Downloaded 12 times




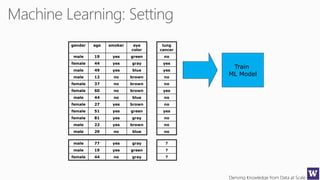


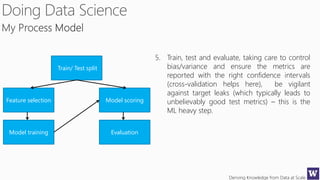








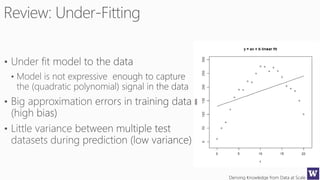













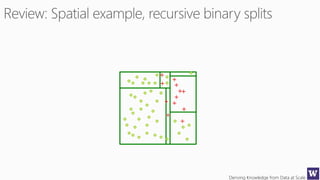



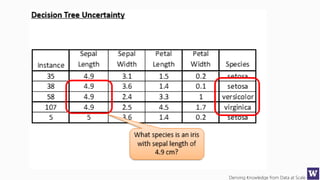















































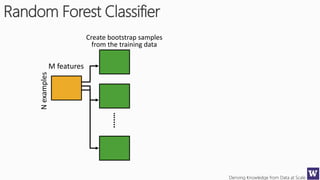

















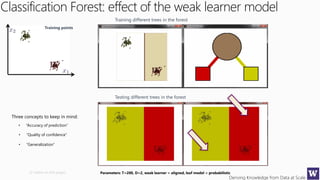







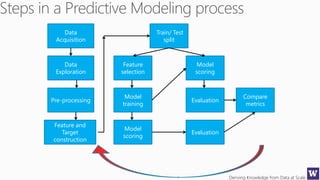



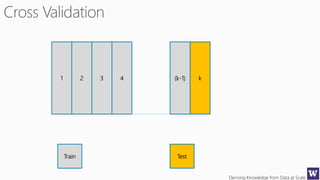















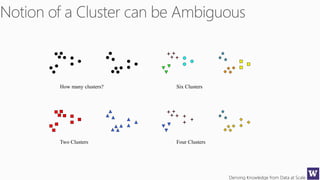















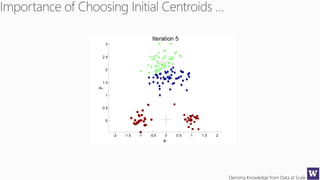








This document outlines an agenda for a data science boot camp covering various machine learning topics over several hours. The agenda includes discussions of decision trees, ensembles, random forests, data modelling, and clustering. It also provides examples of data leakage problems and discusses the importance of evaluating model performance. Homework assignments involve building models with Weka and identifying the minimum attributes needed to distinguish between red and white wines.















































































