The document presents a survey of PostgreSQL features by Alex Brasetvik, aiming to spark interest rather than provide exhaustive details. Key topics include key functions such as generate_series(), explain commands, and common table expressions (CTEs), alongside practical database management techniques. It also emphasizes the importance of understanding query execution for performance optimization.








![Please EXPLAIN
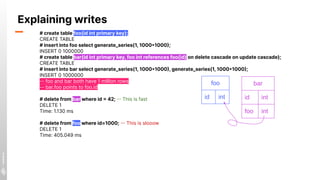
# explain select * from a where id=42;
-- QUERY PLAN --
Seq Scan on a (cost=0.00..2.25 rows=1 width=4)
Filter: (id = 42)
# explain analyze select * from a where id=42;
-- QUERY PLAN --
Seq Scan on a (cost=0.00..2.25 rows=1 width=4)
(actual time=0.034..0.041 rows=1 loops=1)
Filter: (id = 42)
Rows Removed by Filter: 99
Planning Time: 0.137 ms
Execution Time: 0.057 ms
● EXPLAIN [query goes here] shows the plan of the
statement without executing the query.
● EXPLAIN ANALYZE [query] executes the query while
profiling it, emitting the plan with profiling information.
Analyze = Execute](https://image.slidesharecdn.com/javazone-postgrescandothat-211209112333/85/Postgres-can-do-THAT-10-320.jpg)












![WITH a tiny graph
# select * from edges;
a | b | type
----------------+----------------+--------------
A | B | friend
B | C | friend
B | D | friend
root | A | parentOf
root | something-else | bff
something-else | A pump?! | !
A pump?! | D | tree-breaker
(7 rows)
# copy (select 'digraph G { ' ||
string_agg('"' || a || '" -> "' || b || '" [label="' || type || '"]; ', E'')
|| '}' from edges)
to program 'dot -Tsvg > /tmp/test.svg'; -- Pipe to Graphviz
COPY 1
# copy (select * from edges) to '/tmp/file.csv' with csv header; -- Make a CSV
COPY 7
# copy (select * from edges) to program 'pbcopy' with csv header;
-- CSV now on clipboard, paste straight to Google Sheets](https://image.slidesharecdn.com/javazone-postgrescandothat-211209112333/85/Postgres-can-do-THAT-25-320.jpg)








![# set work_mem to '64 kB'; -- force disk flushing with very low limit
# explain (analyze true, verbose true, buffers true)
with a_million_numbers as MATERIALIZED (
select * from a
)
select * from a_million_numbers where id in (42, 43);
-- QUERY PLAN --
CTE Scan on a_million_numbers (cost=14426.90..36928.92 rows=10001 width=4)
(actual time=0.048..1356.717 rows=4 loops=1)
Output: a_million_numbers.id
Filter: (a_million_numbers.id = ANY ('{42,43}'::integer[]))
Rows Removed by Filter: 1000086
Buffers: shared hit=4426, temp written=1709
CTE a_million_numbers
-> Seq Scan on public.a (cost=0.00..14426.90 rows=1000090 width=4) (actual
time=0.015..334.729 rows=1000090 loops=1)
Output: a.id
Buffers: shared hit=4426
Planning Time: 0.095 ms
Execution Time: 1358.238 ms
Force Postgres ≤11 behaviour
Low on memory, flushing to disk](https://image.slidesharecdn.com/javazone-postgrescandothat-211209112333/85/Postgres-can-do-THAT-34-320.jpg)
![# set work_mem to '64 kB'; -- force disk flushing with very low limit
# explain (analyze true, verbose true, buffers true)
with a_million_numbers as [NOT MATERIALIZED] (
select * from a
)
select * from a_million_numbers where id in (42, 43);
-- QUERY PLAN --
Index Only Scan using a_id_idx on a (cost=0.42..12.88 rows=2 width=4) (actual
time=0.020..0.026 rows=4 loops=1)
Index Cond: (id = ANY ('{42,43}'::integer[]))
Heap Fetches: 4
Planning Time: 0.108 ms
Execution Time: 0.043 ms -- vs 1358ms for materialized plan
