Downloaded 18 times










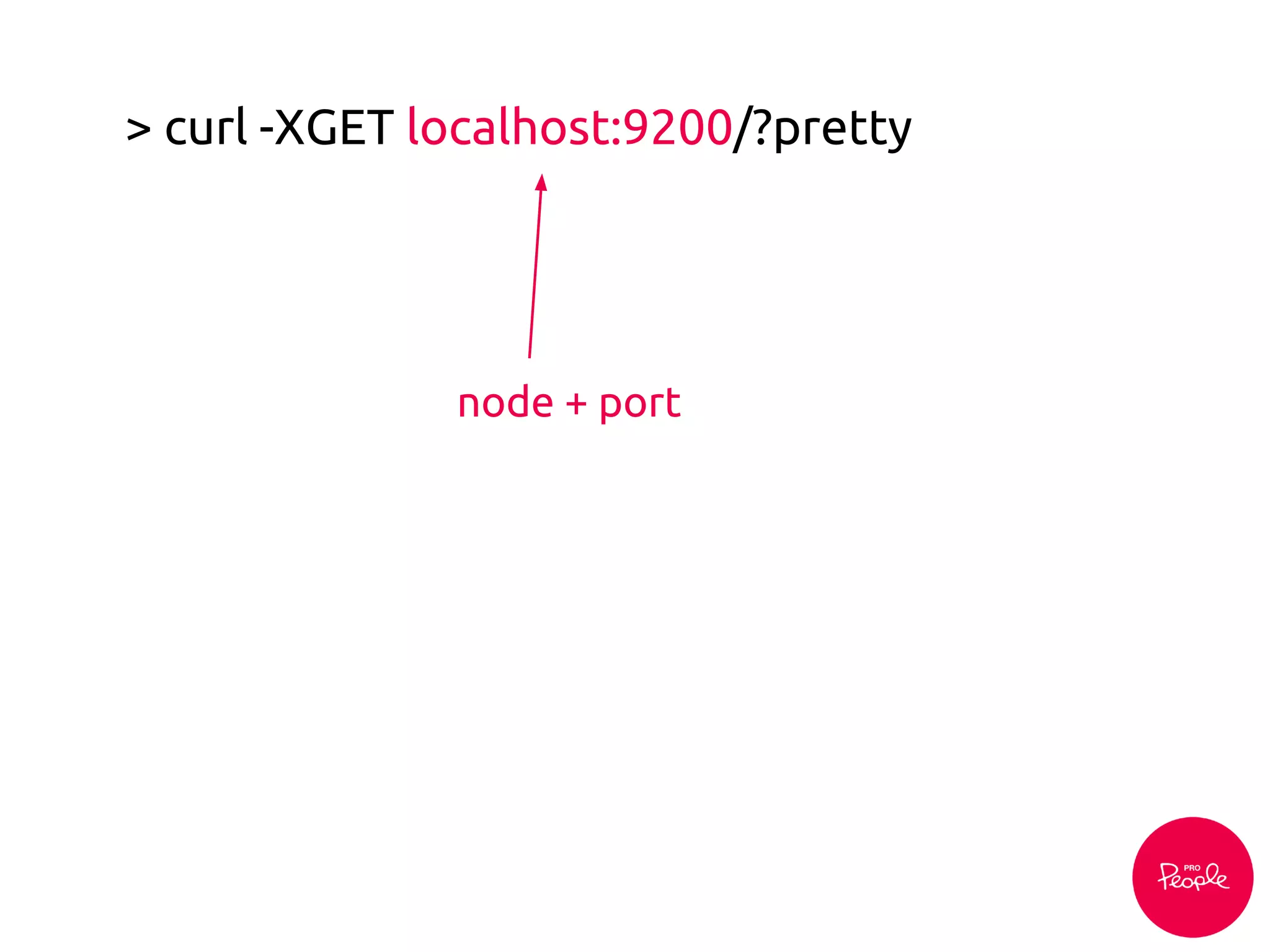

























![> PUT /myapp/node/1?version=1
{
"title": "hey boy"
}
# 409
> version conflict, current [2], provided [1]](https://image.slidesharecdn.com/elasticsearchmoldcamp2-140603093906-phpapp02/75/Real-time-search-in-Drupal-with-Elasticsearch-Moldcamp-38-2048.jpg)









![+title:awesome
+status:1
+created:[1369917354 TO *]](https://image.slidesharecdn.com/elasticsearchmoldcamp2-140603093906-phpapp02/75/Real-time-search-in-Drupal-with-Elasticsearch-Moldcamp-48-2048.jpg)
![?q=title:awesome%20%2Bcreated:
[1369917354%20TO%20*]%2Bstatus:1
+title:awesome
+status:1
+created:[1369917354 TO *]
The ugly encoding =)](https://image.slidesharecdn.com/elasticsearchmoldcamp2-140603093906-phpapp02/75/Real-time-search-in-Drupal-with-Elasticsearch-Moldcamp-49-2048.jpg)














