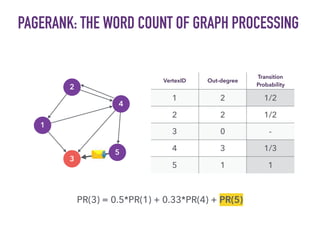
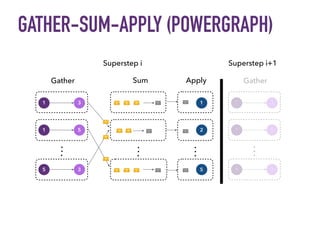
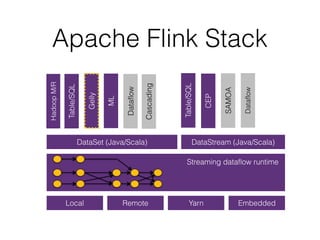
This document discusses batch and stream graph processing with Apache Flink. It provides an overview of distributed graph processing and Flink's graph processing APIs, Gelly for batch graph processing and Gelly-Stream for continuous graph processing on data streams. It describes how Gelly and Gelly-Stream allow for processing large and dynamic graphs in a distributed fashion using Flink's dataflow engine.

























































































![제 23회 보아즈(BOAZ) 빅데이터 컨퍼런스 - [MBOAX] : ABSA를 활용한 소비자 반응 분석 기반 운영 효율화 대시보드 설계](https://cdn.slidesharecdn.com/ss_thumbnails/3-1boaz23rdconferencemboax-260203102709-9d519923-thumbnail.jpg?width=640&height=640&fit=bounds)




