Downloaded 147 times






















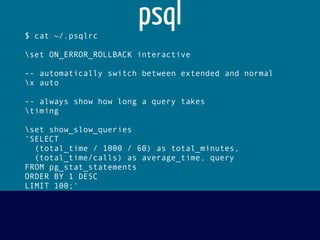

































![django-postgrespool
import dj_database_url
import django_postgrespool
DATABASE = { 'default': dj_database_url.config() }
DATABASES['default']['ENGINE'] = 'django_postgrespool'
SOUTH_DATABASE_ADAPTERS = {
'default': 'south.db.postgresql_psycopg2'
}](https://image.slidesharecdn.com/postgresperformanceforhumans-130829220803-phpapp02/85/Postgres-performance-for-humans-70-320.jpg)
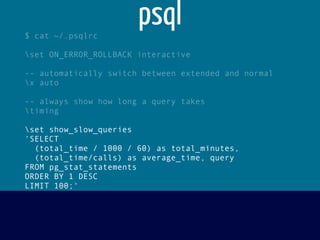
![django-postgrespool
import dj_database_url
import django_postgrespool
DATABASE = { 'default': dj_database_url.config() }
DATABASES['default']['ENGINE'] = 'django_postgrespool'
SOUTH_DATABASE_ADAPTERS = {
'default': 'south.db.postgresql_psycopg2'
}](https://image.slidesharecdn.com/postgresperformanceforhumans-130829220803-phpapp02/85/Postgres-performance-for-humans-71-320.jpg)

















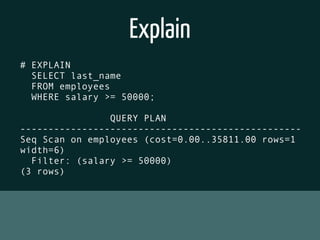
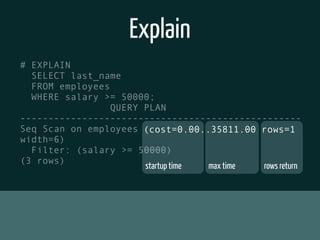
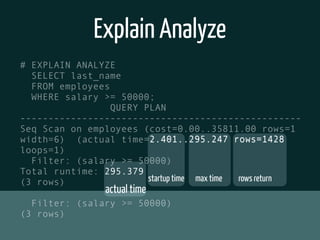
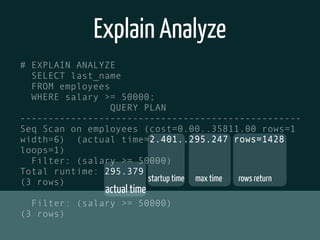
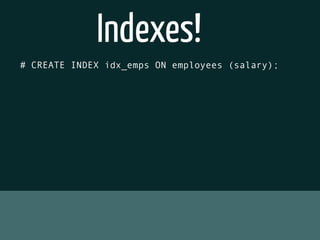
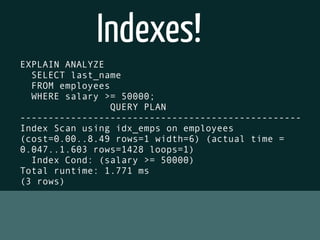
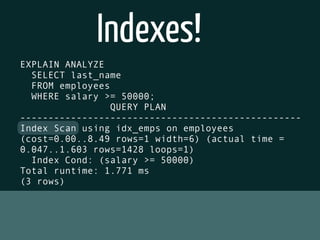
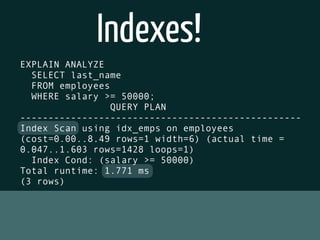
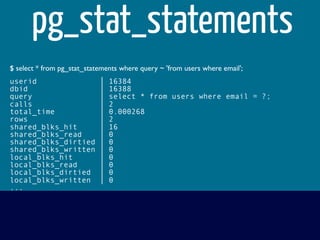
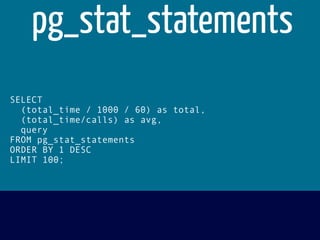
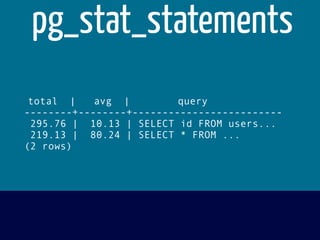
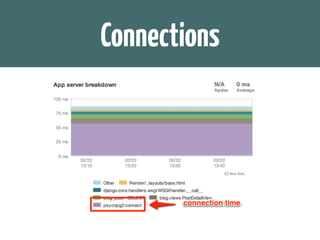
The document discusses various topics related to optimizing performance for PostgreSQL including: - Indexes and how to use EXPLAIN and EXPLAIN ANALYZE to analyze query performance. Conditional, functional and concurrent indexes are covered. - Connection pooling options for Django like django-postgrespool to improve connection management. - Replication options such as Slony, Bucardo, pgpool, WAL-E and Barman for high availability. - Backup strategies including logical backups with pg_dump and physical backups using base backups. When each approach is best to use.

















































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)