Default Postgres ≥12 behaviour](https://image.slidesharecdn.com/javazone-postgrescandothat-211209112333/85/Postgres-can-do-THAT-35-320.jpg)
![# set work_mem to '64 kB'; -- force disk flushing with very low limit
# explain (analyze true, verbose true, buffers true)
with a_million_numbers as [NOT MATERIALIZED] (
select * from a where id in (42, 43)
)
select * from a_million_numbers where id in (42, 43)
-- QUERY PLAN --
Index Only Scan using a_id_idx on a (cost=0.42..12.88 rows=2 width=4) (actual
time=0.020..0.026 rows=4 loops=1)
Index Cond: (id = ANY ('{42,43}'::integer[]))
Heap Fetches: 4
Planning Time: 0.108 ms
Execution Time: 0.043 ms -- vs 1358ms for materialized plan
as if inlined](https://image.slidesharecdn.com/javazone-postgrescandothat-211209112333/85/Postgres-can-do-THAT-36-320.jpg)


![# with recursive graph_traversal(a, b, path, depth) as (
select a, b, ARRAY[a] as path, 0 as depth
from edges
where a='root'
union all
select edges.a, edges.b, path || ARRAY[edges.a], depth + 1
from edges join graph_traversal on(edges.a=graph_traversal.b)
-- Avoid looping forever if there's a cycle
where not(edges.a = ANY(path))
)
select * from graph_traversal
order by depth, a;
a | b | path | depth
----------------+----------------+----------------------------------+-------
root | A | {root} | 0
root | something-else | {root} | 0
A | B | {root,A} | 1
something-else | A pump?! | {root,something-else} | 1
A pump?! | D | {root,something-else,"A pump?!"} | 2
B | C | {root,A,B} | 2
B | D | {root,A,B} | 2
(7 rows)](https://image.slidesharecdn.com/javazone-postgrescandothat-211209112333/85/Postgres-can-do-THAT-39-320.jpg)
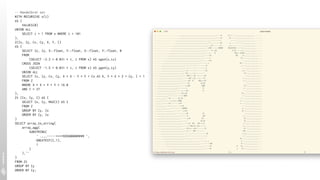

![pg_stat_activity
# select * from pg_stat_activity where state='idle';
-[ RECORD 1 ]----+------------------------------------------------
datid | 26211311
datname | sample
pid | 5291
usesysid | 16384
usename | alex
application_name | psql
client_addr |
client_hostname |
client_port | -1
backend_start | 2021-06-14 16:11:47.491729+02
xact_start |
query_start | 2021-06-14 16:34:41.027633+02
state_change | 2021-06-14 16:34:41.02857+02
wait_event_type | Client
wait_event | ClientRead
state | idle
backend_xid |
backend_xmin |
query | delete from person where is_crazy returning id;
backend_type | client backend](https://image.slidesharecdn.com/javazone-postgrescandothat-211209112333/85/Postgres-can-do-THAT-42-320.jpg)
![pg_stat_activity
# select * from pg_stat_activity where state='idle';
-[ RECORD 1 ]----+------------------------------------------------
datid | 26211311
datname | sample
pid | 5291
usesysid | 16384
usename | alex
application_name | psql
client_addr |
client_hostname |
client_port | -1
backend_start | 2021-06-14 16:11:47.491729+02
xact_start |
query_start | 2021-06-14 16:34:41.027633+02
state_change | 2021-06-14 16:34:41.02857+02
wait_event_type | Client
wait_event | ClientRead
state | idle
backend_xid |
backend_xmin |
query | delete from person where is_crazy returning id;
backend_type | client backend
# set application_name to 'my-app:some-role'
jdbc:postgresql://localhost:5435/MyDB?ApplicationName=MyApp
"idle in transaction" is typically bad,
especially if holding locks](https://image.slidesharecdn.com/javazone-postgrescandothat-211209112333/85/Postgres-can-do-THAT-43-320.jpg)

![pg_stat_statements
● pg_stat_statements extension for tracking continuous activity
● What are the most expensive queries over time?
