


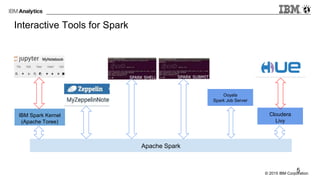
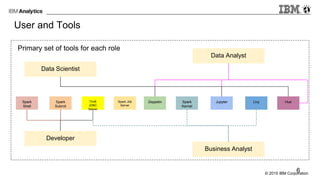





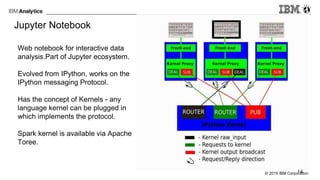
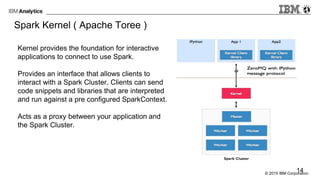
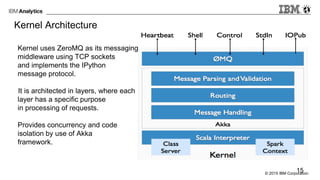


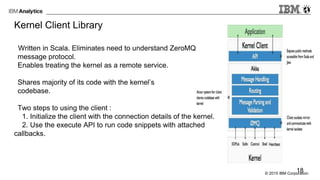
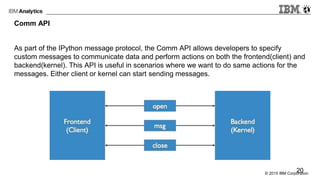
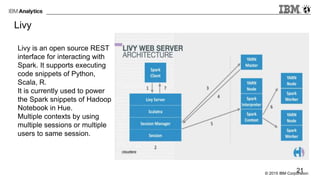


The document provides an overview of interactive analytics using Apache Spark, detailing user roles such as data scientists, data analysts, business analysts, and data engineers, along with their respective tools and tasks. It introduces various interactive tools, including Spark Shell, Apache Zeppelin, Jupyter Notebooks, and Livy, while explaining how these tools facilitate data processing and model building. Additionally, it covers the Spark Context as a core component for managing connections to Spark clusters and highlights the functionalities of Spark Job Server for job submission and management.























































