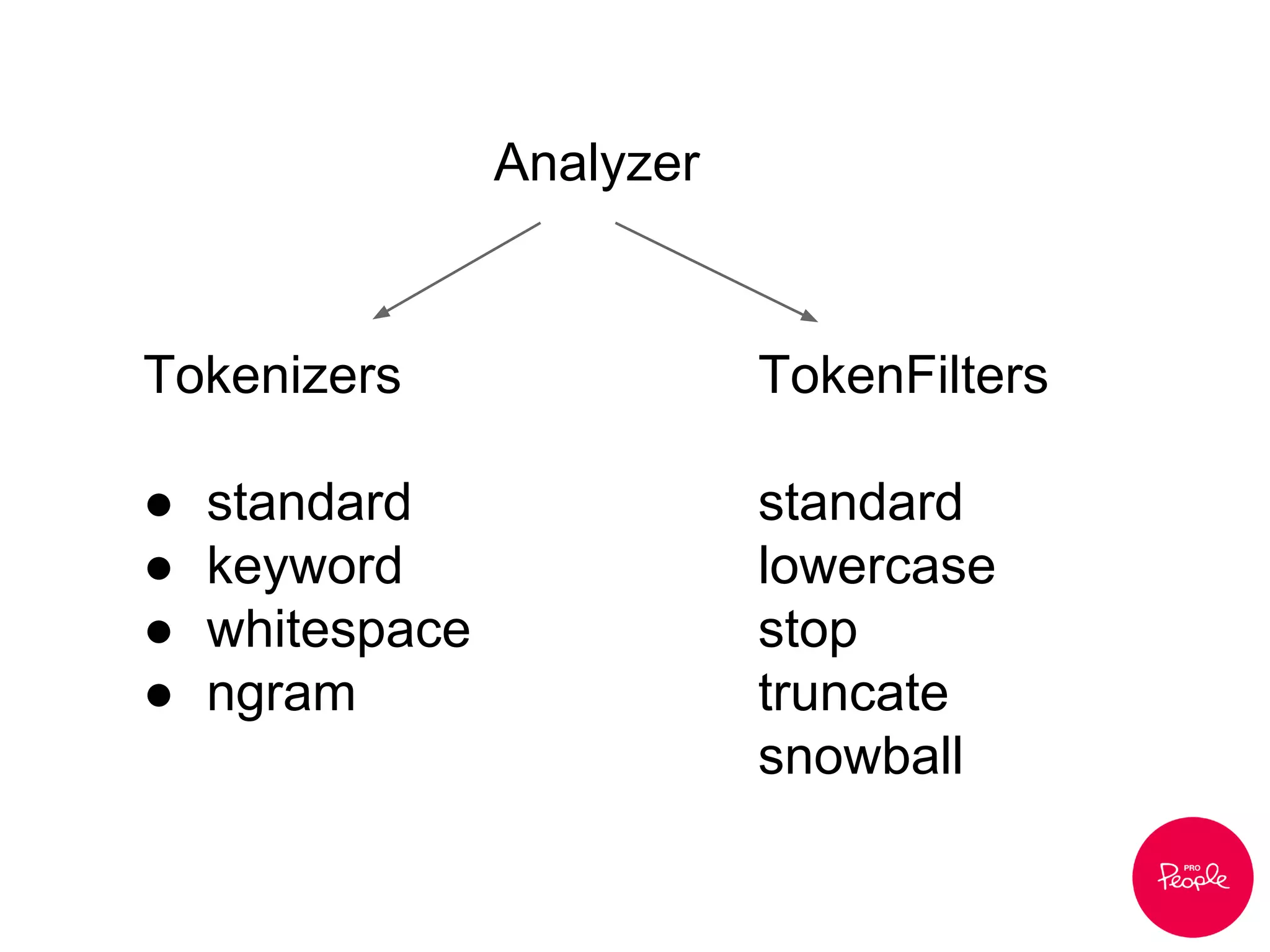
![> GET /_analyze?analyzer=standard -d
'this is a test baby'
{
"tokens" : [ {
"token" : "test",
"start_offset" : 10,
"end_offset" : 14,
"type" : "<ALPHANUM>",
"position" : 4
}, {
"token" : "baby",
"start_offset" : 15,
"end_offset" : 19,
"type" : "<ALPHANUM>",
"position" : 5
} ]
}](https://image.slidesharecdn.com/elasticsearchmoldcamp2-140603093906-phpapp02/75/Real-time-search-in-Drupal-with-Elasticsearch-Moldcamp-65-2048.jpg)
























This document provides an introduction to Elasticsearch, an open source, distributed real-time search and analytics engine. It discusses how to setup Elasticsearch in 2 steps by extracting the archive and running a command. It then demonstrates how to index and search data using Elasticsearch's RESTful API and JSON over HTTP. Examples are provided for indexing, getting, updating, deleting, and searching data as well as distributed, concurrency, and pagination features.

































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)