● One of the most useful extensions!
# select * from pg_stat_statements order by total_time desc limit 1;
-[ RECORD 1 ]-------+------------------------------------------------------------
[…]
query | with a_million_numbers as materialized (select * from a)
select * from a_million_numbers where id in(42, 43)
calls | 2
total_time | 2500.088486
min_time | 1160.500207
max_time | 1339.588279
mean_time | 1250.044243
stddev_time | 89.544036
rows | 0
shared_blks_hit | 8852
[…]
temp_blks_written | 1710](https://image.slidesharecdn.com/javazone-postgrescandothat-211209112333/85/Postgres-can-do-THAT-45-320.jpg)
![pg_stat_statements
● Some ORMs/toolkits fill pg_stat_statements with junk:
○ WHERE id IN ($1, $2, …, $987)
○ WHERE id IN ($1, $2, …, $5432)
● Consider id = ANY($parameter_as_array)
# select * from pg_stat_statements order by total_time desc limit 1;
-[ RECORD 1 ]-------+------------------------------------------------------------
[…]
query | with a_million_numbers as materialized (select * from a)
select * from a_million_numbers where id in ($1, $2, $3, …)
calls | 2
total_time | 2500.088486
min_time | 1160.500207
max_time | 1339.588279
mean_time | 1250.044243
stddev_time | 89.544036
rows | 0
shared_blks_hit | 8852
[…]
temp_blks_written | 1710](https://image.slidesharecdn.com/javazone-postgrescandothat-211209112333/85/Postgres-can-do-THAT-46-320.jpg)

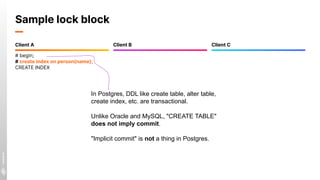
![Sample lock block
# begin;
# create index on person(name);
CREATE INDEX
-- Index creation needs a share lock
-- Block to see effects on others
# select pg_sleep(600);
# begin;
-- Reading is fine
# select * from person where id=3;
id | name | is_crazy
----+---------+----------
3 | Mallory | f
-- But cannot update:
# update person set name='Not Mallory'
where id=3;
-- We're BLOCKED by client A :(
-- Meanwhiles, checking the status:
# select query, wait_event_type from
pg_stat_activity where state='active' and
pid != pg_backend_pid();
-[ RECORD 1 ]---+----------------------
query | select pg_sleep(600);
wait_event_type | Timeout
-[ RECORD 2 ]---+----------------------
query | update person set
name='Not Mallory' where id=3;
wait_event_type | Lock
Client A Client B Client C
pg_sleep is useful to
artificially slow down
operations to observe
locking effects in dev](https://image.slidesharecdn.com/javazone-postgrescandothat-211209112333/85/Postgres-can-do-THAT-49-320.jpg)










![Range types
# create table intervals (
id int primary key,
start timestamptz,
"end" timestamptz
);
-- [Insert random intervals
-- happened here]
# create index on intervals
using
gist(tstzrange(start, "end"));
# explain analyze
select * from intervals
where tstzrange(start, "end") &&
tstzrange(now(), now() + interval '7 days');
-- QUERY PLAN --
Bitmap Heap Scan on intervals
(cost=1368.16..8447.01 rows=28354 width=20)
(actual time=46.379..80.761 rows=27837 loops=1)
Recheck Cond: (tstzrange(start, "end") &&
tstzrange(now(), (now() + '7 days'::interval)))
Heap Blocks: exact=6278
-> Bitmap Index Scan on intervals_tstzrange_idx
(cost=0.00..1361.08 rows=28354 width=0)
(actual time=44.309..44.309 rows=27837 loops=1)
Index Cond: (tstzrange(start, "end") &&
tstzrange(now(), (now() + '7 days'::interval)))
Planning Time: 0.118 ms
Execution Time: 56.151 ms](https://image.slidesharecdn.com/javazone-postgrescandothat-211209112333/85/Postgres-can-do-THAT-60-320.jpg)
![Exclusion constraints
● Define ranges that cannot overlap
● No two reservations of the same resource can overlap
● Exclusion constraints cannot be added "concurrently",
i.e. without write-locking the table.
