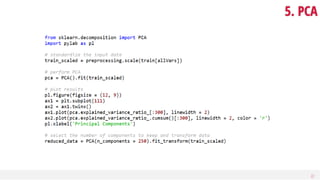
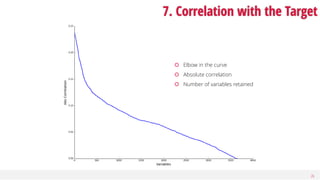
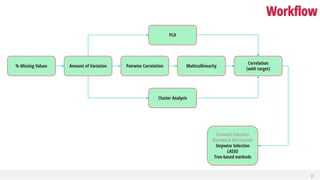
This document discusses dimensionality reduction, a vital process in machine learning that involves selecting a subset of features for model construction. It outlines various techniques such as principal component analysis, cluster analysis, and selection methods to manage the challenges of high-dimensional data and the curse of dimensionality. The guide emphasizes the importance of reducing redundancy and irrelevant features to enhance predictive power and model efficiency.





![8
Because…
True dimensionality <<< Observed dimensionality
The abundance of redundant and irrelevant features
Curse of dimensionality
With a fixed number of training samples, the predictive power reduces as the dimensionality increases.
[Hughes phenomenon]
With 𝑑 binary variables, the number of possible combinations is 𝑂(2 𝑑
).
Value of Analytics
Descriptive Diagnostic Predictive Prescriptive
Law of Parsimony [Occam’s Razor]
Other things being equal, simpler explanations are generally better than complex ones.
Overfitting
Execution time (Algorithm and data)
Hindsight Insight Foresight](https://image.slidesharecdn.com/dimreductiontechniquespydatadcoct2016-170626164019/85/Feature-Reduction-Techniques-8-320.jpg)












































































![[DSC Europe 25] Nikola Vasiljevic - Player segmentation by combat playstyles ...](https://cdn.slidesharecdn.com/ss_thumbnails/mnvbf0yvrwaqsipzrrv3-2-nikola-vasiljevic-player-segmentation-by-playstyles-in-action-shooter-games-260114111931-b4d766cd-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Slobodan Dolinic - Smart and Intelligent Green Region.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/0bribinjsp6ghwtvsvor-2-sigre-slobodan-dolinic-260115093812-c9c10e90-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Stefan Brankovic - #ResumeIsDead. AI-Powered Interviews and C...](https://cdn.slidesharecdn.com/ss_thumbnails/qnmbsv0xq3uysdrq3sev-2-stefan-brankovic-job-bolt-260114111931-a065aa3d-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Elena Menshikova - AI-Powered Operational Excellence: Revolut...](https://cdn.slidesharecdn.com/ss_thumbnails/es6nholbqy3zaao2c2yd-2-elena-menshikova-data-ai-in-decision-making-260115093812-4fba8b38-thumbnail.jpg?width=640&height=640&fit=bounds)

![[DSC Europe 25] Mijat Kustudic - Building Financial Intelligence with AI Agen...](https://cdn.slidesharecdn.com/ss_thumbnails/38y2lb5lse6wstegtvas-3-mijat-kustudic-building-financial-intelligence-with-ai-agents-260114111931-1a4783ce-thumbnail.jpg?width=640&height=640&fit=bounds)






