Download as ODP, PPTX





![SET enable_[nestloop|hashagg|...] = [on|off]](https://image.slidesharecdn.com/pgwest2009-basicquerytuningprimer-101006155342-phpapp02/85/Basic-Query-Tuning-Primer-5-320.jpg)
![SET [random_page|...]_cost = [n]](https://image.slidesharecdn.com/pgwest2009-basicquerytuningprimer-101006155342-phpapp02/85/Basic-Query-Tuning-Primer-6-320.jpg)


![Occasionally helpful: gdb, dtrace, sar, iostat -x, etc. For Remedy: ANALYZE [table]](https://image.slidesharecdn.com/pgwest2009-basicquerytuningprimer-101006155342-phpapp02/85/Basic-Query-Tuning-Primer-9-320.jpg)
![ALTER TABLE [table] ALTER COLUMN [column] SET STATISTICS [n]](https://image.slidesharecdn.com/pgwest2009-basicquerytuningprimer-101006155342-phpapp02/85/Basic-Query-Tuning-Primer-10-320.jpg)
![SET default_statistics_target = [n], work_mem = [n]](https://image.slidesharecdn.com/pgwest2009-basicquerytuningprimer-101006155342-phpapp02/85/Basic-Query-Tuning-Primer-11-320.jpg)


![Rarely appropriate: SET [gucs], table-level autovac storage-params, denormalize columns, partition large table](https://image.slidesharecdn.com/pgwest2009-basicquerytuningprimer-101006155342-phpapp02/85/Basic-Query-Tuning-Primer-14-320.jpg)




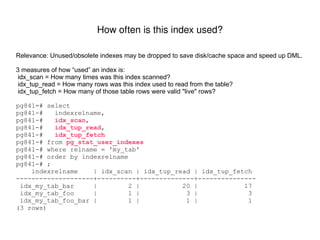









![Stale or missing statistics: When was my table last analyzed? Review the last time when each table was analyzed (either manually or by autovacuum). Use your knowledge of how and when your data changes to decide if the statistics are likely to be out of date. pg841=# select pg841-# schemaname, pg841-# relname, pg841-# last_analyze as last_manual, pg841-# last_autoanalyze as last_auto, pg841-# greatest (last_analyze, last_autoanalyze) pg841-# from pg841-# pg_stat_user_tables pg841-# where pg841-# relname = 'my_tab' pg841-# ; -[ RECORD 1 ]------------------------------ schemaname | public relname | my_tab last_manual | 2009-10-03 18:45:57.627593-07 last_auto | 2009-10-03 23:08:32.914092-07 greatest | 2009-10-03 23:08:32.914092-07](https://image.slidesharecdn.com/pgwest2009-basicquerytuningprimer-101006155342-phpapp02/85/Basic-Query-Tuning-Primer-29-320.jpg)
![Stale or missing statistics: How many rows does the optimizer think my table has? How are my columns' values distributed? Many bad plans are due to poor cardinality estimates for one or more nodes. Sometimes this is due to stale or missing statistics. For example, if a column was added or a significant percentage of rows were inserted, deleted, or modified, then the optimizer statistics should be refreshed. You can view the table-level optimizer statistics in pg_class: pg841=# select reltuples , relpages from pg_class where relname = 'my_tab' ; reltuples | relpages -----------+---------- 1000 | 5 (1 row) And the more detailed column-level optimizer statistics are shown in pg_stats: pg841=# select * from pg_stats where tablename = 'my_tab' and attname = 'bar' ; -[ RECORD 1 ]-----+--------------------------- schemaname | public tablename | my_tab attname | bar null_frac | 0 avg_width | 4 n_distinct | 13 most_common_vals | {1,2} most_common_freqs | {0.707,0.207} histogram_bounds | {0,3,4,5,6,7,8,9,10,11,12} correlation | 0.876659](https://image.slidesharecdn.com/pgwest2009-basicquerytuningprimer-101006155342-phpapp02/85/Basic-Query-Tuning-Primer-30-320.jpg)


The document provides a comprehensive guide on query tuning in PostgreSQL, detailing essential commands for diagnosis, execution plans, and optimization techniques. It explains the importance of various system and database settings that affect query performance, as well as the methodology for interpreting execution plans. Additionally, it discusses common pitfalls in query design and how to refine queries for improved efficiency.













![[Pgday.Seoul 2019] Citus를 이용한 분산 데이터베이스](https://cdn.slidesharecdn.com/ss_thumbnails/citus20191207studypgday-191218045308-thumbnail.jpg?width=640&height=640&fit=bounds)

































































