This document provides a project report on building a descriptor-based support vector machine (SVM) for document categorization. It introduces SVMs and discusses how they were implemented for this project, including transforming data, scaling, using an RBF kernel, and training and assigning documents. The architecture of the SVM-based system is described, including training SVMs on descriptors and assigning descriptors to new documents. Experiments were conducted on a testbed using 5 descriptors, and recall, precision, and correct rate metrics were used to evaluate the results. In conclusion, the document demonstrates applying SVMs to automatically categorize documents based on their descriptors.




![The dictionary based approach currently used by DTIC relies on mapping of document
terms to DTIC thesaurus descriptions and is not efficient as it is requires continuous
update of the mapping table. Additionally, it suffers from the quality of descriptors that
are assigned using this approach. There is a need to improve this process to make it
efficient in terms of time and the quality of descriptors that are assigned to documents.
Support Vector Machine
Introduction
SVM (Support Vector Machine) was introduced by V. Vapnik in late 70s. It is widely
used in pattern recognition areas such as face detection, isolated handwriting digit
recognition, gene classification, and text categorization [11]. The goal of text
categorization is the classification of documents into a fixed number of predefined
categories. Each document can be in multiple, exactly one, or no category at all [8].
Text categorization with SVM eliminates the need for manual, difficult, time-consuming
classifying by learning classifiers from examples and performing the category
assignments automatically. This is a supervised learning problem
SVMs are a set of related supervised learning methods used for classification and
regression. They belong to a family of generalized linear classifiers. A special property of
SVMs is that they simultaneously minimize the empirical classification error and
maximize the geometric margin. Hence it is also known as the maximum margin
classifier. [8]
The main idea of Support Vector Machine is to find an optimal hyperplane to separate
two classes with the largest margin from pre-classified data [12]. The use of the
maximum-margin hyperplane is motivated by Vapnik Chervonenkis theory, which
provides a probabilistic test error bond that is minimized when the margin is maximized
[1].
SVM Model
SVM models can be divided into four distinct groups based on the error function:
(1) C-SVM classification
(2) nu-SVM classification
(3) epsilon-SVM regression
(4) nu-SVM regression
Compared to regular C-SVM, the formulation of nu-SVM is more complicated, so up to
now there have been no effective methods for solving large-scale nu-SVM [3]. We are
using C-SVM classification in our project. For C-SVM, training involves the
minimization of the error function:
Subject to the constraints:](https://image.slidesharecdn.com/reportdoc225/85/report-doc-4-320.jpg)
![Where C is the capacity constant or penalty parameter of the error function, w is the
vector of coefficients, b is a constant and is parameter for handling non separable data
(inputs). The index i labels the N training cases. Note that is the class labels and xi
is the independent variables. The kernel is used to transform data from the input
(independent) to the feature space [13].
SVM kernels:
Kernels area class of algorithms whose task is to detect and exploit complex patterns in
data (eg: by clustering, classifying, ranking, cleaning, etc. the data). Typical problems
are: how to represent complex patterns; and how to exclude spurious (unstable) patterns
(= over fitting). The first is a computational problem; the second a statistical problem.
[13].
The class of kernel methods implicitly defines the class of possible patterns by
introducing a notion of similarity between data, for example, similarity between
documents by length, topic, language, etc. Kernel methods exploit information about the
inner products between data items. Many standard algorithms can be rewritten so that
they only require inner products between data (inputs) . When a kernel is given there is
no need to specify what features of the data are being used. [13].
Kernel functions = inner products in some feature space (potentially very complex)
In SVM there are four common kernels:
• linear
• polynomial
• (RBF) radial basis function
• sigmoid
In general RBF is a reasonable first choice because the kernel matrix using sigmoid may
not be positive definite and in general it’s accuracy is not better than RBF[12], linear is a
special case of RBF, and polynomial may have numerical difficulties if a high degree is
used. In this implementation we use an RBF kernel whose kernel function is:
exp (γ||xy||²)
Kernel trick:
In machine learning, the kernel trick is a method for easily converting a linear classifier
algorithm into a non-linear one, by mapping the original observations into a higher-
dimensional non-linear space so that linear classification in the new space is equivalent to
non-linear classification in the original space [1]. Let’s look at this with an example.](https://image.slidesharecdn.com/reportdoc225/85/report-doc-5-320.jpg)
![Here we are interested in classifying data as a part of a machine-learning process. These
data points may not necessarily be points in but may be multidimensional points
[1]. We are interested in whether we can separate them by a n-1 dimensional hyperplane.
This is a typical form of linear classifier. Let us consider a two-class, linearly separable
classification problem as below:
Figure 1: Linear Classifier [12].
But not all classification problems are as simple as this.
Figure 2: Non Linear Input space [12].
In case of complex problems, where the input space is not linear, the solution is a
complex curve as below.
Figure 3:
Kernel Trick
[12].
Incase of such
non linear
input space, the data space is mapped into a linear feature space. This mapping of the
feature space is performed by a class of algorithms called Kernels.
Good Decision Boundary:
As discussed above theinput data points may not necessarily be points in but may be
multidimensional (computer science notation) points. We are interested in whether](https://image.slidesharecdn.com/reportdoc225/85/report-doc-6-320.jpg)
![we can separate them by a n-1 dimensional hyperplane [1]. This is a typical form of
linear classifier. There are many linear classifiers that might satisfy this property.
However, a given set of linear class data points may have more than one margin or
boundary that separates them. A Perceptron algorithm can be used to find these multiple
boundaries.
Class
1
Class
2
Figure 3: Good Decision Boundary
SVM solves this by finding the maximum separation (margin) between the two classes.
and is known as the maximum-margin hyper plane.
Figure 4: maximum margin hyper plane
SVM Implementation
The SVM implemented in this project follows the following steps [7]:](https://image.slidesharecdn.com/reportdoc225/85/report-doc-7-320.jpg)
![• Transform data to the format of an SVM software
• Conduct simple scaling/normalization on the data
• Consider the RBF kernel
• Find the best parameter C and Gamma
• Use the best parameter C and Gamma to train the training set
• Test
Transformation
There are many existing SVM library we can use, such as rainbow [9], LIBSVM etc.
LIBSVM is an integrated software for support vector classification, (C-SVC, nu-SVC),
regression (epsilon-SVR, nu-SVR) etc [5]. In this project we select LibSVM because of
the following reasons:
(1) cross validation for model selection
(2) different SVM formulations
(3) Java sources
The data format supported by LIBSVM consists of representing every documents as a
line of feature id pairs:
[label] [feature Id]:[feature Value] [feature Id]:[feature Value]……
The label is the class [0,1] or [-1,1] that the document belongs to .
The input here is the text file containing the articles or metadata of the images. LIBSVM
however takes the data files of the above described format. The input files are
transformed into the LIBSVM format by processing each document as follows. Every
document is scanned to pick up features (or key words that represent a document) and
every terms frequency (TF) and the inverse document frequency (IDF) is calculated.
These are then used to compute the weight of every term in the training set.
There are many tools such as lucene that calculate the TF and DF for a given document
and create its SVM data model. In this project I have developed my own API to calculate,
compute and create the svm data files (based on the required feature sets).
Scaling
The weighted frequencies are scaled to avoid attributes in greater numeric ranges
dominate those in smaller ranges.
RBF Kernel
In this project we use the RBF kernel as it is a simple model to start with. The number of
hyper parameters influences the complexity of model selection and Polynomial kernel
has more hyper parameters than the RBF kernel.
Approach](https://image.slidesharecdn.com/reportdoc225/85/report-doc-8-320.jpg)