# create table reservations (
room text,
start timestamptz,
"end" timestamptz,
constraint no_double_booking exclude using gist(
room with =,
tstzrange(start, "end") with &&
)
);
# insert into reservations values
('zelda', '2021-06-15', '2021-06-16'),
('zelda', '2021-06-17', '2021-06-18'),
('portal', '2021-06-01', '2021-07-01');
INSERT 0 3
# insert into reservations values
('zelda', '2021-06-14', '2021-06-16');
ERROR: conflicting key value violates exclusion
constraint "no_double_booking"
DETAIL: [omitted]](https://image.slidesharecdn.com/javazone-postgrescandothat-211209112333/85/Postgres-can-do-THAT-61-320.jpg)
![Exclusion constraints
● Define constraint that all elements must be the same
○ "Exclude dissimilar"
● Example:
○ Don't put humans and lions in the same cage at
the same time
# create table cages (
cage text,
animal text,
start timestamptz,
"end" timestamptz,
constraint just_same_animals exclude using gist(
cage with =,
animal with !=,
tstzrange(start, "end") with &&
)
);
# insert into cages values
('cellar', 'human', '2021-06-15', '2021-06-16'),
('bedroom', 'lion', '2021-06-15', '2021-06-16'),
('cellar', 'human', '2021-06-01', '2021-07-01');
INSERT 0 3
# insert into cages values
('bedroom', 'human', '2021-06-14', '2021-06-16');
ERROR: conflicting key value violates exclusion
constraint "just_same_animals"
DETAIL: [omitted]](https://image.slidesharecdn.com/javazone-postgrescandothat-211209112333/85/Postgres-can-do-THAT-62-320.jpg)

![Upsert
● INSERT can take an ON CONFLICT
● Given a conflict, either
○ DO NOTHING
○ DO UPDATE SET … [ WHERE … ]
# create table users (
user_id bigint primary key,
username text not null,
name text
);
create unique index on users(lower(username));
insert into users values
(1, 'alex', 'Alex'),
(2, 'bob', 'Bob');
# prepare sample_upsert as
insert into users values ($1, $2, $3)
on conflict(user_id)
do update set
username=excluded.username,
name=excluded.name
where
row(users.username, users.name)
is distinct from
row(excluded.username, excluded.name)
returning *;
# execute sample_upsert(1, 'alex', 'AlexB');
user_id | username | name
---------+----------+-------
1 | alex | AlexB
-- Repeat the same, then what?
# execute sample_upsert(1, 'alex', 'AlexB');
user_id | username | name
---------+----------+------
(0 rows)](https://image.slidesharecdn.com/javazone-postgrescandothat-211209112333/85/Postgres-can-do-THAT-64-320.jpg)
![Upsert
● ON CONFLICT DO NOTHING does not return data
# prepare fixed_upsert as
with maybe_upserted as (
insert into users values ($1, $2, $3)
on conflict(user_id)
[ … same as previous …]
returning *
)
select * from maybe_upserted
union all
select * from users where user_id = $1
limit 1;
# execute fixed_upsert(1, 'alex', 'AlexB');
user_id | username | name
---------+----------+-------
1 | alex | AlexB
-- Repeat the same, then what?
# execute fixed_upsert(1, 'alex', 'AlexB');
user_id | username | name
---------+----------+-------
1 | alex | AlexB](https://image.slidesharecdn.com/javazone-postgrescandothat-211209112333/85/Postgres-can-do-THAT-65-320.jpg)
![Upsert
● ON CONFLICT DO NOTHING does not return data
# prepare fixed_upsert as
with maybe_upserted as (
insert into users values ($1, $2, $3)
on conflict(user_id)
[ … same as previous …]
returning *
)
select * from maybe_upserted
union all
select * from users where user_id = $1
limit 1;
-- (note: union all for this trick)
# explain analyze
execute fixed_upsert(1, 'alex', 'Changed Name');
QUERY PLAN
---------------------------------------------------
Limit (..) (actual ...)
