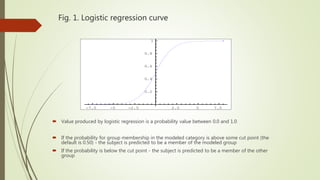
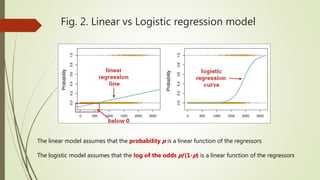
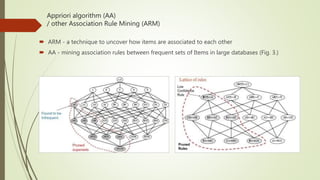
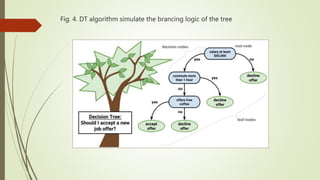
This document provides an overview of various data mining methods that are commonly used in health science and biomedical informatics. It discusses techniques such as logistic regression, support vector machines, association rule mining, decision trees, neural networks, and more. It also compares linear regression to logistic regression, describes how support vector machines work, and explains algorithms like Apriori for association rule mining and decision trees. Examples and figures are included to illustrate key concepts.


































































































![ONFH[AVN HIP] -TRIPLE REGIME -A NOVAL SURGICAL CONCEPT .pptx](https://cdn.slidesharecdn.com/ss_thumbnails/onfhavnhip2026koaconcalicutdrgokuldevdrmashraf-260210064517-213ec005-thumbnail.jpg?width=640&height=640&fit=bounds)









![PERI-PROSTHETIC FRACTURE NAIL-PLATE CONSTRUCT [NPC].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/drarunkumardrmohamedashrafperiprostheticfrasturenail-plateconstructnpc-260209164459-7e9d15a1-thumbnail.jpg?width=640&height=640&fit=bounds)




