Download as PDF, PPTX






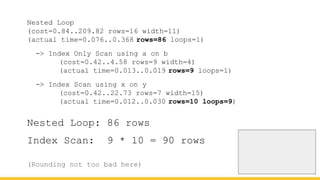

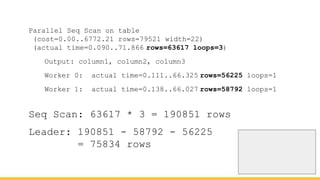

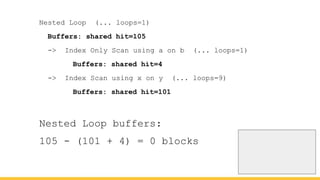

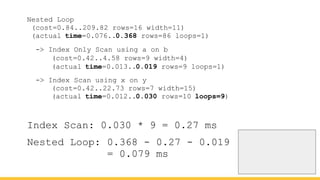

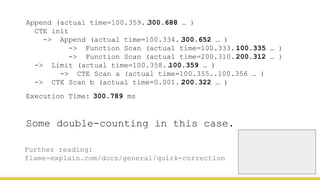


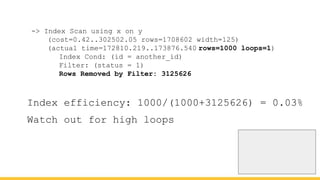

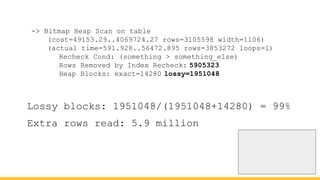

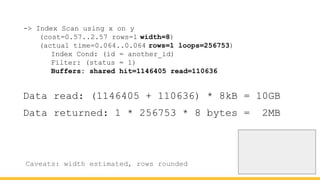

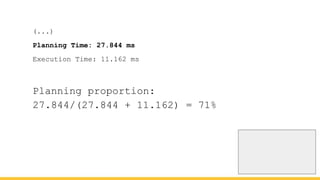

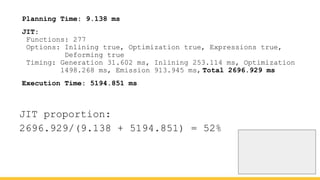






Michael Christofides discusses advanced techniques for interpreting PostgreSQL's EXPLAIN output, focusing on non-intuitive arithmetic and common issues such as loops, index scans, and inefficient data handling. He emphasizes the importance of understanding execution statistics, including costs, rows, and timings, while offering guidance on using tools for better analysis. The document concludes with recommendations for further reading and highlights the relevance of issues like filters, lossy bitmap scans, and performance optimizations.


















![[241]large scale search with polysemous codes](https://cdn.slidesharecdn.com/ss_thumbnails/241large-scalesearchwithpolysemouscodes-171017003327-thumbnail.jpg?width=640&height=640&fit=bounds)