Download as PDF, PPTX




















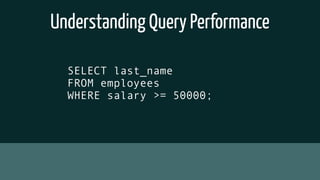
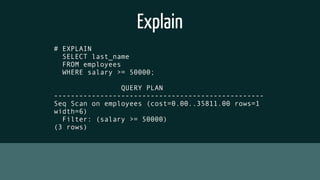
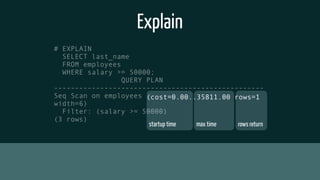



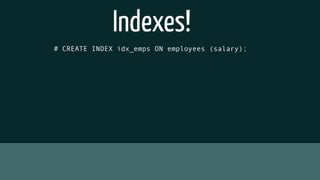
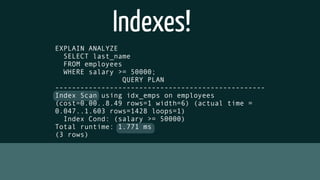


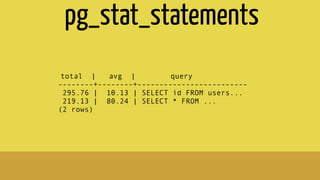











































The document provides insights into optimizing PostgreSQL performance, including various techniques like using conditional indexes, efficient query performance analysis, and cache utilization. It discusses different types of indexes and strategies for horizontal and vertical scaling, along with guidelines for performance metrics such as cache hit and index hit rates. Additionally, it emphasizes the importance of query execution plans and indexing strategies for enhancing database efficiency.





![【旧版】Oracle Gen 2 Exadata Cloud@Customer:サービス概要のご紹介 [2021年12月版]](https://cdn.slidesharecdn.com/ss_thumbnails/exadatacloudatcustomer20211208-211210071313-thumbnail.jpg?width=640&height=640&fit=bounds)

















![[Oracle DBA & Developer Day 2016] しばちょう先生の特別講義!!ストレージ管理のベストプラクティス ~ASMからExada...](https://cdn.slidesharecdn.com/ss_thumbnails/mktgdd2-3stragemanagementfordl2-200702092359-thumbnail.jpg?width=640&height=640&fit=bounds)






























