![Assignment
Figure 3 illustrates the assignment phase. The input document is represented using TF
and DF as in the training phase. This document is presented to all the trained SVMs,
which in turn output an estimate in the range from 0 to 1 indicating how likely the
selected term maps to the test document. Based on a threshold, we can then assign .m.
thesaurus terms (descriptors) to the test document.
Experiments and Results
We use recall and precision metrics that are commonly used by the information
extraction and data mining communities. The general definition of recall and precision is:
Recall = Correct Answers / Total Possible Answers
Precision = Correct Answers / Answers Produced
To compute recall and precision typically one uses confusion matrix C [10], which is a K
X K matrix for a K-class classifier. In our case, it is a 5 by 5 matrix and an element of the
matrix indicates how many documents in class i have been classified as class j. For an
ideal classifier all off diagonal entries will be zeroes, and if there are n documents in a
class j.
c c Σ cii
= ii
Recall Σ c = ii
Precision Σ c Correct Rate = i
j
ij
j
ji Σ Σ cij
j i
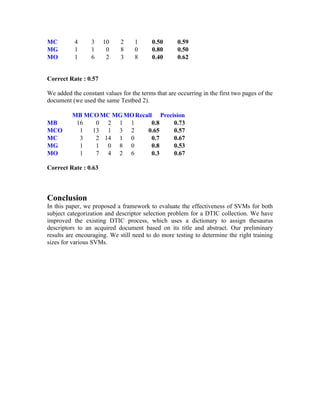
We created a testbed with various descriptors, below are the details of the testbed.
Testbed 1: In this case we took 5 descriptors (damage tolerance, fabrication, machine,
military history and tactical analysis).
Training size: 50 positive documents and 50 negative documents.](https://image.slidesharecdn.com/reportdoc225/85/report-doc-11-320.jpg)

![Reference
[1] Sebastiani, F (2002). .Machine learning in automated text categorization.. ACM
Computing Surveys. Vol. 34(1). pp. 1-47.
[2] Dumais, S. T., Platt, J., Heckerman, D., and Sahami, M. (1998). .Inductive learning
algorithms and representations for text categorization., In Proceedings of CIKM-98, 7 th
ACM International Conference on Information and Knowledge Management
(Washington, US, 1998), pp. 148.155.
[3] Joachims, T. (1998). .Text categorization with support vector machines: learning with
many relevant features., In Proceedings of ECML-98, 10th European Conference on
Machine Learning (Chemnitz, DE, 1998), pp. 137.142. [4] Reuters-21578 collection.
URL: http://www.research.att.com/~lewis/reuters21578.htm
[5] V. N. Vapnik. The nature of Statistical Learning Theory. Springer, Berlin, 1995.
[6] C.J.C. Burges. A tutorial on support vector machines for pattern recognition. Data
Mining and Knowledge Discovery, 2(2): 955-974, 1998.
[7] T. Joachims, Text Categorization with Suport Vector Machines: Learning with Many
Relevant Features. Proceedings of the European Conference on Machine Learning,
Springer, 1998.
[8] T. Joachims, Learning to Classify Text Using Support Vector Machines. Dissertation,
Kluwer, 2002.
[9] J.T. Kwok. Automated text categorization using support vector machine. In
Proceedings of the International Conference on Neural Information Processing,
Kitakyushu, Japan, Oct. 1998, pp. 347- 351.
[10]. Kohavi R and Provost F. Glossary of Terms. Editorial for the Special Issue on
Applications of Machine Learning and the Knowledge Discovery Process, Vol. 30, No.
2/3, February/March 1998.](https://image.slidesharecdn.com/reportdoc225/85/report-doc-14-320.jpg)









































![SVM[Support vector Machine] Machine learning](https://cdn.slidesharecdn.com/ss_thumbnails/svm-250403184638-1cd9afdb-thumbnail.jpg?width=640&height=640&fit=bounds)



































