Download as PDF, PPTX




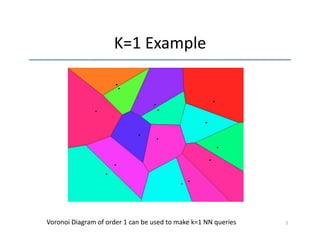





















The document discusses the use of PostgreSQL 9.1 for enhancing local search capabilities, especially through k-nearest neighbor (k-NN) queries and the application of distance metrics. It highlights the improvements in performance and indexing for geometric types and text similarity with the pg_trgm module. The presentation concludes with recommendations for further geometric support and potential applications of these indexing techniques.





























































