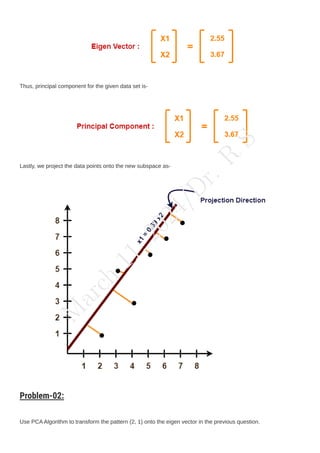
The document outlines the syllabus for a data analytics course, detailing five units covering data analysis concepts, techniques, and frameworks, including classification, regression, mining data streams, clustering, and visualization tools. It emphasizes the importance of practices like data cleaning, exploration, modeling, and decision-making in data analytics across various fields. Additionally, it discusses statistical techniques such as regression modeling and Bayesian inference, highlighting their applications in practical scenarios.










































![M
a
r
c
h
1
1
,
2
0
2
4
/
D
r
.
R
S
12 Reference
[1] https://www.jigsawacademy.com/blogs/hr-analytics/data-analytics-lifecycle/
[2] https://statacumen.com/teach/ADA1/ADA1_notes_F14.pdf
[3] https://www.youtube.com/watch?v=fDRa82lxzaU
[4] https://www.investopedia.com/terms/d/data-analytics.asp
[5] http://egyankosh.ac.in/bitstream/123456789/10935/1/Unit-2.pdf
[6] http://epgp.inflibnet.ac.in/epgpdata/uploads/epgp_content/computer_science/16._data_analytics/
03._evolution_of_analytical_scalability/et/9280_et_3_et.pdf
[7] https://bhavanakhivsara.files.wordpress.com/2018/06/data-science-and-big-data-analy-nieizv_
book.pdf
[8] https://www.researchgate.net/publication/317214679_Sentiment_Analysis_for_Effective_Stock_
Market_Prediction
[9] https://snscourseware.org/snscenew/files/1569681518.pdf
[10] http://csis.pace.edu/ctappert/cs816-19fall/books/2015DataScience&BigDataAnalytics.pdf
[11] https://www.youtube.com/watch?v=mccsmoh2_3c
[12] https://mentalmodels4life.net/2015/11/18/agile-data-science-applying-kanban-in-the-analytics-li
[13] https://www.sas.com/en_in/insights/big-data/what-is-big-data.html#:~:text=Big%20data%
20refers%20to%20data,around%20for%20a%20long%20time.
[14] https://www.javatpoint.com/big-data-characteristics
[15] Liu, S., Wang, M., Zhan, Y., & Shi, J. (2009). Daily work stress and alcohol use: Testing the cross-
level moderation effects of neuroticism and job involvement. Personnel Psychology,62(3), 575–597.
http://dx.doi.org/10.1111/j.1744-6570.2009.01149.x
********************
47](https://image.slidesharecdn.com/kit-601lecturenotes-unit-2-240523064644-03675e80/85/IT-601-Lecture-Notes-UNIT-2-pdf-Data-Analysis-47-320.jpg)


































![DWM- CO2_WAREHOUSE_MINING [Autosaved].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/dwm-co2-session-9autosaved-241214094013-10a39598-thumbnail.jpg?width=640&height=640&fit=bounds)




















































