Download as PDF, PPTX



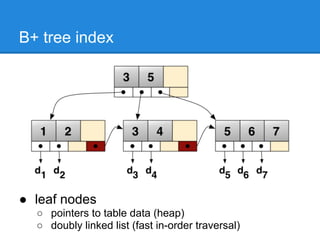



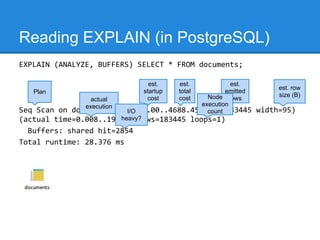
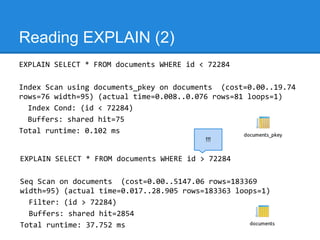


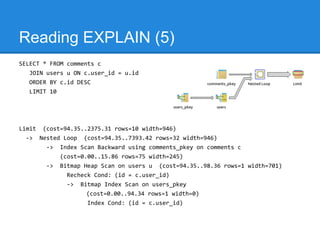













The document discusses query optimization techniques in SQL, emphasizing that the most efficient query is the one that is never executed. It outlines various strategies including using indexes, understanding access methods, and different join types to improve performance. It also presents practical examples illustrating how to analyze and optimize queries using PostgreSQL's EXPLAIN command.