CTE maybe_upserted
-> Insert on users users_1 (...)
Conflict Resolution: UPDATE
Conflict Arbiter Indexes: users_pkey
Conflict Filter: ([…snip…])
Tuples Inserted: 0
Conflicting Tuples: 1
-> Result (...)
-> Append (...) -- (this is UNION ALL)
-> CTE Scan on maybe_upserted (...)
-> Index Scan using users_pkey on users
(...) (never executed)
Index Cond: (user_id = '1'::bigint)
Planning Time: 0.170 ms
Execution Time: 0.082 ms](https://image.slidesharecdn.com/javazone-postgrescandothat-211209112333/85/Postgres-can-do-THAT-66-320.jpg)

![JSON
● jsonb types, functions and aggregates
● Validates conformity only
○ Not a replacement for proper schemas!
● Use with care
○ Not a replacement for proper schemas! :)
# create table metadata (
user_id int,
key text,
metadata jsonb
);
# insert into metadata values
(1, 'settings', '{"foo": "bar"}'),
(1, 'searches', '["where", "what"]');
# select user_id, jsonb_agg(metadata)
from metadata group by 1;
user_id | jsonb_agg
---------+-------------------------------------
1 | [{"foo": "bar"}, ["where", "what"]]
# select user_id, jsonb_object_agg(key, metadata)
from metadata group by 1;
user_id | jsonb_object_agg
---------+------------------------------------------
1 | {"searches": ["where", "what"],
"settings": {"foo": "bar"}}](https://image.slidesharecdn.com/javazone-postgrescandothat-211209112333/85/Postgres-can-do-THAT-68-320.jpg)
![JSON object graphs
● Compose complete JSON object graphs via
LATERAL joins.
● Does not require the rows to have JSON types
● LATERAL is a bit like "for each"
○ The subquery gets to reference the row
● GraphQL-implementations on top of Postgres do
this (e.g. Hasura, Postgraphile)
# select * from users join metadata using(user_id);
user_id | username | key | metadata
---------+----------+----------+-------------------
1 | alex | settings | {"foo": "bar"}
1 | alex | searches | ["where", "what"]
# select jsonb_build_object(
'username', username,
'metadata', aggregated_metadata
) as user_object
from users
left join lateral ( -- For each user:
select jsonb_object_agg(key, metadata) as metadata from metadata
where metadata.user_id=users.user_id
) as aggregated_metadata on true;
user_object
--------------------------
{
"metadata": {
"searches": [
"where",
"what"
],
"settings": {
"foo": "bar"
}
},
"username": "alex"
}](https://image.slidesharecdn.com/javazone-postgrescandothat-211209112333/85/Postgres-can-do-THAT-69-320.jpg)
![Upserting object graphs
● Convert JSON object graphs to records via
LATERAL joins
● Upsert objects to different tables with a single
writable WITH-query
# create table users (
user_id bigint generated by default as identity primary key,
username text unique not null,
name text
);
# create table user_settings (
user_id bigint primary key references users(user_id),
settings jsonb not null
);
-- TODO: Define 'upsert' query that either creates or patches
-- across multiple tables with a single parameter
# execute upsert('[
{
"user": {"username": "alex", "name": "Alex"},
"settings": {"foo": "bar"}
},
{
"user": {"username": "mallory", "name": "Mallory"}
}
]');
# execute upsert('[
{
"user": {"username": "alex", "name": "AlexB"}
},
{
"user": {"username": "mallory", "name": "Mallory"},
"settings": {"bar": "baz"}
}
]');](https://image.slidesharecdn.com/javazone-postgrescandothat-211209112333/85/Postgres-can-do-THAT-70-320.jpg)
![# prepare upsert as
with records as (
select * from jsonb_to_recordset($1::jsonb)
as _("user" jsonb, "settings" jsonb)
), maybe_upserted_users as (
insert into users (username, name)
select username, name
from records
join lateral
jsonb_populate_record(null::users, records.user)
on(true)
on conflict (username) do -- insert or update
update set
username=excluded.username,
name=coalesce(excluded.name, users.name)
where
row(users.username, users.name) is distinct from
row(excluded.username, excluded.name)
returning *
)
select * from maybe_upserted_users;
# execute upsert('[...]');
user_id | username | name
---------+----------+---------
1 | alex | Alex
2 | mallory | Mallory
# create table users (
user_id bigint ... primary key,
username text unique not null,
name text
);
# create table user_settings (
user_id bigint primary key
references users(user_id),
settings jsonb not null
);
# execute upsert('[
{
"user": {"username": "alex",
"name": "Alex"},
"settings": {"foo": "bar"}
},
{
"user": {"username": "mallory",
"name": "Mallory"}
}
]');](https://image.slidesharecdn.com/javazone-postgrescandothat-211209112333/85/Postgres-can-do-THAT-71-320.jpg)
![# prepare upsert as
with records as (
select * from jsonb_to_recordset($1::jsonb)
as _("user" jsonb, "settings" jsonb)
), maybe_upserted_users as (
insert into users (username, name)
select username, name
from records
join lateral
jsonb_populate_record(null::users, records.user)
on(true)
on conflict (username) do -- insert or update
update set
username=excluded.username,
name=coalesce(excluded.name, users.name)
where
row(users.username, users.name) is distinct from
row(excluded.username, excluded.name)
returning *
)
select * from maybe_upserted_users;
# execute upsert('[
{
"user": {"username": "alex",
"name": "Alex"},
"settings": {"foo": "bar"}
},
{
"user": {"username": "mallory",
"name": "Mallory"}
}
]');
user_id | username | name
---------+----------+---------
1 | alex | Alex
2 | mallory | Mallory
-- On conflict's WHERE condition makes nothing be returned:
# execute upsert('[...]');
user_id | username | name
---------+----------+------
(0 rows)](https://image.slidesharecdn.com/javazone-postgrescandothat-211209112333/85/Postgres-can-do-THAT-72-320.jpg)
![# prepare upsert as
with records as (
select * from jsonb_to_recordset($1::jsonb)
as _("user" jsonb, "settings" jsonb)
), maybe_upserted_users as (
insert into users (username, name)
select username, name
from records
join lateral
jsonb_populate_record(null::users, records.user)
on(true)
on conflict (username) do -- insert or update
update set
username=excluded.username,
name=coalesce(excluded.name, users.name)
where
row(users.username, users.name) is distinct from
row(excluded.username, excluded.name)
returning *
), all_users as (
...
)
select * from all_users
all_users as (
select * from maybe_upserted_users
union all
select * from users where username in (
select "user" ->> 'username' from records
except all
select username from maybe_upserted_users
)
)
-- We now get all users: created or updated or neither
# execute upsert('[...]');
user_id | username | name
---------+----------+---------
1 | alex | Alex
2 | mallory | Mallory
# execute upsert('[...]');
user_id | username | name
---------+----------+---------
1 | alex | Alex
2 | mallory | Mallory](https://image.slidesharecdn.com/javazone-postgrescandothat-211209112333/85/Postgres-can-do-THAT-73-320.jpg)
![# prepare upsert as
with records as (
...
), maybe_upserted_users as (
...
), all_users as (
...
), updated_settings as (
insert into user_settings
select user_id, settings
from all_users
join records on (records.user ->> 'username' = username)
where settings is not null
on conflict(user_id) do
update set
settings=excluded.settings
where
user_settings.settings is distinct from
excluded.settings
)
select username, user_id from all_users;
# execute upsert('[
{
"user": {"username": "alex",
"name": "Alex"},
"settings": {"foo": "bar"}
},
{
"user": {"username": "mallory",
"name": "Mallory"}
}
]');
username | user_id
----------+---------
alex | 1
mallory | 2
# select * from user_settings;
user_id | settings
---------+----------------
1 | {"foo": "bar"}](https://image.slidesharecdn.com/javazone-postgrescandothat-211209112333/85/Postgres-can-do-THAT-74-320.jpg)


















































